前言
教程使用阿里云服务器,CentOS7.4操作系统。在对linux有一定的基础前提下,搭建起来会很轻松。如果没有linux基础,在使用教程中指令时可以先自行查一下指令的用法说明。教程中也会尽量照顾到没有linux基础或基础比较薄弱的小伙伴,没有基础的小伙伴也无需担心,依照教程一样可以搭建完成。
| 操作系统 | JAVA | Hadoop | 辅助连接工具 |
| CentOS7.4 | JDK1.8 | 3.2.0 | PuTTY、WinScp |
一、环境配置
1、Java安装
先检查系统是否自带java,输入:
java -version如若出现版本信息,则已安装java(CentOS7.4自带openjdk),如果系统已安装openjdk,则先卸载。centos7删除自带openjdk
安装1.8以上java,下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
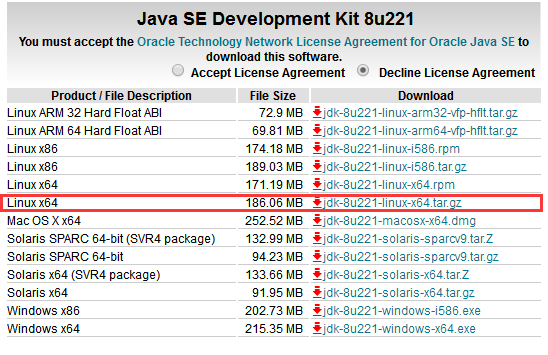
使用Putty登录系统,在usr文件夹下建立java文件夹,可以使用命令,也可直接用WinSCP鼠标右键创建
mkdir /usr/java上传下载的java包至服务器中新创建的java文件夹中(使用WinSCP类似操作windows系统一样直接操作即可,考虑让没有Linux能更好的进行搭建,此处进行说明,后续将不再对基本操作进行说明)

进入java文件夹
cd /usr/java/解压文件
tar –zxvf jdk-8u221-linux-x64.tar.gz修改解压出的文件夹名称(名称修改短一点,方面各项配置环境变量)
mv jdk1.8.0_221 jdk1.8配置环境变量
打开 profile(路径:/etc/profile) ,在最后添加
#java环境
export JAVA_HOME=/usr/java/jdk1.8
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
添加后重新加载文件
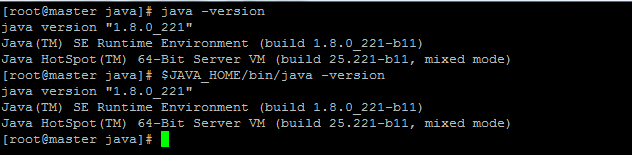
source /etc/profile判断java是否安装成功,执行java -version即可看见java版本信息 ,如果执行$JAVA_HOME/bin/java -version也可看见版本信息,则说明环境变量配置正确。
2、系统设置
1、关闭SELinux[Linux的安全子系统]以及防火墙(开放所有端口,以便调试。生产环境中请谨慎操作)
停止防火墙
systemctl stop firewalld.service防火墙开机禁止启动
systemctl disable firewalld.service临时关闭SELinux
##设置SELinux 成为permissive模式
##setenforce 1 设置SELinux 成为enforcing模式
setenforce 0永久关闭
进入到/etc/selinux/config文件,将SELINUX=enforcing改为SELINUX=disabled(需重启系统生效)
2、创建hadoop用户
hadoop启动或者执行很多操作时,如果不用hadoop账号,hadoop会禁止执行很多启动命令。所以需要创建hadoop账户。创建hadoop用户。教程为了调试方便,会配置成root账号也能启动,如果想使用root账号操作,可以跳过此步骤
useradd hadoop设置密码:
passwd hadoop之后安装Hadoop时会用于很多root权限,为了便于调试,可直接设置刚创建的hadoop账号拥有全部root权限。
修改 /etc/sudoers 文件,找到下面一行,并在其后新增一行,如下所示
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL <!--新增行-->
保存退出,使用hadoop登录,然后使用sudo su - 或 sudo 命令,输入hadoop的密码,即可获得root权限执行该命令;使用exit退出root用户模式。
3 安装SSH
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),一般情况下,CentOS 默认已安装了 SSH client、SSH server,打开终端执行命令:rpm -qa | grep ssh,进行检验,如果没有则执行安装:
yum install openssh-clients
yum install openssh-server4 设置SSH免密登录,方便调试
依次执行以下命令
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys执行ssh localhost命令后如果可以直接登录,说明SSH免密登录配置成功

二、hadoop安装
下载地址: http://mirror.bit.edu.cn/apache/hadoop/common/ 本教程选择的是 3.2.0 版本,下载时请下载 tar.gz 这个格式的文件,这是编译好的,另一个包含 src 的则是 Hadoop 源代码,需要进行编译才可使用。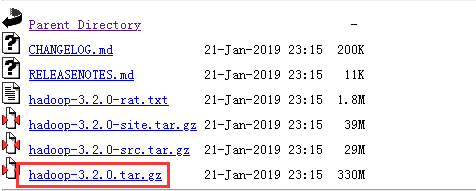
建立文件夹:
mkdir /usr/hadoop上传hadoop至文件夹

进入到文件夹下,解压文件
tar -zxvf hadoop-3.2.0.tar.gz文件夹名字改为hadoop3
mv hadoop-3.2.0 hadoop3设置环境变量:打开/etc/profile文件,增加
#hadoop环境变量
export HADOOP_HOME=/usr/hadoop/hadoop3
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH重新加载一下文件
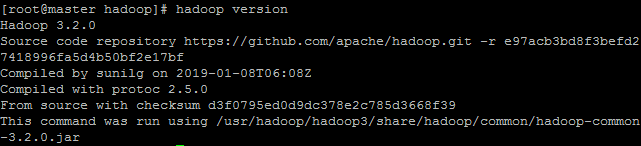
source /etc/profile执行hadoop version,出现hadoop版本信息即配置成功
三、配置并启动HDFS
修改各项配置文件时,注意要使用UTF8编码
创建hadoop数据文件建
mkdir /usr/hadoop/hadoopdata
mkdir /usr/hadoop/hadoopdata/tmp
mkdir /usr/hadoop/hadoopdata/var
mkdir /usr/hadoop/hadoopdata/dfs
mkdir /usr/hadoop/hadoopdata/dfs/name
mkdir /usr/hadoop/hadoopdata/dfs/datahadoop配置文件均在解压出来的文件夹下的/etc/hadoop/里。修改hadoop-env.sh(路径/usr/hadoop/hadoop3/etc/hadoop/hadoop-env.sh)。将JAVA_HOME修改为自己的JDK路径。加入在文件中加入
export JAVA_HOME=/usr/java/jdk1.8
修改core-site.xml文件( /usr/hadoop/hadoop-3.2.0/etc/hadoop/core-site.xml )
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoopdata/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<!-- 指定HDFS(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>修改/usr/hadoop/hadoop-3.2.0/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hadoopdata/dfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hadoopdata/dfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>以root账号启动时,报错
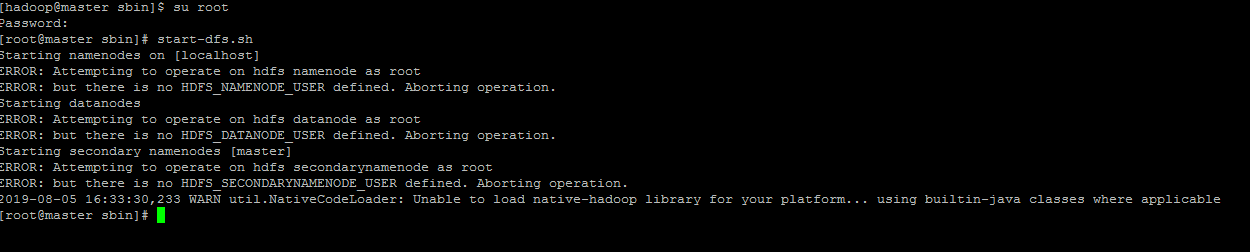
因为如果你的Hadoop是另外启用其它用户来启动,需将root改为对应用户,在/hadoop/sbin路径下,将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root,第一次启动hdfs需要格式化,切换到 /usr/hadoop/hadoop-3.2.0/bin/目录下输入
hdfs namenode -format格式化是对 HDFS这个分布式文件系统中的 DataNode 进行分块,统计所有分块后的初始元数据的存储在namenode中。(如果服务器再次启动,hdfs启动可能会失败,有时需要重新进行这步。
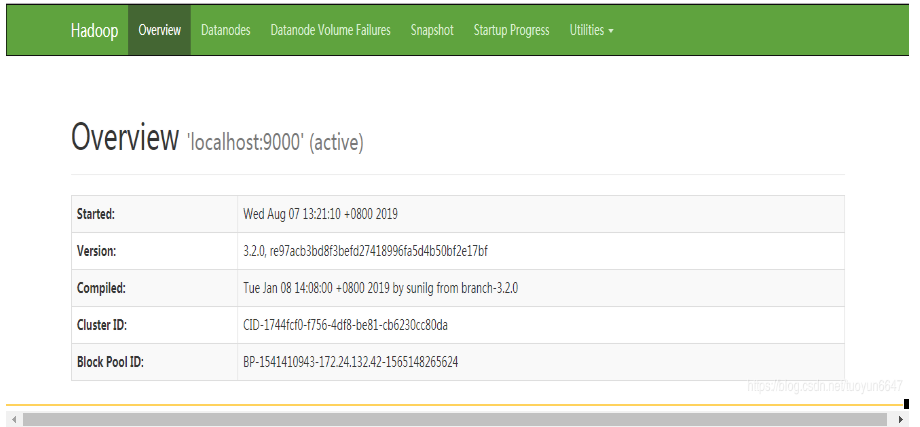
到sbin文件夹下(cd usr/hadoop/hadoop3/sbin/),执行启动命令,启动hdfs
start-dfs.sh启动成功后访问9870端口(2.x版本端口为50070),http://192.168.1.10:9870。推荐使用谷歌Chrom或者火狐浏览器。360浏览器会出现“Failed to retrieve data from /jmx?qry=Hadoop...”报错信息
五、配置并启动yarn
配置yarn文件. 配置/usr/hadoop/hadoop-3.2.0/etc/hadoop/mapred-site.xml 。这里注意一下,hadoop里面默认是mapred-site.xml.template 文件,如果配置yarn,把mapred-site.xml.template 重命名为mapred-site.xml 。如果不启动yarn,把重命名还原。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/usr/hadoop/hadoopdata/var</value>
</property>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>配置/usr/hadoop/hadoop-3.2.0/etc/hadoop/yarn-site.xml文件
<?xml version="1.0"?>
<configuration>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>设置yarn可以用root账号启动,start-yarn.sh,stop-yarn.sh顶部需添加以下:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
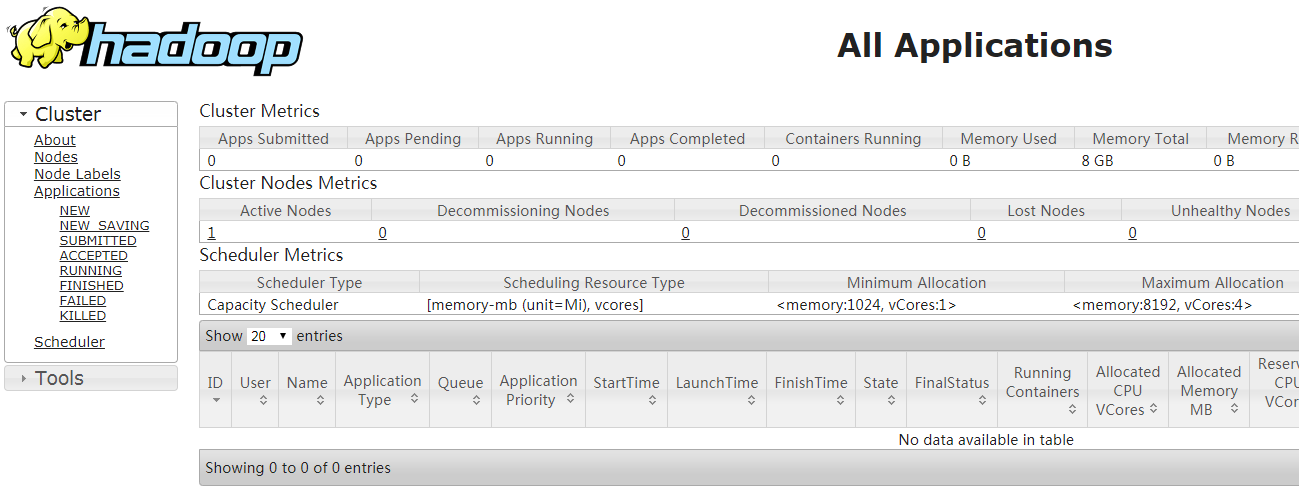
YARN_NODEMANAGER_USER=root在sbin目录下启动yarn
start-yarn.sh启动后访问8088端口,http://192.168.1.10:8088
最后
以上就是平常秀发最近收集整理的关于Hadoop教程 | 第一篇:CentOS7安装Hadoop3.0 | 伪分布式的全部内容,更多相关Hadoop教程内容请搜索靠谱客的其他文章。








发表评论 取消回复