不用强化学习工具箱的DQN算法案例与matlab代码(二)
DQN问题
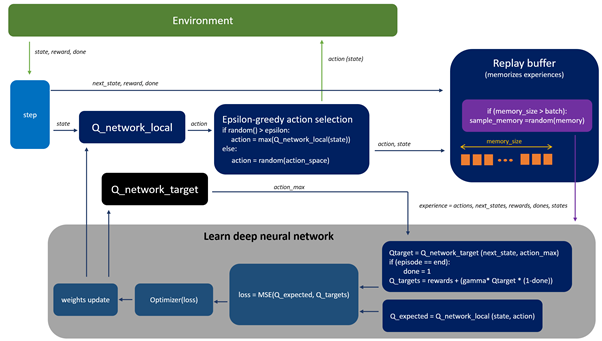
1.首先DQN与Q-learning算法区别:
MATLAB手动实现DQN最短路径问题
2.:为何为Q网络引入带有标签的数据
DQN问题解答比较好的网址,大家可以点进去好好看看
cartpole问题
环境设置:CartPole问题描述见链接。参数设置见代码。
奖励设置: 每一步给出的奖励为0,当满足norm(state(3),state(4))<0.01时,奖励为10;当杆子与竖直方向角度大于10或者移动范围大于10,奖励为-10;
状态设置: 随机初始化状态为 [-10*(1-2rand) -1.5(1-2rand) 0.17rand 0.1*rand];rand表示(0,1)之间的数。
动作设置: 0表示小车向左移动,1表示小车向右移动。
达到下列条件之一片段结束:
: 杆子与竖直方向角度超过10度
: 小车位置距离中心位置超过10
: 片段长度超过最大设定值
DQN部分代码分析
- 首先用fitnet函数搭建神经网络并初始化参数
layer1Size = 10;
layer2Size = 20;
obj.net = fitnet([layer1Size layer2Size],'trainlm');
obj.net_prev = obj.net;
obj.net.trainParam.lr = 0.1;
obj.net.trainParam.epochs = 10;
obj.net.trainParam.showWindow = true;
obj.net.trainParam.lr_dec = 0.8;
obj.net = train(obj.net,rand(length(obj.state),25),rand(length(obj.actions),25));
obj.netWeights = getwb(obj.net);
- 开始训练
function QLearningTrain(obj)
for epochs = 1:obj.maxEpoch
%Reset the parameters
obj.totalReward = 0;
obj.bonus = 0;
% Epsilon Decay
obj.epsilon = obj.epsilon*obj.epsilonDecay;
obj.randomInitState();见代码段环境中
% obj.state
for itr_no = 1:obj.maxIttr
cartForce = obj.selectAction();
[state,Action,reward,next_state,done] = obj.doAction(cartForce); % Propogate the Plant 见代码段环境中
obj.addtoReplaybuffer(state,Action,reward,next_state,done);
obj.state = next_state;
%Aggregating the Total Reward for every Epoch
obj.totalReward = obj.totalReward + reward;
if obj.resetCode
break;
end
end
% Store the Average Reward and Epoch Length for plotting
% the network Performance
obj.epochAvgReward(epochs) = obj.totalReward/itr_no;
obj.epochLength(epochs) = itr_no;
if itr_no == obj.maxIttr
disp(['Episode',num2str(epochs),':Successful Balance Achieved!- Average Reward:', num2str(obj.epochAvgReward(epochs)),'steps:', num2str(obj.epochLength(epochs))]);
elseif obj.resetCode == true
disp(['Episode',num2str(epochs),': Reset Condition reached!!!- Average Reward:', num2str(obj.epochAvgReward(epochs)),'steps:', num2str(obj.epochLength(epochs))]);
obj.resetCode = false;
end
obj.trainOnBuffer()
end
end
- 选择动作,采用softmax策略
function selectedAction = selectAction(obj)
if rand <= obj.epsilon
actionIndex = randi(obj.actionCardinality,1);
else
obj.Q = obj.genQvalue(obj.state);
[~,actionIndex] = max(obj.Q);
end
selectedAction = obj.actions(actionIndex);
end
- 从Buffer中选择批次数据进行训练
function trainOnBuffer(obj)
sampledrawfromBuffer = datasample(obj.replayBuffer,min(obj.sampleSize,length(obj.replayBuffer)));
stateBatch = sampledrawfromBuffer(:,[1:4]);
actionBatch = sampledrawfromBuffer(:,5);
rewardBatch = sampledrawfromBuffer(:,6);
nextstateBatch = sampledrawfromBuffer(:,[7:10]);
doneBatch = sampledrawfromBuffer(:,11);
valueBatch = zeros(length(obj.actions),1);
for count = 1:length(sampledrawfromBuffer)
value = obj.genQvalue(stateBatch(count,:));
aIdx = find(~(obj.actions-actionBatch(count)));
if doneBatch(count)
value(aIdx) = rewardBatch(count);
else
value(aIdx) = rewardBatch(count) + obj.gamma*max(obj.genQvalue(nextstateBatch(count,:)));
end
valueBatch(:,count) = value;
end
obj.net = setwb(obj.net,obj.netWeights);
obj.net = train(obj.net, stateBatch',valueBatch);
obj.netWeights = getwb(obj.net);
end
完成代码见上传的资源,随后更新代码资源
最后
以上就是忐忑菠萝最近收集整理的关于matlab手动实现基于DQNCartPole问题不用强化学习工具箱的DQN算法案例与matlab代码(二)的全部内容,更多相关matlab手动实现基于DQNCartPole问题不用强化学习工具箱内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复