因为看完的英文论文不记录下来总会忘记,所以打算把看的英文论文翻译并记录在博客中,也欢迎方向类似的同学查阅和提建议哟
文章目录
- 模型
- A 模型定义
- B.概述
- C 模型细节
- 1)BASE网络
- a: Embedding Layer
- b: Conv Layer
- c: Incaps and Ourcaps Layers
- d: Classcaps
- 2) RULE NETWORK
- 总结:
- 思考
本文介绍了一个具有语义规则的领域适应场景中情绪分析的胶囊网络(CapsuleDAR)。胶囊DAR利用胶囊网络对固有的spati进行编码构成域不变知识的全部关系,连接源和目标域之间的知识鸿沟。此外,我们还提出了一个规则网络,将语义规则纳入胶囊网络,以增强综合句子表示学习。
我们提出了一个规则网络,将语义规则集成到胶囊网络中,以捕获跨域的公共知识。
基本网络致力于句子的文本特征。其目的是利用胶囊网络对构成领域不变知识的内在空间部分-整体关系进行编码它自动推广到新的域,弥合了源域和目标域之间的知识鸿沟
带有变换矩阵的胶囊允许网络自动学习部分-整体关系。此外,我们还提出了一个规则网络,将语义规则(如句子的结构)纳入胶囊网络,以进一步提高跨域情感分类的性能。具体来说,第一条规则是利用源和目标域之间的枢轴特征来提高卷积滤波器的性能。第二条规则是利用句子结构信息丰富句子的综合表征学习,进行跨域情感分类
我们的模型主要由基本网络和规则网络组成,提高跨域情感分类的性能。
模型
A 模型定义
我们用 表示源域中标记文档的集合,其中Nsl是源域中的样本数。每个文档xsl都有一个情感标签ysl,是一个one-hot表示。在目标域中,给我们一个未标记的数据集, ,其中Ntu是目标域中的样本数。该模型的目的是利用对源域数据预先训练的情感分类器来预测目标域样本的情感极性。
B.概述
我们的总体架构由两个主要组成部分组成:基本网络和规则网络。基本网络使用具有文本特征训练的胶囊网络来执行情绪预测。它包含一个嵌入层,一个用于捕获文本的n-gram特征的卷积层,一个Incaps和一个Outcaps层,然后是Classcaps层。规则网络将语义规则利用到胶囊网络中,胶囊网络利用公共知识来弥合源域和目标域之间的知识鸿沟。规则网络的结构与基本网络相似,卷积层的参数由这两个网络共享。在规则网络中,我们在Outcaps和Classcaps层之间有一个额外的Rulecaps层,以充分利用语义规则。
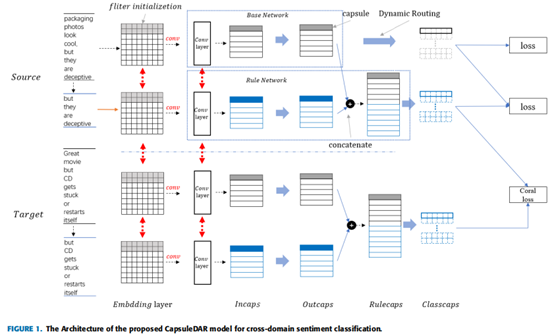
C 模型细节
1)BASE网络
利用Base网络对文本内容特征进行建模
a: Embedding Layer
第一层为嵌入层.给定输入序列x,我们首先通过嵌入层将第一个单词转换成一个低维向量表示ei∈Rd,我们把句子的嵌入作为e∈Rm×d,其中长度为m,是每个单词向量的连接。
b: Conv Layer
第二层是卷积层,它由一个卷积运算组成,通过卷积运算提取输入序列的n-gram特征。假设向量W∈Rk×d是卷积的滤波器,其中k是滤波器的宽度。具有k宽度的滤波器使卷积层能够在输入序列上滑动并获得新的特征。形式上,特征zi是从单词序列ei:i+k-1的本地窗口中学习的。
该卷积滤波器应用于输入序列{e1:k,e2:k+1, …,em-k+1:m}中的每个可能的单词窗口来生成特征映射z∈Rn-k+1。
在这里,每个滤波器的滤波器权重和偏置项在输入中的所有位置之间共享,以保持空间局部性. 然后我们在特征映射上应用一个最大池化操作, 因此,最终可以表示为 其中l是滤波器的数目
我们认为有两种类型的特征对跨领域情感分类很重要:(1)对于源域的情感分类来说,N-gram特征是必不可少的;(2)跨越源域和目标域的枢轴特征,这些特征可用于弥合源域和目标域之间的知识鸿沟。因此,我们引入了一种基于枢轴的滤波器初始化方法来提高该方法的文本表达能力,而不是对卷积层使用随机初始化滤波器。
特别是,我们首先使用tf-id f[32]方法来选择源域中对每个情感类贡献最高的n-gram特征。然后,我们使用SCL方法[7]来选择枢轴特征。遵循[6]中的策略,给出了提取的TF-ID F特征和枢轴特征的集合,我们使用k均值方法对这些特征进行聚类,聚类的质心向量就是我们用于初始化过滤器的权重。
c: Incaps and Ourcaps Layers
一个胶囊是一组神经元,它们代表特定类型物体的实例化参数。胶囊的一个优点是,它们提供了一种有效的方法来模仿人类感知系统,从而识别出部分-整体的关系。
第一个胶囊层是由Conv层的数据转换构建的。此转换允许Conv层的输出直接用作动态路由方法的输入。Outcaps是由Incaps层通过路由方法产生的第二胶囊层
动态路由[27]算法的主要思想是找到表示一组耦合系数的A,每个项目αi,j确定两个胶囊层之间的映射关系:ui和vj。耦合系数决定了j层和i层之间的相关性。在[33]的启发下,我们将路由过程表示为一个最小的聚集模糊K-Means,如聚类损失函数,定义为
其中<,>代表内积,V指代更高层胶囊的集合V={v1,v2,v3。…,vc}。解决这一问题的一种有效方法是使用优化的坐标下降法来优化A和V。
胶囊的长度可以表示出现相应特征的概率。在获得高水平胶囊特征后,我们对高水平胶囊进行非线性squash操作,确保矢量的方向是恒定的。

d: Classcaps
基本网络的最后一层是Classcaps层。Classcaps层是利用动态路由从Outcaps构建的…这一层的胶囊数量取决于情感分类任务的类别数,其中胶囊的长度表示每个类存在的概率。
2) RULE NETWORK
胶囊中的每个神经元不仅代表句子水平的特征(单词、实体、长度等),而且还代表这个实例是否包含特定的结构(例如,句子)结构)以及该结构中的每个元素如何促进情感分类。在本节中,我们设计了一个规则网络,允许网络从句子结构中学习。
与基本网络不同的是,规则网络对句子结构特征进行建模。规则网络的基本结构与基本网络相似。特别是,第一层和第二层分别是嵌入层和Conv层,其次是两个胶囊层:Incap和Outcaps层。在规则网络中,我们在Outcaps层和Classcaps层之间有一个额外的规则层,这与基本网络不同
例如,假设一个句子包含两个从句,由过渡词“然而”连接,“然而”后面的从句代表了整个句子的情感。
在规则网络中,嵌入层的输入是过渡词后面的从句,因此,在Outcaps层中,学习到的信息是一种包括句子特定结构的文本表示,因为规则网络中的嵌入层、Conv层、Outcaps和Classcaps类似于Base network,我们将在本节中主要解释Rule network中独特的Rulecaps层。
Rulecaps:如图1所示,Rulecaps的输入是来自Base network和Rule network的Outcaps层的输出,具体来说,来自Base和规则网络的Outcaps层的输出是并行连接的,然后,我们将其发送到动态路由算法中,以获得规则网络的最终类层。因此,最终输出层的胶囊将由整个句子和从句的特征信息组成
然而,在用动态路由算法构建Rulecaps的过程中(如算法1所示),较大的迭代值t将导致句子结构信息的过度拟合。因此,我们在算法1中的Softmax操作中添加了一个温度参数,从而增加了这些从句对更高级别的胶囊网络的贡献
其中bi表示Softmax层的输出,表示每个类的概率。当T设置为1时,pi是标准的Softmax函数。设置较高的T值可以生成每个类的较为平滑的概率分布
对于情绪分类,第一支部的目标是最大限度地为base网络正确情绪的概率;第二个目标Lc的目的是最大限度地提高rule网络输出层胶囊的概率。
损失函数有两个,一个由base 网络的损失值和rule网络的损失值构成,一个是领域距离损失函数
我们在亚马逊评论数据集上进行实验,使用了四个产品领域的评论,包括DVD(D)、厨房(K)、书籍(B)和电子(E),它们被广泛应用于评价域适应情景中情感分类的性能。
总结:
胶囊网络可以保存训练文本类别的实例化参数,并对构成视点不变知识的固有空间部分-整体关系进行编码。推广到新域,弥补源域和目标域之间的知识差距。此外,我们还将两个典型的语义规则,如权重初始化规则和句子结构信息,纳入胶囊网络,以进一步提高跨领域情感分类的性能。
思考
本文整个模型分为两个子网络,一个是base 网络,构成是 嵌入层、卷积、Incaps、Outcaps_base、Classcaps,一个是rule网络,构成是 嵌入层、卷积、Incaps、Outcaps_rule 、Outcaps_base+ Outcaps_rule、Rulecaps、Classcaps
本文有两个地方都很有创新:一是不仅对整个句子的向量表示输入到胶囊网络base network 中,还把转折词后面的从句 单独输入到rule network 中;二是跨领域的进行情感预测,不过这里还没有看懂,(我是不是可以用水果的情感训练模型来预测汽车的呢?)
最后
以上就是俏皮小白菜最近收集整理的关于论文解析:Cross-Domain Sentiment Classification by Capsule Network With Semantic Rules,2018-IEEE ACCESS模型思考的全部内容,更多相关论文解析:Cross-Domain内容请搜索靠谱客的其他文章。








发表评论 取消回复