前言:
网上有很多关于hadoop搭建的教程,由于搭建环境不同,会出现各种各样的问题。那么就由我来带大家排坑吧,小编虚拟机Ubuntu14.0,centos7,centos6,阿里云centos6,阿里云centos7,腾讯云centos6,腾讯云centos7都搭建成功,中间出现很多不同的情况。只要你跟着我来,就不会出现问题。不管你是伪分布式,还是分布式。
服务器:
用户:hadoop| ip | 机器名 | 系统 |
| 192.168.2.100 | master | centos7 |
| 192.168.2.101 | slave1 | centos7 |
| 192.168.2.102 | slave2 | centos7 |
注意先把防火墙关了!
安装JDK:
1.wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://downl
2.解压 tar -zxvf 文件名
修改profile文件:
vim /etc/profile(没有vim 就用vi)
添加以下内容:
export JAVA_HOME=/opt/jdk8
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
更新一下配置
source /etc/profile
然后输入jps
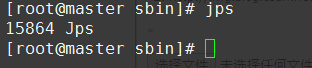
这就可以了 jdk配置完成
下载hadoop:
wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
然后解压和解压jdk一样,还是建议/opt
给/opt 目录下所有文件权限,方便操作
chmod -R 777 /opt
我们到 /opt/hadoop-2.7.3/etc/hadoop 这个目录下
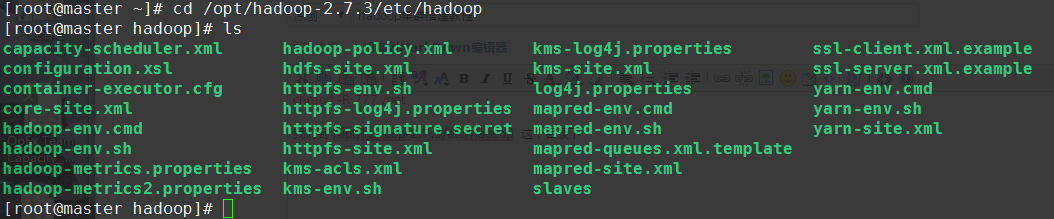
修改 hadoop-env.sh:
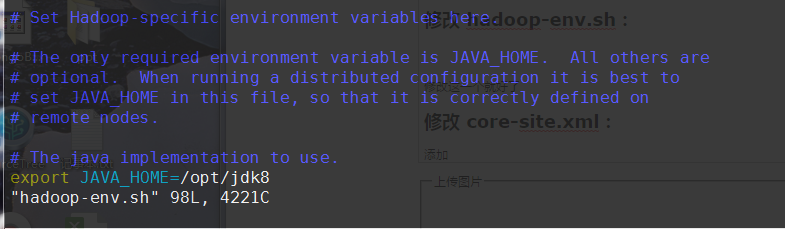
修改这一个就好了
修改 core-site.xml:
添加
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.7.3/hadoop_tmp</value>
</property>
注意:这里的hdfs地址我用的是127.0.0.1,这是伪分布式搭建绝对不会有问题的一个配置,不管你host配置什么。分布式的话,填上mastdeIP地址192.168.2.100
修改 hdfs-site.xml:
添加:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
这是hdfs文件系统的副本数量,伪分布式建议1,分布式有几台机器就填几
注意:hdfs的datanode目录,还有namenode新手目录不要指定,默认就好
修改 mapred-site.xml:
添加:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
修改 yarn-site.xml:
添加:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
注意:这里yarn的hostname伪分布式就填写127.0.0.1不会有错,分布式的话就填192.168.2.100
修改 slaves:
这个文件决定了你搭建完全分布式系统,还是伪分布式系统
直接添加一个127.0.0.1的话就是伪分布式系统
添加192.168.2.101和192.168.2.102的话就是分布式系统,这两个服务器就会启动DataNode进程
我们这里只添加127.0.0.1
好了,到此我们的配置就完成了(老手可以自行配置hosts文件代替ip地址)
格式化namenode!:
无数的人死在了这一步上
/opt/hadoop-2.7.3/bin/hadoop namenode -format

看到这一个也不一定代表你成功!
别怕,继续!
启动集群:
/opt/hadoop-2.7.3/sbin/start-all.sh
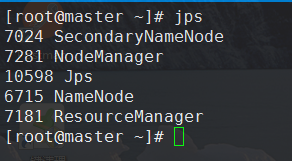
jps后出现这些就代表你的伪分布式搭建没有问题的,有人反馈说50070端口或者其他端口打不开,注意你的防火墙是否关闭centos6和centos7的防火墙可不一样!
如果你格式化namenode以后,还是启动不了所有的进程,删掉/home下所有文件再来一下,重启,再次启动集群。阿里云centos6,第一次格式化后启动偶尔会失败一次,原因未知。
亲,如果你还是启动不了所有进程,我确定,你肯定哪一步和我不一样,你可以去/opt/hadoop-2.7.3/logs看一下日志,具体问题都可以找到
完全分布式
按照我的slaves说明去配,复制hadopp到不同的机器下,然后只要master启动hadoop集群就可以了,127.0.0.1要换成master的IP
欢迎大数据方便的同学交流
qq 475059648
最后
以上就是强健老鼠最近收集整理的关于hadoop搭建教程,多环境通吃的全部内容,更多相关hadoop搭建教程内容请搜索靠谱客的其他文章。








发表评论 取消回复