本文主要介绍如何在Centos7系统安装和配置单节点Hadoop3.0.0,并运用Hadoop MapReduce和Hadoop分布式文件系统(HDFS)执行wordcount测试样例。
资源和环境
jdk:jdk-8u11-linux-x64.rpm
hadoop:hadoop-3.0.0.tar.gz
操作系统:CentOS-7-x86_64
系统用户:root
安装jdk
[root@localhost zby]# rpm -ivh jdk-8u11-linux-x64.rpm[root@localhost zby]# javac
Usage: javac <options> <source files>
where possible options include:
-g Generate all debugging info
-g:none Generate no debugging info
-g:{lines,vars,source} Generate only some debugging info
-nowarn Generate no warnings
-verbose Output messages about what the compiler is doing
设置环境变量,打开.bash_profile
[root@localhost java]# cd
[root@localhost ~]# vim .bash_profileexport JAVA_HOME=/usr/java/jdk1.8.0_11
export PATH=$JAVA_HOME/bin:$PATH执行source .bash_profile使配置生效
安装jps
执行jps命令提示bash: jps: command not found...,可通过以下方式解决
[root@localhost zby]# vim /etc/profile[root@localhost zby]# source /etc/profile[root@localhost zby]# jps
13049 Jps
安装和配置ssh免密码登录
[root@localhost zby]# yum install ssh[root@localhost zby]# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
Generating public/private rsa key pair.
Created directory '/root/.ssh'.
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
97:d3:d3:62:e6:4b:7b:9a:c0:8f:b1:5d:01:e7:5c:4e root@localhost.localdomain
The key's randomart image is:
+--[ RSA 2048]----+
| |
| |
| . . E|
| o * + |
| S + * = .|
| o = o . |
| + o . |
| O =. |
| o Bo |
+-----------------+
[root@localhost zby]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[root@localhost zby]# chmod 0600 ~/.ssh/authorized_keys安装hadoop3.0.0
将hadoop:hadoop-3.0.0.tar.gz解压缩到目录/home/zby下
[root@localhost zby]# pwd
/home/zby
[root@localhost zby]# tar -zxvf hadoop-3.0.0.tar.gz [root@localhost ~]# vim ~/.bash_profileexport HADOOP_HOME=/home/zby/hadoop-3.0.0
PATH=$JAVA_HOME/bin:$PATH:$HOME/bin:$HADOOP_HOME/bin
[root@localhost ~]# source ~/.bash_profile 修改配置文件
vim etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>vim etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>vimetc/hadoop/mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.admin.user.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME</value>
</property>vim etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>vim sbin/start-dfs.sh:
在顶部空白处添加
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root 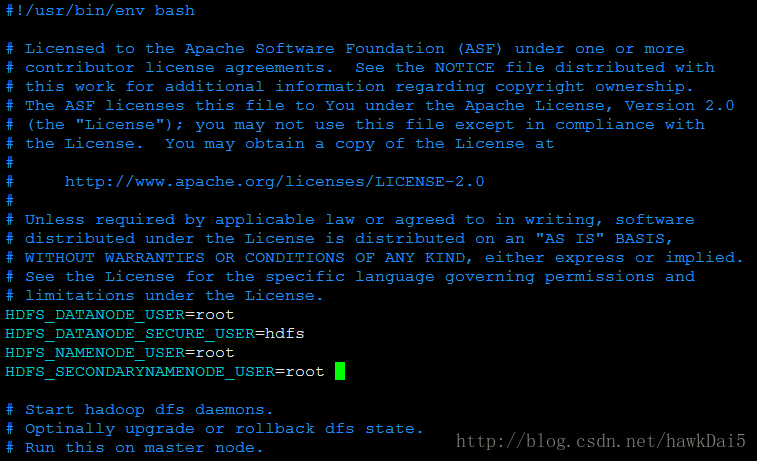
vim sbin/stop-dfs.sh:
在顶部空白处添加
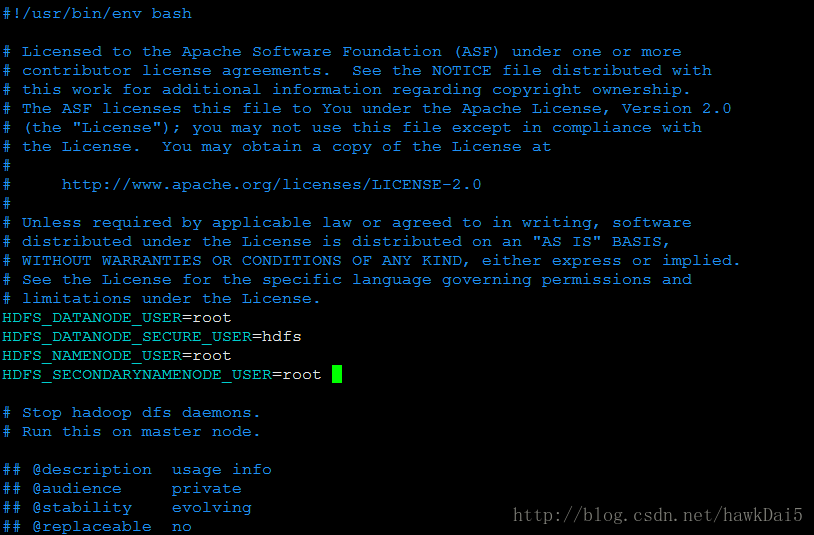
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root 如图:
vim sbin/start-yarn.sh:
在顶部空白处添加:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root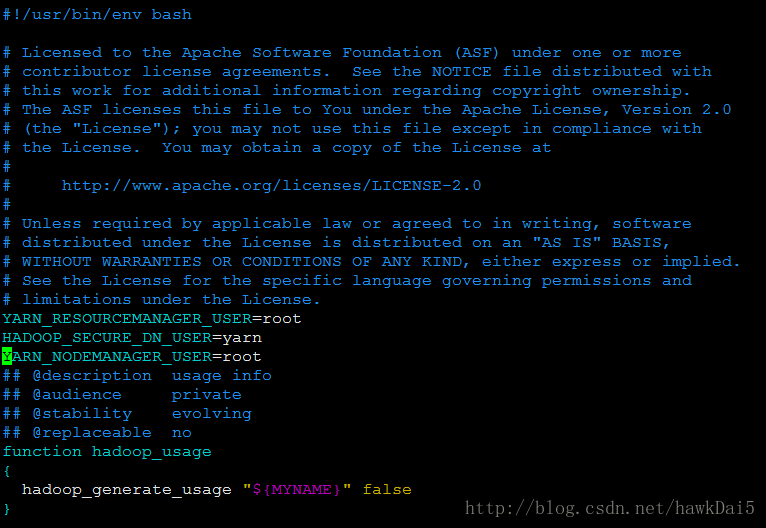
vim sbin/stop-yarn.sh:
在顶部空白处添加:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root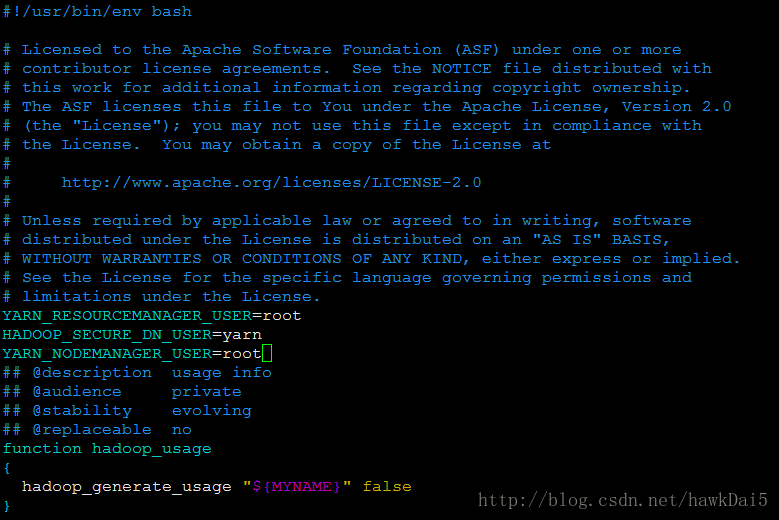
vim /etc/hadoop/hadoop-env.sh
设置JAVA_HOME
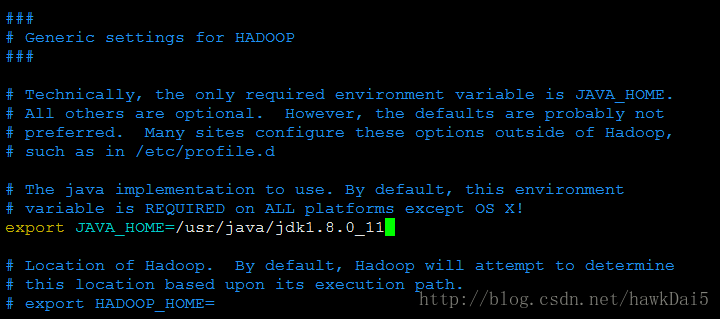
启动hadoop
首先格式化命名空间:
[root@localhost hadoop-3.0.0]# bin/hdfs namenode -formatStart NameNode daemon and DataNode daemon:
[root@localhost hadoop-3.0.0]# sbin/start-dfs.sh
Starting namenodes on [localhost]
Last login: Wed Feb 7 11:10:43 CST 2018 on pts/1
Starting datanodes
Last login: Wed Feb 7 11:19:46 CST 2018 on pts/1
Starting secondary namenodes [localhost.localdomain]
Last login: Wed Feb 7 11:19:49 CST 2018 on pts/1[root@localhost hadoop-3.0.0]# sbin/start-yarn.sh
Starting resourcemanager
Last login: Wed Feb 7 11:19:56 CST 2018 on pts/1
Starting nodemanagers
Last login: Wed Feb 7 11:21:47 CST 2018 on pts/1
[root@localhost hadoop-3.0.0]# jps
15458 SecondaryNameNode
16323 Jps
14980 NameNode
15786 ResourceManager
15165 DataNode
15934 NodeManager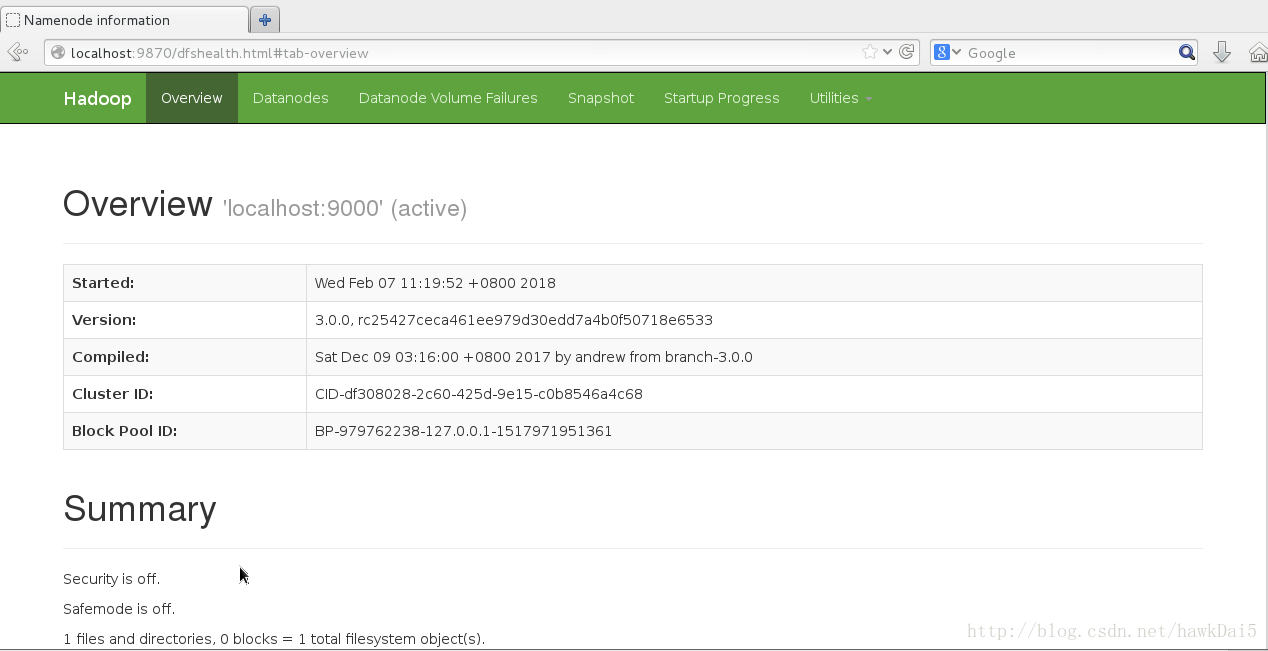
访问http://localhost:8088/查看Yarn信息:
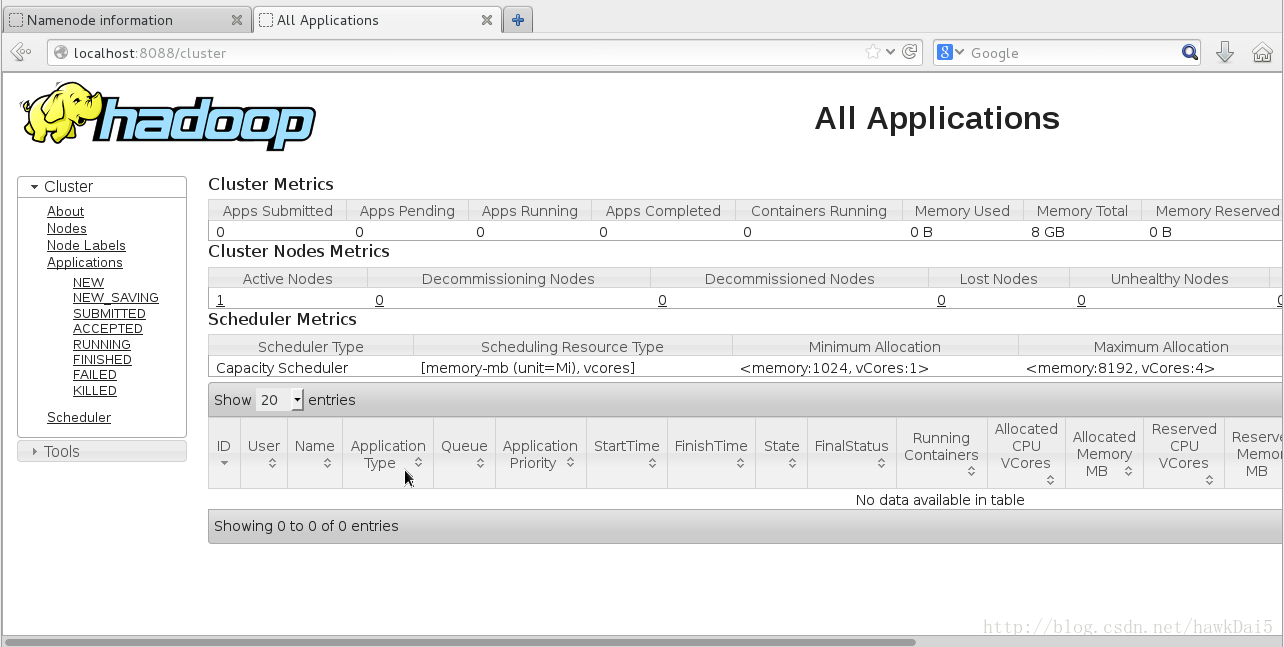
停止hadoop
sbin/stop-dfs.sh
sbin/stop-yarn.sh
wordcount测试
创建本地示例文件
[root@localhost hadoop-3.0.0]# mkdir /home/zby/file
[root@localhost hadoop-3.0.0]# cd ../file/
[root@localhost file]#
[root@localhost file]#
[root@localhost file]# echo "hello world" > file1.txt
[root@localhost file]# echo "hello hadoop" > file2.txt
[root@localhost file]# echo "hello mapreduce" >> file2.txt
[root@localhost file]# ls
file1.txt file2.txt在HDFS上创建输入文件夹
[root@localhost file]# cd ../hadoop-3.0.0/
[root@localhost hadoop-3.0.0]# bin/hadoop fs -mkdir /hdfsinput
[root@localhost hadoop-3.0.0]# bin/hadoop fs -put /home/zby/file/file
file1.txt file2.txt
[root@localhost hadoop-3.0.0]# bin/hadoop fs -put /home/zby/file/file* /hdfsinput运行Hadoop 自带示例wordcount
[root@localhost hadoop-3.0.0]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar wordcount /hdfsinput /hdfsoutput[root@localhost hadoop-3.0.0]# bin/hadoop fs -ls /hdfsoutput
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-02-07 13:49 /hdfsoutput/_SUCCESS
-rw-r--r-- 1 root supergroup 37 2018-02-07 13:49 /hdfsoutput/part-r-00000
[root@localhost hadoop-3.0.0]# bin/hadoop fs -cat /hdfsoutput/part-r-00000
hadoop 1
hello 3
mapreduce 1
world 1查看part-r-00000文件发现hello出现3次,hadoop出现1次,world出现1次
最后
以上就是大胆发带最近收集整理的关于Centos7安装配置单节点Hadoop3.0.0wordcount测试的全部内容,更多相关Centos7安装配置单节点Hadoop3内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复