强化学习(Reinforcement Learning, RL)作为机器学习的一种技术,近年来受到了大量的关注,也取得了一些应用上的进展,比如AlphaGo的成功。论坛上已经有了大量的帖子博文介绍强化学习,感兴趣的朋友可以参考https://blog.csdn.net/Young_Gy/article/details/73485518,https://blog.csdn.net/liweibin1994/article/details/79079884
这里应用强化学习中最基本的Q-Learning算法来实现一个小的例子,并将自编的Matlab代码分享出来,揭开强化学习神秘的面纱,开始认识学习RL,与大家共同学习讨论。想进深入了解学习RL原理的同学也可以参考上面的链接或者关注莫烦的python教学,里面有RL的专题。
一、问题模型
强化学习一般针对的是小规模的离散系统,而且用马尔科夫决策链来表示(Markov Decision Process, MDP),这种系统的特点就是系统的状态(state)与动作(action)都是离散的,系统从当前状态在action的作用下转移到下一个状态,转移的概率等情况只与当前的状态于动作有关。这里要用到的例子就是使用MDP进行描述的。
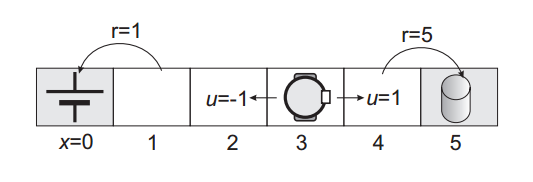
如图1所示,机器人的位置状态量被分为6个,从0到5,0位置是起始点,机器人要从这里出发前往位置5。action有两个,向左移动或向右移动,在左右移动动作的影响下,机器人分别向左或向右移动一格(这里是deterministic系统)。实际采用的reward与图片中的有所不同,从1到0 的转换reward是0,如果从0往左走会直接导致任务失败,重新开始。从状态4到5则会获得reward为1,并成功结束任务。
二、Matlab代码
这个小例子中的代码的核心思想就是更新Q-table,然后机器人依据Q-table的值来选择对应的动作。通过不断的与环境进行交互,学习更新Q表,最后达到稳定也就是最优。
2.1 主函数
clear; clc; close all;
% RL implementation on a finite-state clean robot
% 设置参数:状态量个数,动作的个数,最大循环数
global state_num
state_num = 6;
action_num = 2;
episode_max = 50;
Gama = 0.9; % discout factor
Alpha = 0.1; % 学习速率
% 初始化Q值表
Q_table = zeros(state_num, action_num)
for i=1:episode_max
% 每次训练的初始化
step_counter = 0;
S = 0;
is_terminal = false;
while ~is_terminal
% 选择动作,更新状态,更新Q表
A = choose_action(S, Q_table);
[S_, R, flag] = get_env_feedback(S, A);
Q_predict = Q_table(S+1, A);
% 根据下一步是否是终点来更新flag参数以及Q值
if S_ ~= state_num - 1 && flag == 0
% 当下的reward加上下一步的discounted Q-value
Q_target = R + Gama * max(Q_table(S_+1, :));
elseif flag == 1 % 撞墙了,直接终止
break;
else
% 如果是终点就没有下一步,直接赋值
Q_target = R;
is_terminal = true;
end
Q_table(S+1, A) = Q_table(S+1, A) + Alpha * (Q_target - Q_predict);
S = S_; % 更新状态量
step_counter = step_counter + 1;
end
if S==state_num - 1
fprintf('%d: Succeed! total step: %dn', i, step_counter);
elseif flag == 1
fprintf('%d: Danger, failed! total step: %dn', i, step_counter);
else
fprintf('nothing happenedn');
end
end
Q_table
2.2 选择动作函数choose_action.m
function A = choose_action( S, Q_table )
%CHOOSE_ACTION 此处显示有关此函数的摘要
% greedy policy
epsilon = 0.9;
a = rand;
choices = Q_table(S+1, :);
if a>epsilon || ~any(choices)
A = floor(2*rand) + 1;
else
[maximum ,A] = max(choices);
end
end
2.3 环境交互反馈函数get_env_feedback.m
function [S_, R, flag] = get_env_feedback(S, A)
%GET_ENV_FEEDBACK 此处显示有关此函数的摘要
% 此处显示详细说明
global state_num
flag = 0;
if A == 2 % 向右移动
if S == state_num - 2 % 下一步即将到达终点
R = 1;
S_ = S+1;
else
R = 0;
S_ = S+1;
end
end
if A == 1 % 向左移动
R = 0;
if S == 0 % 撞墙了
S_ = S;
flag = 1;
else
S_ = S-1;
end
end
end
三、仿真结果
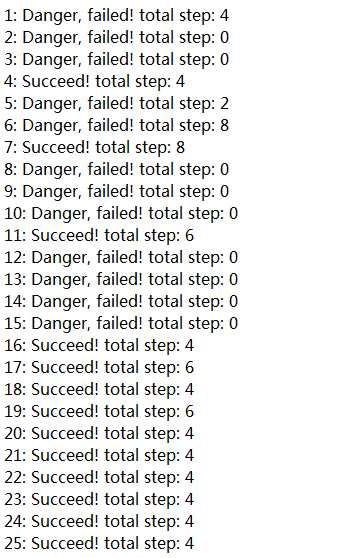
可以看到到后面策略基本上已经稳定。因为每次选择有10%的概率会随机选择一个动作(这样是为了充分探索环境),所以在位置0处还是会可能发生撞墙的风险,也会发生偶尔多走两步的情况。
四、Reward 设置
现在觉得策略收敛的还是太慢了,如果将状态数增加到10(起点与终点距离增大),看看仿真结果:

可以看到需要迭代将近70次才能基本收敛,这样的效率是很低的。为了提高学习效率,避免机器人做徒劳的尝试,我们可以人为地修改一下reward的设置,将在状态0处选择向左移动(即撞墙动作)设置reward为-1,加以惩罚,试图避免机器人多次选择这个危险动作,修改的代码只需添加一行。在主函数中将
elseif flag == 1 % 撞墙了,直接终止
break;
改为
elseif flag == 1 % 撞墙了,直接终止
Q_table(S+1, A) = R;
break;
另外在get_env_feedback函数中在撞墙的判定里加入R=-1这个赋值:
if A == 1 % 向左移动
if S == 0 % 撞墙了
R = -1;
S_ = S;
flag = 1;
else
R = 0;
S_ = S-1;
end
end
观察训练结果:
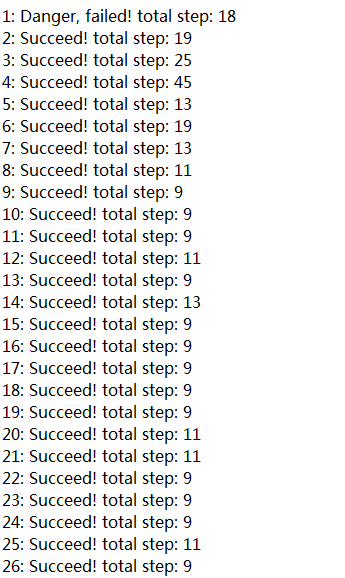
对应的Q-table最终训练结果为:
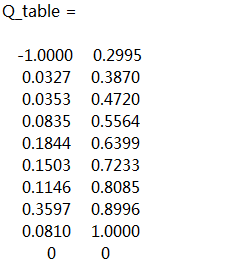
可以看到最优策略十步迭代以内基本收敛,并且在100次的迭代中总共只发生了三次撞墙,结果相当令人满意。从这个例子反映出了,reward的设置对于强化学习的训练至关重要。reward设置不当,不仅会引起收敛缓慢,甚至会将agent引导至错误的policy,与初始目标背道而驰(如原地打转等)。故而针对每一个具体的场景,需要量体裁衣,对合适的状态动作设置一个合适的reward,进行奖励或者惩罚,最好地实现学习过程。
五、SARSA
SARSA(state-action-reward-state-action)作为与Q-learning齐名的RL算法,到底有什么神秘之处呢?这里我推荐一个我喜欢的答案:
https://www.zhihu.com/question/26408259/answer/467132543
一言以蔽之,SARSA与Q-learning不同之处仅在于更新Q-value时下一个状态的动作选择上,借用一个图:

虽然只有一点点差别,但是产生的影响需要细细品味。最直接的结果是SARSA更新的当前状态Q-value中反映了下一个状态包含的所有可能,或者说SARSA使得当前Q-value能够预知后续面对的奖励以及危险,而Q-learning则只专注于未来的奖励(因为使用max选择最优)。所以SARSA的策略总体而言更加保守,在这个例子里面要将Q-learning改为SARSA的话,只需将主函数中的几行代码稍作修改:
for i=1:episode_max
% 每次训练的初始化
step_counter = 0;
S = 0;
is_terminal = false;
A = choose_action(S, Q_table); % SARSA对初始状态采取的动作的初始化
while ~is_terminal
% 选择动作,更新状态,更新Q表
% A = choose_action(S, Q_table); % Q-learning采用的动作
[S_, R, flag] = get_env_feedback(S, A);
A_ = choose_action(S_, Q_table); % SARSA中对下一状态的动作选择
Q_predict = Q_table(S+1, A);
% 根据下一步是否是终点来更新flag参数以及Q值
if S_ ~= state_num - 1 && flag == 0
% 当下的reward加上下一步的discounted Q-value
% Q_target = R + Gama * max(Q_table(S_+1, :)); % Q-learning更新
Q_target = R + Gama * Q_table(S_+1, A_); % SARSA更新,下一状态采用A_
elseif flag == 1 % 撞墙了,直接终止
Q_table(S+1, A) = R;
break;
else
% 如果是终点就没有下一步,直接赋值
Q_target = R;
is_terminal = true;
end
Q_table_ = Q_table;
Q_table(S+1, A) = Q_table(S+1, A) + Alpha * (Q_target - Q_predict);
S = S_; % 更新状态量
A=A_; % 更新动作值,SARSA选择的下一动作-说到做到
step_counter = step_counter + 1;
end
if S==state_num - 1
fprintf('%d: Succeed! total step: %dn', i, step_counter);
elseif flag == 1
fprintf('%d: Danger, failed! total step: %dn', i, step_counter);
else
fprintf('nothing happenedn');
end
end
可以看出更新方式稍有差别,仿真结果如下:
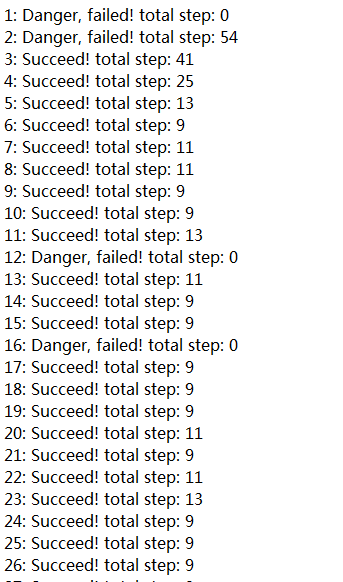
收敛速度也十分迅速,最重要的差别在于Q-table的值
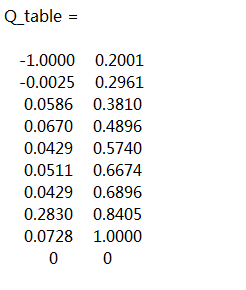
这里与Q-learning最大的差别在于,第二行第一列的Q-value是负数,这在Q-learning中是绝对不可能发生的,说明SARSA考虑到了状态0面临的潜在风险。二者表现出来的区别在这个例子中不够明显,后面会更新一个二维的迷宫探险,到时候二者的区别将会显而易见。
参考资料
- 莫烦python教程,https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/
- Busoniu, L., Babuska, R., De Schutter, B., & Ernst, D. (2010). Reinforcement learning and dynamic programming using function approximators (Vol. 39). CRC press.
最后
以上就是快乐短靴最近收集整理的关于强化学习(Reinforcement Learning)简单例子的Matlab代码实现——扫地机器人(Q-learning and SARSA)的全部内容,更多相关强化学习(Reinforcement内容请搜索靠谱客的其他文章。








发表评论 取消回复