import pandas as pd
import numpy as np
import random
df_credit = pd.read_csv("./train.csv")
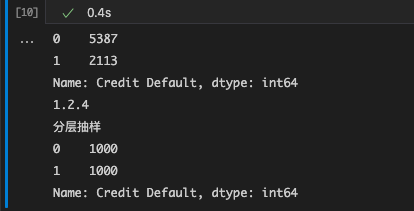
print(df_credit["Credit Default"].value_counts())
n_sample=1000
print(pd.__version__)
aa=df_credit.groupby('Credit Default').sample(n=n_sample,replace=True) ## 这个是分成抽样
print("分层抽样")
print(aa["Credit Default"].value_counts())
案例2
https://www.geeksforgeeks.org/stratified-sampling-in-pandas/
import pandas as pd
# Create a dictionary of students
students = {
'Name': ['Lisa', 'Kate', 'Ben', 'Kim', 'Josh',
'Alex', 'Evan', 'Greg', 'Sam', 'Ella'],
'ID': ['001', '002', '003', '004', '005', '006',
'007', '008', '009', '010'],
'Grade': ['A', 'A', 'C', 'B', 'B', 'B', 'C',
'A', 'A', 'A'],
'Category': [2, 3, 1, 3, 2, 3, 3, 1, 2, 1]
}
# Create dataframe from students dictionary
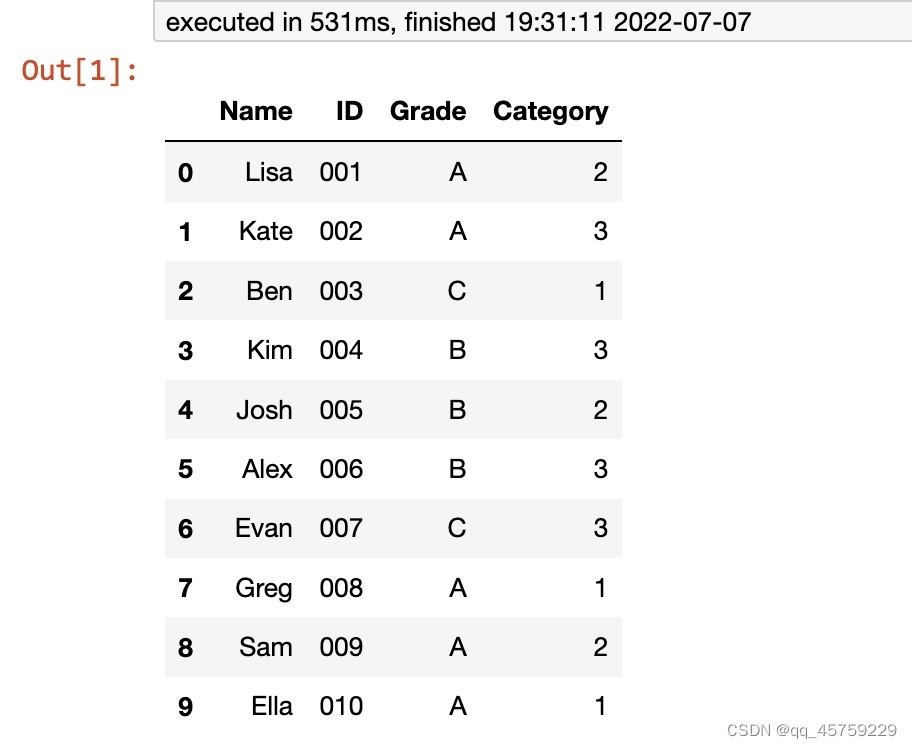
df = pd.DataFrame(students)
# view the dataframe
df
结果如下
等样本抽样
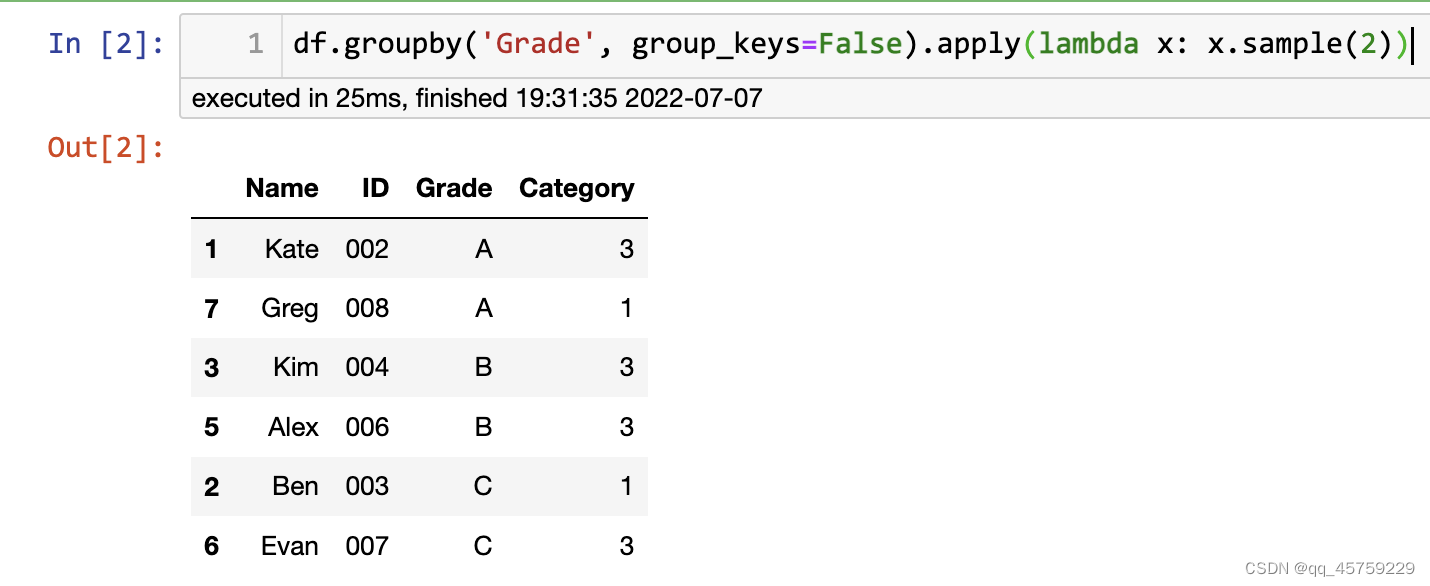
df.groupby('Grade', group_keys=False).apply(lambda x: x.sample(2))
结果如下
等比例抽样
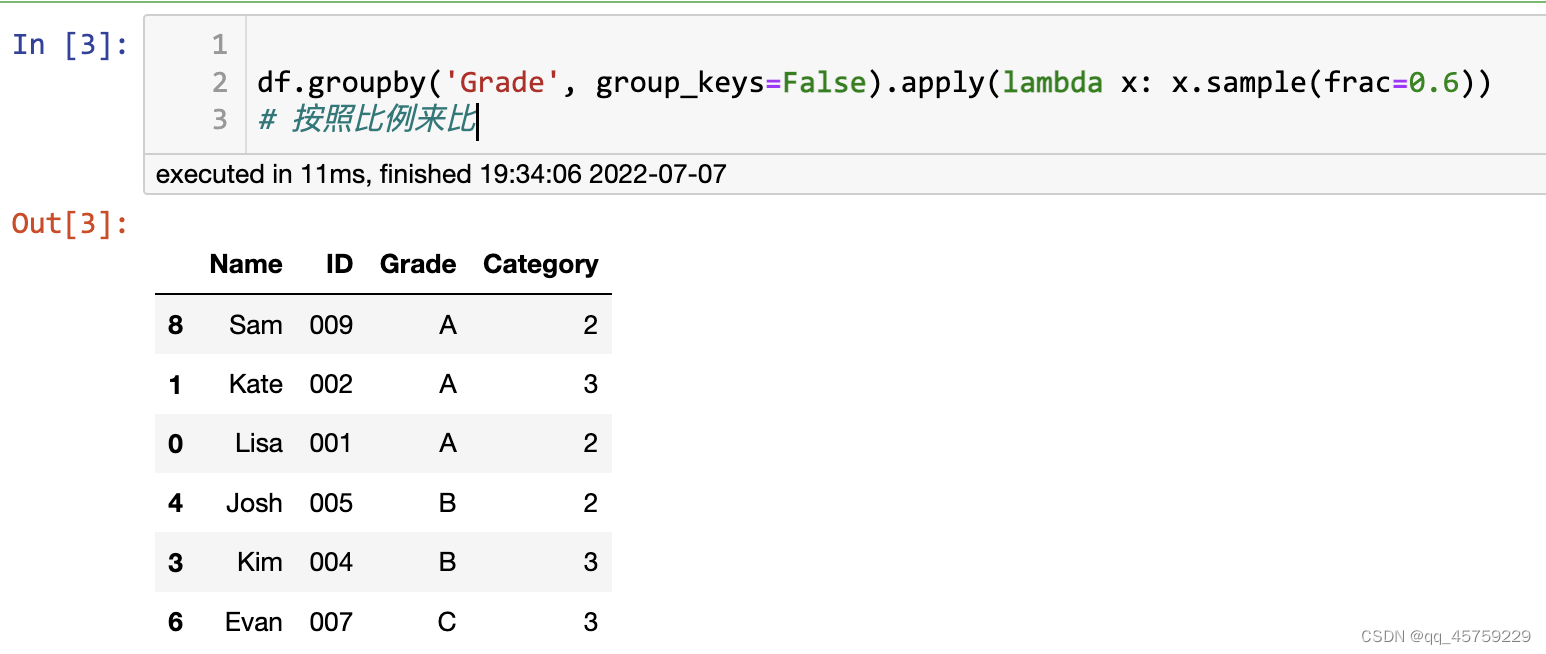
df.groupby('Grade', group_keys=False).apply(lambda x: x.sample(frac=0.6))
# 按照比例来比
分层抽样实现2
这里我也可以使用train_test_spilt进行实现
# get data and format
adata = sc.datasets.paul15()
# can try preprocessing here...
# sc.pp.recipe_zheng17(adata)
# create dictionary of label map
label_map = dict(enumerate(adata.obs["paul15_clusters"].cat.categories))
label_map
# extract of some of the most representative clusters for training/testing
clusters = [0, 1, 2, 3, 4, 5, 13, 14, 15, 16]
indices = adata.obs["paul15_clusters"].cat.codes.isin(clusters)
data, labels = adata.X[indices], adata.obs[indices]["paul15_clusters"].cat.codes.values
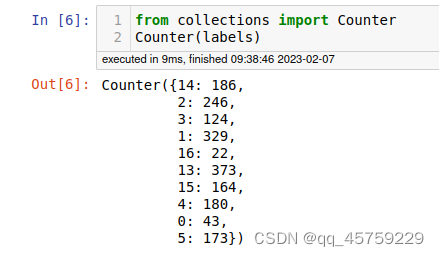
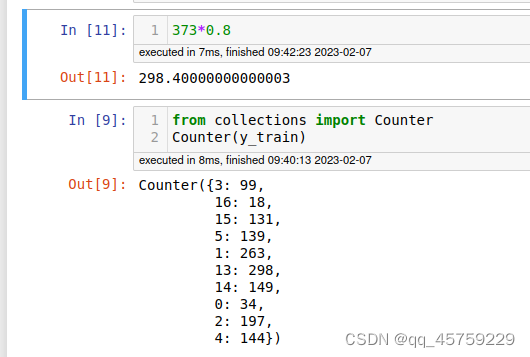
X_train, X_val, y_train, y_val = train_test_split(
data, labels, stratify=labels, test_size=0.2, random_state=77
)
最后
以上就是潇洒蜜蜂最近收集整理的关于python分层抽样案例2分层抽样实现2的全部内容,更多相关python分层抽样案例2分层抽样实现2内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复