语义和边缘:从噪声和符号中学习
Devilis in the Edges: Learning Semantic Boundaries
from Noisy Annotations
论文地址:https://arxiv.org/pdf/1904.07934.pdf
项目链接:https://nv-tlabs.github.io/STEAL/
摘要
解决了语义边界预测问题,它的目标是识别属于对象(类)边界的像素。注意到,相关数据集包含显著的标签噪声水平,反映了精确注释难以获得的事实,因此注释者在质量和效率之间进行了权衡。在训练过程中,通过对标注噪声的显式推理来学习清晰而精确的语义边界。提出了一个简单的新层和损耗,可用于现有的基于学习的边界检测器。层/损耗强制检测器沿边缘的法向预测最大响应,同时也使其方向规则化。在训练过程中,使用水平集公式进一步分析真实的对象边界,该公式允许网络以端到端的方式学习未对齐的标签。实验表明,相对于CASENet〔36〕主干网,在MF(ODS)和AP方面分别提高了4%和18.61%以上,其性能优于所有当前最先进的方法,包括处理对齐的方法。此外,还表明,所学习的网络可用于显著改善粗略的分割标签,从而使自己成为标记新数据的有效方法。
主要创新
本文旨在通过训练过程中标注噪声的显式推理来学习清晰、精确的语义边界。提出了一个新的层和损耗,可以添加到任何端到端边缘检测器的顶部。强制边缘检测器预测沿边缘法向的最大响应,同时也使其方向规则化。通过这样做,可以缓解预测过厚边界的问题,并直接优化非最大抑制(NMS)边。进一步使用一个级别集或公式来解释真正的对象边界,允许网络以端到端的方式从未对齐的标签中学习。实验表明,使骨干网CASENet[36]的MF(ODS)性能提高了4%以上,AP性能提高了18.61%,优于目前所有的最新方法。测边界明显优于从最新的DeepLab-v3[9]分段输出中获得的边界,同时使用了更轻的架构。学习网络还能够改进粗标注的分割掩模,误差分别为16px、32px,精度分别提高了20%和30%以上。这使得成为一种有效的方法来收集新的标记数据,使得注释者只需点击几下就可以粗略地勾勒出对象的轮廓,生成更精确的基本事实。通过重新定义城市景观粗糙标签集,并利用这些标签来训练一个最先进的分割网络[9]来展示这个想法。在一些重新定义的类别中,显著改善超过1.2%。
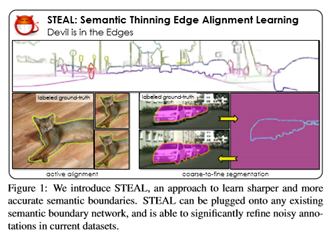
对齐方法The STEAL Approach
语义细化边缘对齐学习(STEAL)方法。包括一个新的边界细化层和一个损失函数,目的是产生薄而精确的语义边缘。提出了一个框架,在训练过程中,当学习将带噪声的人类标注边缘与真实边界对齐时,共同学习对象边缘。称后者为主动对准。直观地说,利用真实的边界信号来训练边界网络,期望能够学习并产生更准确的预测。STEAL对主干CNN体系结构是不可知的,可以插在任何现有的基于学习的边界检测网络之上。在图2中说明了框架。
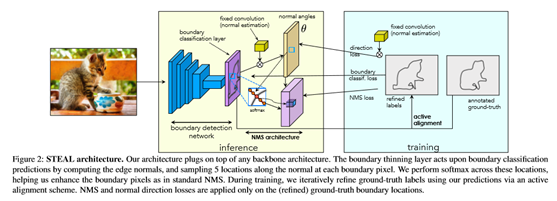

在标准公式中,每个边界地图中的邻近像素被认为是独立的,并且可以导致预测在对象边界附近密集地“fire”。目标是鼓励沿着每个边界像素的法线进行预测,以给出实际边界上的最大响应。其灵感来源于Canny的工作[6]中基于边缘的非最大抑制(NMS)。此外,还增加了一个附加的损失项,以鼓励由预测边界映射估计的法线与由地面真值边缘计算的法线一致。这两个损失共同作用,沿法向和切向产生更清晰的预测。
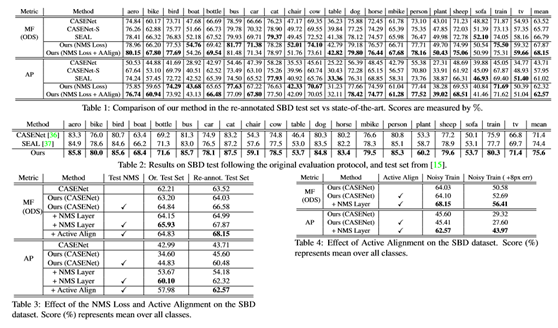
在标准SBD基准[15]和城市景观数据集[11]上进行下一次全面评估。进一步展示了如何使用本方法显著地改进粗分割标签,模拟在带有中等噪声的标签数据集上训练的场景,并使用训练的模型仅从粗注释数据(用较少的手动注释工作收集)生成更细注释。

通过与主动对准相结合,可以看到性能得到了进一步的提高。在表5中,还评估了在城市景观数据集中的性能。
在两个不同的测试集中,评估了在SBD数据集上NMS的性能和方向损失。其中包括原始的带噪注释的测试集及其[37]中的重新注释版本。表3所示的比较突出了NMS和方向损失在两个测试集上的有效性。在原测试集中,将CASE-Net的性能提高了3.72%的MF(ODS)In terms和17.11%的AP。在高质量测试集中,分别比基线测试强5.35%和18.61%。
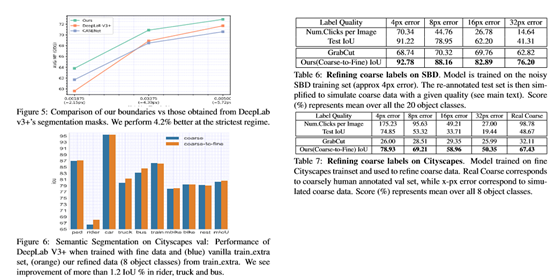
这消除了DeepLab表现不佳的ego车和图像边界。比较(图5)显示,在不同的匹配阈值下,STEAL在allevaluation机制中优于DeepLab edges,例如在∼2pxthrs时为4.2%。
图3和图7分别显示了在SBD和Cityscapes数据集上的定性结果。可以看到预测比基本网络更为清晰。在图4中,说明了训练期间通过主动对准获得的真实边界。
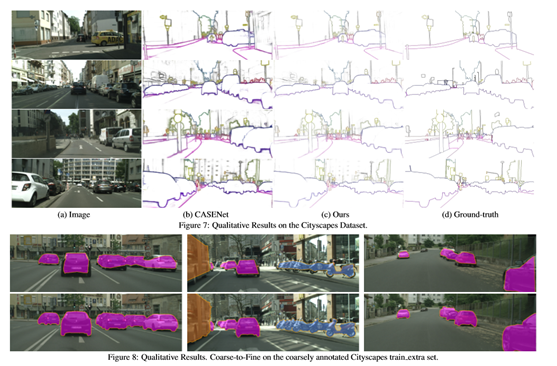
在图8中展示了定性结果。从一个非常粗糙的分割掩模开始,能够获得非常精确的重新定义掩模。可以引入到当前的注释工具中,从而节省了大量的注释时间。
图6提供了8个类相对于其他类的单独性能。发现骑手、卡车和公共汽车的IoU改善了1.2%以上,总体平均IoU也有所改善(80.55比80.37)。
最后
以上就是美好百褶裙最近收集整理的关于语义和边缘:从噪声和符号中学习的全部内容,更多相关语义和边缘内容请搜索靠谱客的其他文章。

![[px4仿真]px4的STIL仿真中添加向下的摄像头](https://www.shuijiaxian.com/files_image/reation/bcimg17.png)






发表评论 取消回复