import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['STFangsong']
plt.rcParams['axes.unicode_minus'] = False
%config InlineBackend.figure_format = 'svg'
cut 使用
df = pd.read_csv('../files/data/2018年北京积分落户数据.csv',encoding = 'utf-8',index_col = 'id')
df
| name | birthday | company | score | |
|---|---|---|---|---|
| id | ||||
| 1 | 杨效丰 | 1972-12 | 北京利德华福电气技术有限公司 | 122.59 |
| 2 | 纪丰伟 | 1974-12 | 北京航天数据股份有限公司 | 121.25 |
| 3 | 王永 | 1974-05 | 品牌联盟(北京)咨询股份公司 | 118.96 |
| 4 | 杨静 | 1975-07 | 中科专利商标代理有限责任公司 | 118.21 |
| 5 | 张凯江 | 1974-11 | 北京阿里巴巴云计算技术有限公司 | 117.79 |
| ... | ... | ... | ... | ... |
| 6015 | 孙宏波 | 1978-08 | 华为海洋网络有限公司北京科技分公司 | 90.75 |
| 6016 | 刘丽香 | 1976-11 | 福斯(上海)流体设备有限公司北京分公司 | 90.75 |
| 6017 | 周崧 | 1977-10 | 赢创德固赛(中国)投资有限公司 | 90.75 |
| 6018 | 赵妍 | 1979-07 | 澳科利耳医疗器械(北京)有限公司 | 90.75 |
| 6019 | 贺锐 | 1981-06 | 北京宝洁技术有限公司 | 90.75 |
6019 rows × 4 columns
from datetime import datetime
date = pd.to_datetime(df.birthday)
df['age'] = (datetime(2018,7,1) - date).dt.days // 365
df
| name | birthday | company | score | age | |
|---|---|---|---|---|---|
| id | |||||
| 1 | 杨效丰 | 1972-12 | 北京利德华福电气技术有限公司 | 122.59 | 45 |
| 2 | 纪丰伟 | 1974-12 | 北京航天数据股份有限公司 | 121.25 | 43 |
| 3 | 王永 | 1974-05 | 品牌联盟(北京)咨询股份公司 | 118.96 | 44 |
| 4 | 杨静 | 1975-07 | 中科专利商标代理有限责任公司 | 118.21 | 43 |
| 5 | 张凯江 | 1974-11 | 北京阿里巴巴云计算技术有限公司 | 117.79 | 43 |
| ... | ... | ... | ... | ... | ... |
| 6015 | 孙宏波 | 1978-08 | 华为海洋网络有限公司北京科技分公司 | 90.75 | 39 |
| 6016 | 刘丽香 | 1976-11 | 福斯(上海)流体设备有限公司北京分公司 | 90.75 | 41 |
| 6017 | 周崧 | 1977-10 | 赢创德固赛(中国)投资有限公司 | 90.75 | 40 |
| 6018 | 赵妍 | 1979-07 | 澳科利耳医疗器械(北京)有限公司 | 90.75 | 39 |
| 6019 | 贺锐 | 1981-06 | 北京宝洁技术有限公司 | 90.75 | 37 |
6019 rows × 5 columns
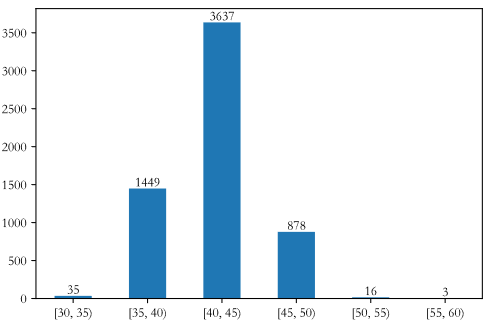
bins = np.arange(30,61,5)
box = pd.cut(df.age,bins,right = False)
ser = df.groupby(box).name.count()
ser
age
[30, 35) 35
[35, 40) 1449
[40, 45) 3637
[45, 50) 878
[50, 55) 16
[55, 60) 3
Name: name, dtype: int64
ser.plot(kind = 'bar')
plt.xticks(rotation = 0)
for i in range(ser.size):
plt.text(i,ser[i]+30,ser[i],ha = 'center') #数字居中显示
plt.show()
sample 使用
# 随机抽取200条数据
df.sample(n = 200)
| name | birthday | company | score | age | |
|---|---|---|---|---|---|
| id | |||||
| 2216 | 台令娟 | 1977-09 | 北京市君合律师事务所 | 95.88 | 40 |
| 4187 | 陈琛 | 1974-10 | 中交远洲信息技术(北京)股份有限公司 | 92.71 | 43 |
| 2037 | 杨正兵 | 1979-07 | 北京金水桥工程技术咨询有限公司 | 96.25 | 39 |
| 2874 | 马紫雯 | 1980-03 | 中央电视台 | 94.67 | 38 |
| 3046 | 张云龙 | 1977-09 | 北京联恒创业科技有限公司 | 94.38 | 40 |
| ... | ... | ... | ... | ... | ... |
| 1065 | 王胜美 | 1975-03 | 毕马威华振会计师事务所(特殊普通合伙) | 99.41 | 43 |
| 1547 | 王伟 | 1976-09 | 北京中软国际信息技术有限公司 | 97.62 | 41 |
| 5233 | 燕宇飞 | 1983-08 | 百度在线网络技术(北京)有限公司 | 91.55 | 34 |
| 5769 | 王翼昕 | 1979-04 | 北京数字中远网络技术服务有限公司 | 90.99 | 39 |
| 2237 | 杜虎 | 1978-05 | 中节能太阳能科技有限公司 | 95.84 | 40 |
200 rows × 5 columns
# 随机抽取x%的数据
# obj.sample(frac = 0.x)
df.sample(frac=0.1)
| name | birthday | company | score | age | |
|---|---|---|---|---|---|
| id | |||||
| 5384 | 高燕 | 1980-11 | 腾讯科技(北京)有限公司 | 91.38 | 37 |
| 3539 | 张正国 | 1980-06 | 阿里巴巴(北京)软件服务有限公司 | 93.63 | 38 |
| 4554 | 张仁 | 1974-12 | 冠捷显示科技(中国)有限公司 | 92.29 | 43 |
| 4126 | 李吉友 | 1974-10 | 北京华为数字技术有限公司 | 92.83 | 43 |
| 3657 | 张宁 | 1975-07 | 北京兴润诚会计师事务所(普通合伙) | 93.46 | 43 |
| ... | ... | ... | ... | ... | ... |
| 2558 | 韩淼 | 1978-09 | 耐瑞唯信(北京)技术有限公司 | 95.25 | 39 |
| 3482 | 许春实 | 1974-03 | 北京三星鹏泰技术咨询有限公司 | 93.71 | 44 |
| 1282 | 刘芳 | 1977-01 | 亚信科技(成都)有限公司北京分公司 | 98.50 | 41 |
| 1667 | 董洪 | 1975-04 | 中央电视台 | 97.29 | 43 |
| 2632 | 苏波 | 1976-08 | 北京亿云力科技有限公司 | 95.09 | 41 |
602 rows × 5 columns
dataframe.replace(0,5)将DataFrame中0替换为5
dataframe.replace([0,1,2,3],[4,3,2,1])将DataFrame中[0,1,2,3]分别替换为[4,3,2,1]
dataframe.replace(to_replace = r’正则表达式’,value = 要替换的值,regex = True)
等价于
dataframe.replace(regex = r’正则表达式’,value = 要替换的值)
dataframe.replace({‘A’:r’正则表达式’},{‘A’:‘new_value’}) - 将A列的满足正则条件的值替换为新值
最后
以上就是活泼刺猬最近收集整理的关于Pandas Cut 与dataframe随机抽取(sample)替换(replace)应用案例的全部内容,更多相关Pandas内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。
![python dataframe 随机找出某一行中 列值最大的位置[列值最大可能会有多个,随机挑选]](https://www.shuijiaxian.com/files_image/reation/bcimg9.png)







发表评论 取消回复