本文提出一种新的胶囊网络路由算法, 主要有以下三个亮点: 首先通过一个反向的点积注意力来设计路由, 其次使用层规范化方法, 最后使用并发迭代路由的方法来取代序列式的迭代.
论文链接: https://arxiv.org/abs/2002.04764v2
开源代码:
https://github.com/apple/ml-capsules-inverted-attention-routing
https://github.com/yaohungt/Capsules-Inverted-Attention-Routing
相关工作
在原始的路由算法中, 每个较低级别(前一层)的胶囊投票给每个较高级别(后一层)的胶囊状态. 较高级 (父级) 的胶囊将汇总选票, 更新其状态, 并使用更新后的状态来解释每个下级胶囊. 被解释清楚的那些最终将更多的信息流向该父级胶囊. 重复此过程, 在选票聚合过程中来确定哪些胶囊被路由到那个父级胶囊. 这个过程类似于期望最大化 (EM) 算法的 M 步和 E 步的迭代方式, 推断隐藏单元的状态和路由概率.
动态路由 (Sabour et al., 2017) 和 EM 路由 (Hinton et al., 2018) 都可以看作上述方案的变体, 它们具有基本的迭代结构, 但在细节方面有所不同, 例如其胶囊设计, 如何汇总票数, 以及是否使用非线性函数.
本文方法
本文介绍一个新颖的路由算法, 被称为 Inverted Dot-Product Attention, 就像一个反向的注意力机制, 高等级的胶囊通过竞争来争夺低等级胶囊的注意力.
路由概率直接取决于父胶囊 (来自上一个迭代步骤) 与子胶囊对父胶囊的投票 (在当前迭代步骤中) 之间的一致性.
设第 L L L 层第 i i i 个胶囊为 p i L mathbf{p}_i^{L} piL, 维度为 d L d_L dL. 路由算法如下:

其中 W i j L mathbf{W}_{ij}^L WijL 是一个可学习的权重.
推理算法如下:

I mathbf{I} I 是输入的图片样本. 其中第 7-9 行是一个并发的路由机制, 一方面加快运算速度, 另一方面能够改进梯度消失的问题. 这个问题是因为迭代次数过多, 间接导致网络层次加深. 并发路由的原理如下图:
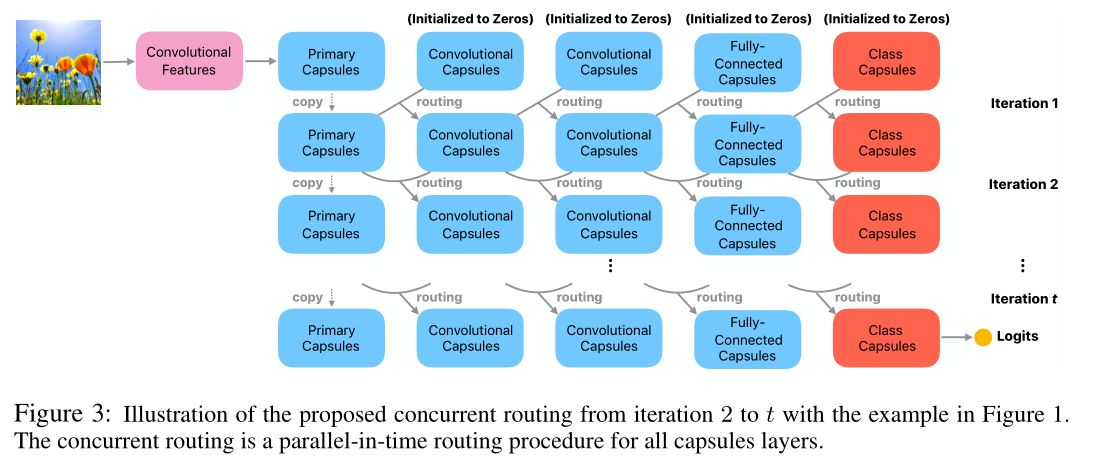
路由过程如图中灰色箭头所示.
参考
-
Sara Sabour, Nicholas Frosst, and Geoffrey E Hinton. Dynamic routing between capsules. In Advances in neural information processing systems, pp. 3856–3866, 2017.
-
Geoffrey E Hinton, Sara Sabour, and Nicholas Frosst. Matrix capsules with em routing. 2018.
最后
以上就是无限芝麻最近收集整理的关于[解读] Capsules with Inverted Dot-Product Attention Routing的全部内容,更多相关[解读]内容请搜索靠谱客的其他文章。




![[解读] Capsules with Inverted Dot-Product Attention Routing](https://www.shuijiaxian.com/files_image/reation/bcimg20.png)


![[笔记][胶囊神经网络]Dynamic Routing Between CapsulesDynamic Routing Between Capsules 笔记](https://www.shuijiaxian.com/files_image/reation/bcimg23.png)
发表评论 取消回复