文章目录
- 概述
- 使用场景
- 对比其他存储
- Kudu基本架构
- Kudu中的相关概念和机制
概述
Kudu是一个分布式列式存储引擎/系统,由Cloudera开源后捐献给Apache基金会很快成为顶级项目。用于对大规模数据快速读写的同时进行快速分析

官网
https://kudu.apache.org/
Kudu运行在一般的商用硬件上,支持水平扩展和高可用,集HDFS的顺序读和HBase的随机读于一身,同时具备高性能的随机写,以及很强大的可用性(单行事务,一致性协议),支持与Impala/spark计算引擎。

| 数据形态 | 存储 | 场景 | 局限性 |
|---|---|---|---|
| 静态数据 | HDFS(Parquet)+Hive/Impala | 高吞吐离线大数据分析 | 数据无法实现随机读写 |
| 动态数据 | HBase/Cassandra 作为存储 | 大数据随机读写 | 不适合高吞吐大数据离线分析 |
造成问题
1.数据过度冗余,数据需要存储多份以支撑多个应用,这样造成了存储等资源的浪费
2.架构复杂导致开发、运维、测试成本高,同时维护多套存储系统,架构复杂,开发、运维、测试成本相对较高
3. 数据不一致容易误解,多套数据由于程序bug或者其他原因很容易出现数据不一致的情况,往往会造成业务方的误解
为了解决上述问题业界做了很多尝试,例如HBase+Hive整合
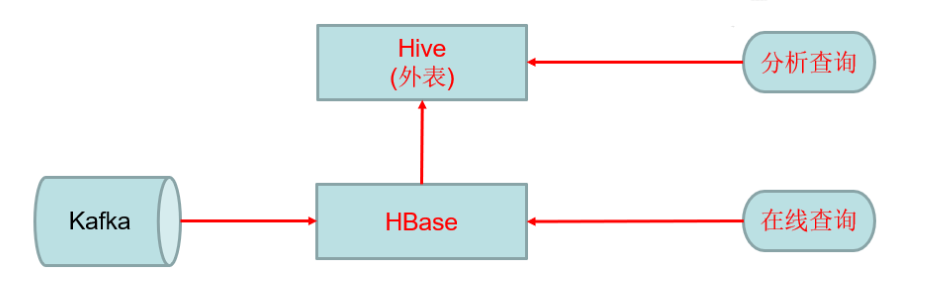
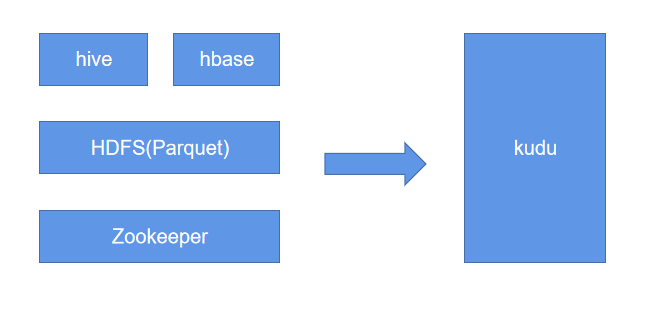
Kudu 是一个折中的产品,它平衡了随机读写和批量分析的性能,当然Kudu身上还有很多概念或者标签,有分布式文件系统(好比HDFS),有一致性算法(好比Zookeeper),有Table(好比Hive Table),有Tablet(好比Hive Table Partition),有列式存储(好比Parquet),有顺序和随机读取(好比HBase),所以看起来kudu是一个轻量级的 HDFS +Zookeeper + Hive + Parquet + HBase,除此之外,kudu还有自己的特点,快速写入+读取,使得
kudu+impala非常适合OLAP场景,尤其是Time-series场景
使用场景
1.实时数据更新
2.时间序列相关的应用(例如APM),海量历史数据查询(数据顺序扫描),必须非常快地返回关于单个实体的细粒度查询(随机读)。
3.实时预测模型的应用(机器学习),支持根据所有历史数据周期地更新模型。
对比其他存储
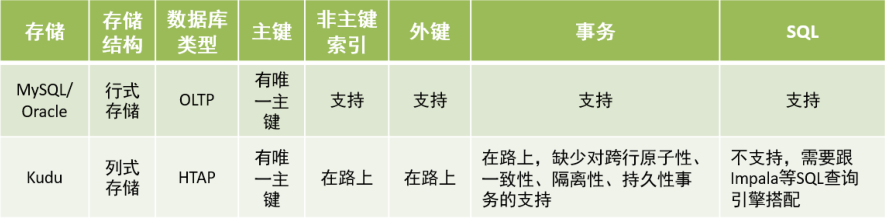
HTAP:类比OLAP,kudu可以与hive,impala,sparkSQL等OLAP SQL查询引擎结合
类比OLTP,kudu可以根据主键快速检索,实现对表分析查询连续不断写入数据
| 存储 | 大规模数据扫描(分析场景) | 随机读写 |
|---|---|---|
| HDFS | 全表扫描 | 不擅长随机读,不支持随机写 |
| HBase | 可以支持,性能差 | 随机读写,列式存储 |
| Kudu | 比hbase更擅长大规模数据扫描.接近HDFS上Parquet性能 | 擅长随机读写 |
Kudu基本架构
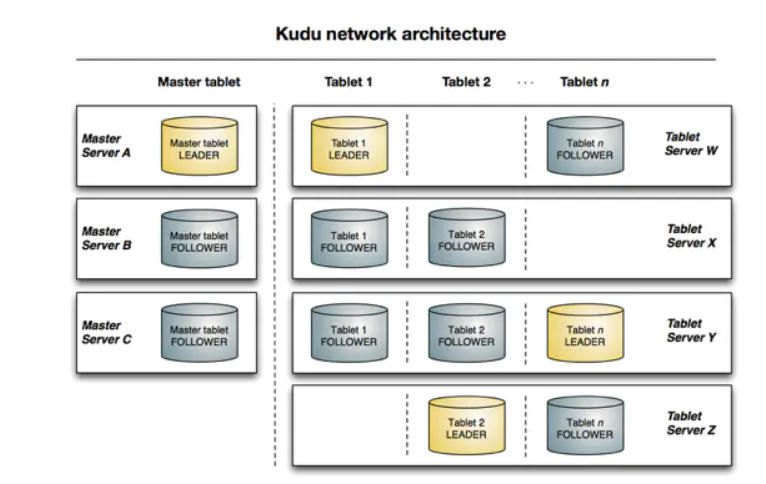
Kudu是典型的主从架构。一个Kudu集群由主节点即Master和若干个从节点即
Tablet Server组成。Master负责管理集群的元数据(类似于HBase Master),Tablet Server负责数据存储(类似HBase的RegionServer)。在生产环境,一般部署多个Master实现高可用(奇数个、典型的是3个),Tablet Server一般也是奇数个。
基本术语
Table(表)
Kudu中Table(表)的概念跟其他关系型数据库一样,table是数据存储在 Kudu 的位置。表具有schema(表结构)和全局有序的primary key(主键)。table被水平分成很多段,每个段称为Tablet。
Tablet
一个tablet 是 一张表table 连续的segment(片段),类似于HBase的region 或关系型数据库
partition(分区)。每个tablet存储着一定连续range的数据(key),且tablet两两间的range不会重叠。一张表的所有tablet包含了这张表的所有key空间。tablet 会冗余存储。放置到多个 tablet server上,并且在任何给定的时间点,其中一个副本被认为是leader tablet,其余的被认之为follower tablet。每个tablet都可以进行数据的读请求,但只有Leader tablet负责写数据请求
Tablet Server
Tablet server是Kudu集群中的从节点,负责数据存储,并提供数据读写服务。一个 Tablet server 存储了table表的tablet,向kudu client 提供读取数据服务。对于给定的tablet,一个tablet server 充当 leader,其他 tablet server 充当该 tablet 的 follower 副本。只有 leader服务写请求,然而 leader 或 followers 为每个服务提供读请求 。一个 tablet server可以服务多个 tablets ,并且一个 tablet 可以被多个 tablet servers 服务着。
Master
集群中的主节点,负责集群管理、元数据管理等功能,保持跟踪所有的tablets、tablet servers、catalog tables(目录表)和其它与集群相关的,metadata。在给定的时间点,只能有一个起作用的master(也就是 leader)
如果当前的leader消失,则选举出一个新的master,使用Raft协议来进行选举。master还协调客户端的metadata operations(元数据操作),例如,当创建新表时,客户端内部将请求发送给master。 master将新表的元数据写入catalog
table(目录表,元数据表),并协调在tablet server上创建tablet的过程。所有master的元数据都存储在一个tablet中,可以复制到所有其他候选的master。tablet server以设定的间隔向master发出心跳(默认值为每秒一次)。
Raft Consensus Algorithm
Kudu 使用 Raft consensus algorithm 作为确保常规 tablet 和 master 数据的容错性和一致性的手段。通过 Raft协议,tablet 的多个副本选举出 leader,它负责接受请求和复制数据写入到其他
follower副本。一旦写入的数据在大多数副本中持久化后,就会向客户确认。给定的一组N副本(通常为 3 或 5 个)能够接受最多(N - 1)/2 错误的副本的写入。
Catalog Table(目录表)
catalog table是Kudu 的元数据表。它存储有关tables和tablets的信息.catalog table(目录表)不能被直接读写,它只能通过客户端 API中公开的元数据操作访问。
catalog table存储以下两类元数据:
1、Tables:table schemas 表结构,locations 位置,states 状态
2、Tablets:现有tablet 的列表,每个 tablet 的副本所在哪些tablet server,tablet的当前状态以及开始和结束的keys(键)。
Kudu中的相关概念和机制
主键
类比关系型数据库的主键,Kudu基于主键重组和索引数据,没有二级键,没有二级索引,影响到数据存储在哪台服务器上,因此主键设计不好影响查询性能,通常还会导致热点问题,即大多数读或者写请求落在一台服务器上
分区
范围分区
哈希分区
多级分区(范围+哈希)
最后
以上就是瘦瘦朋友最近收集整理的关于KUDU(一)kudu概述的全部内容,更多相关KUDU(一)kudu概述内容请搜索靠谱客的其他文章。








发表评论 取消回复