目录
- 写在前面
- matlab强化学习库简介
- 航天器三轴姿态稳定器介绍
- 算法流程
- 代码/simulink
- 结果展示与分析
- 一些心得
- 写在最后
写在前面
%写在前面:
本人大四狗一名,不是计算机专业,所以这方面比较菜。最近在学习强化学习的一些算法,python更新太快,很多一两年前的学习资料就不太能用了,涉及到版本匹配和语法的更改等一系列问题。2020b的matlab中加入了DDPGTD3PPO等算法的强化学习算例和强化学习库,于是想用matlab来做强化学习。
由于本人是航空航天工程专业的,又和毕设有点联系,于是想试一下用强化学习算法学习一个姿态自稳定器,这个算例是根据matlab自带的双足机器人行走算例改造的,可能有的地方做的不好,如果写的哪里不对,还请各位大佬多多指教。
P.S.本文中调用的createDDPGAgent函数是双足机器人例子中的函数,需要先运行一下
openExample('control_deeplearning/TrainBipedRobotToWalkUsingReinforcementLearningAgentsExample')
在运行下面的程序就可以了。
matlab强化学习库简介
matlab在2020b中加入了几个强化学习算法的算例,对强化学习库进行了完善,让同学们可以自由使用。
matlab中的强化学习库是一系列封装好的函数,包括环境搭建、智能体搭建、训练函数、各种模型参数设置等众多函数。在matlab的官网可以查到各个函数的help,具体请各位移步:https://ww2.mathworks.cn/help/reinforcement-learning/referencelist.html?type=function
里面是matlab强化学习的各类函数介绍。
航天器三轴姿态稳定器介绍
此次算例给出的是航天器三轴姿态稳定控制器,模拟的场景是航天器三轴出现较小角度的偏差,加上航天器本身存在自转,造成航天器滚动轴和偏航轴出现耦合,控制输出力矩让航天器恢复稳定状态。
算例中用的此台动力学方程为航天器的线性化姿态动力学方程,取自西北工业大学出版社的《航天器控制原理》,周军编写的教材
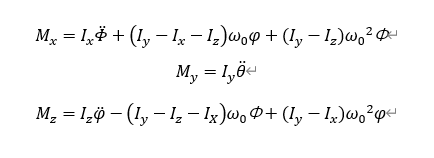
Mx,My,Mz就是三轴上的力矩,Ix,Iy,Iz就是三个惯性主轴的惯量,另外三个角度就对应滚动,俯仰,偏航的三个欧拉角。本文中采用w0为0.0011°/s,完成的是卫星对地定向,保持有效载荷对地造成的自转速度。每个轴的初始偏差为(-4°,4°)之间,初始角速度在(-0.2,0.2)之间,单位°/s最终控制到所有轴偏差与角速度之和小于0.3。如果能一直保持小于0.8也认为不错。
算法流程
和matlab给出的双足机器人行走算例流程一致,(因为就是基于此改造的),在simulink中调用RL Agent模块来搭建env和agent的关系,在m文件中调用train函数进行学习。我们要做的就是把程序所需要的附属函数写好,模块搭好。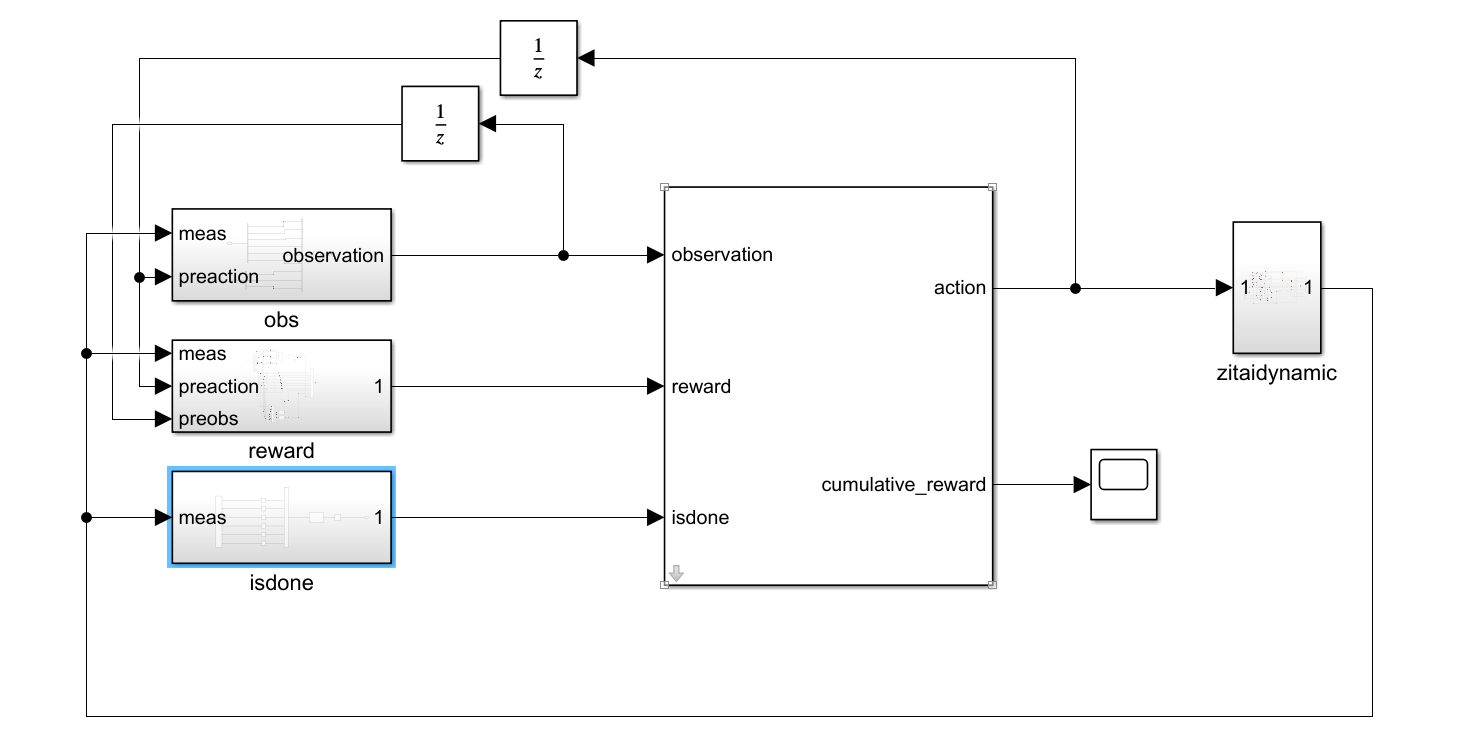
这是simulink中的整体布局。由agent根据现在的obs给出下一步的action,再有三轴姿态动力学给出积分一个步长以后的状态,我们给出这个状态的reward,agent再根据我们反馈的reward进行学习,在一定学习次数以后选择reward最高的方式给出action,到这里我们的学习就算完成了。用学好的agent就可以根据环境来进行动作了。
两个1/z模块是延时模块,用来找到上一时刻的动作和状态。
代码/simulink
在这里给出main函数和simulink中的主要模块。
w0=0.0011;
ts=1;%积分一次的步长
tf=40;%一个周期积分时间(经验回放一次)
ix=212;
iy=108;
iz=220;
dv=0.1;
fai=2*rand(1)-2*rand(1);
kesai=2*rand(1)-2*rand(1);
dotfai=dv*rand(1)-dv*rand(1);
dotseita=dv*rand(1)-dv*rand(1);
dotkesai=dv*rand(1)-dv*rand(1);
seita=(2*rand(1)-2*rand(1));
while 1%如果所有值得总和小于1,重新计算,直到大于等于1。
if abs(fai)+abs(kesai)+abs(dotfai)+abs(dotseita)+abs(dotkesai)+abs(seita)>1
break;
else
fai=(2*rand(1)-2*rand(1));
dotfai=dv*rand(1)-dv*rand(1);
dotseita=dv*rand(1)-dv*rand(1);
kesai=(2*rand(1)-2*rand(1));
dotkesai=dv*rand(1)-dv*rand(1);
seitai=(2*rand(1)-2*rand(1));
end
end
%进行数据的初始化,包括初始角度误差,初始角速度误差,惯性主轴大小和系转角速度大小等。
mdl='zitaidynamic';
open_system(mdl)
%打开simulink中的模型。
numobs=9;
obsInfo=rlNumericSpec([numobs 1]);
obsInfo.Name='observations';
%设置obs大小并占位。
numact=3;
actInfo=rlNumericSpec([numact 1],'LowerLimit',-10,'UpperLimit',10);
actInfo.Name='torque';
%设置action大小并占位。
blk=[mdl,'/RL Agent'];
env=rlSimulinkEnv(mdl,blk,obsInfo,actInfo);
env.ResetFcn=@(in)zitairesetfcn(in);
%用simulink中的RL Agent和之前占过的地儿来创建env。
agent=createDDPGAgent(numobs,obsInfo,numact,actInfo,ts);
%采用DDPG算法。
maxEpisodes=500;%训练500次,太多了时间太长,耗不起。500次以后已经收敛了。
maxSteps=floor(tf/ts);%一次最多积分多少步。
trainOpts=rlTrainingOptions(...
'MaxEpisodes',maxEpisodes,...
'MaxStepsPerEpisode',maxSteps,...
'ScoreAveragingWindowLength',250,...
'Verbose',false,...
'Plots','training-progress',...
'StopTrainingCriteria','EpisodeCount',...
'StopTrainingValue',maxEpisodes,...
'SaveAgentCriteria','EpisodeCount',...
'SaveAgentValue',maxEpisodes);
trainOpts.UseParallel = 0;
trainOpts.ParallelizationOptions.Mode = 'async';
trainOpts.ParallelizationOptions.StepsUntilDataIsSent = 32;
trainOpts.ParallelizationOptions.DataToSendFromWorkers = 'Experiences';
%设置训练的各种参数。
trainingStats = train(agent,env,trainOpts);%开始训练。
main函数中的参数调整我在上一篇博客中写的比较详尽,再次就不赘述了,有兴趣的朋友可以去https://blog.csdn.net/weixin_46322427/article/details/112008607看一看,能点个赞就更好了。
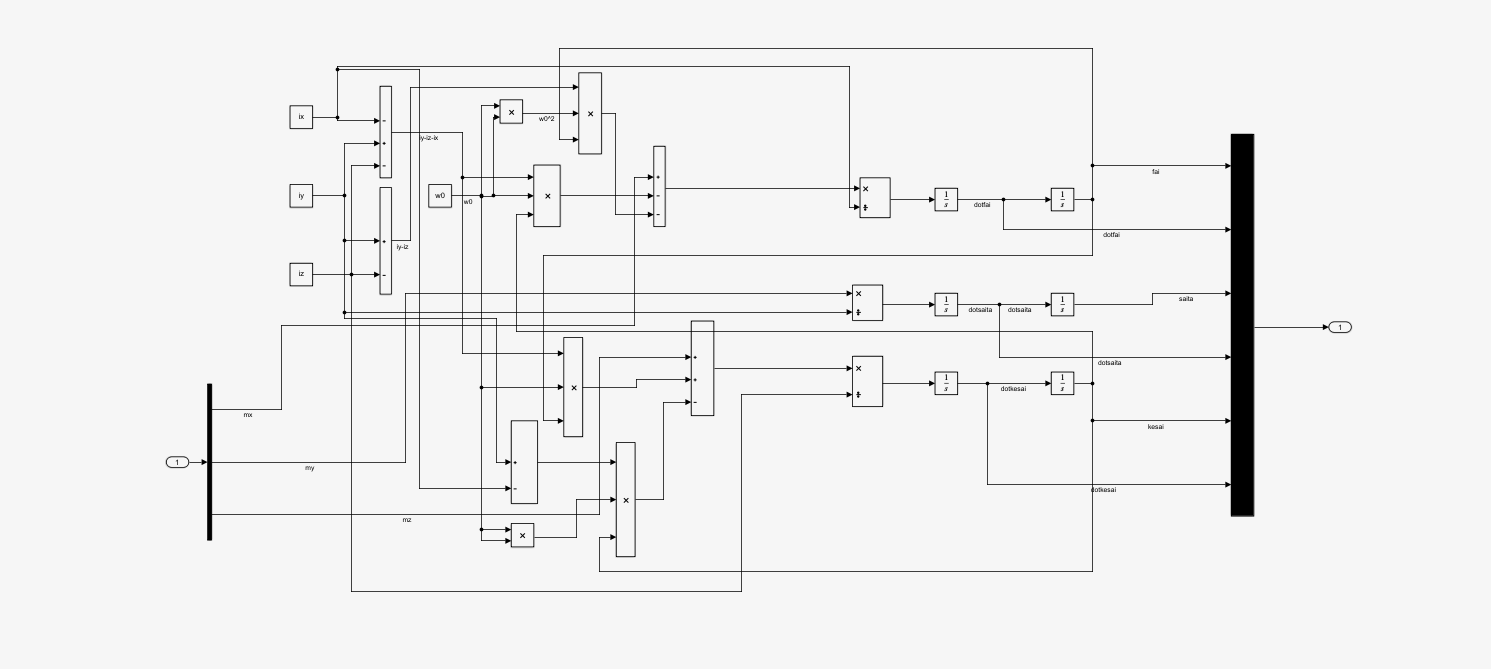
这是zitaidynamic的框图,就是上面写过的姿态动力学方程,由于是自己手搭的,没有很美化hhh。最后是把三个角度和三个角速度当成输出发了出去。
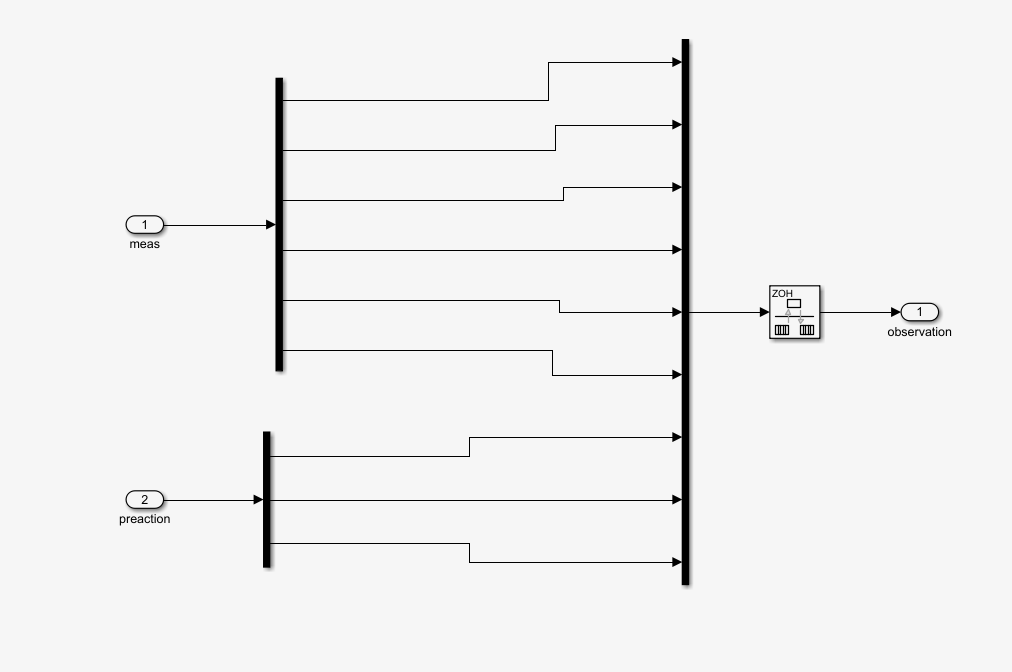 这是observation的框图,可见是把zitaidynamic的六维输出加上上一步骤的力矩并在一起为9维的数据当作obs,给到env中。
这是observation的框图,可见是把zitaidynamic的六维输出加上上一步骤的力矩并在一起为9维的数据当作obs,给到env中。
那个不太常用的模块是积分速率转换器,由于zitaidynamic中的积分步长是自定步长的(ode23mod)而env中的计算步长是ts,需要转换一下。
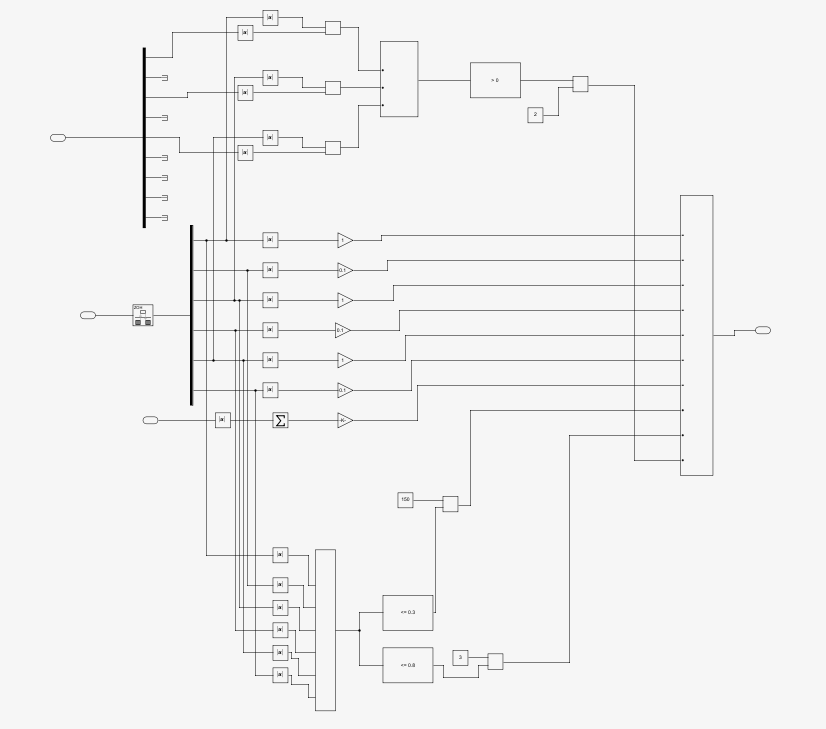 reward中的框图就比较麻烦了,在程序调试的过程中reward也是最麻烦的过程,让人头秃,我个人的一些心得会在下一个部分介绍。其实reward主要分为三部分,如下。
reward中的框图就比较麻烦了,在程序调试的过程中reward也是最麻烦的过程,让人头秃,我个人的一些心得会在下一个部分介绍。其实reward主要分为三部分,如下。
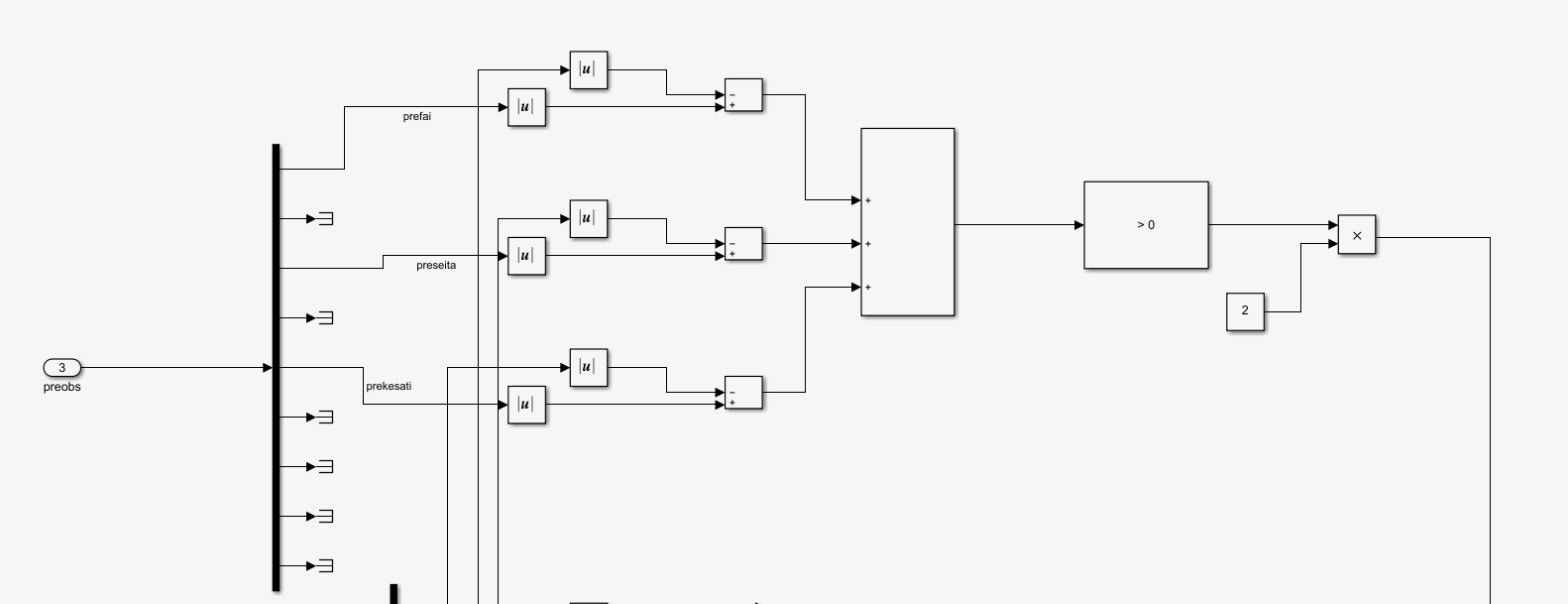 这一部分将preobs引入,是上一步的状态量,取它的第1,3,5,是三个角度量,和现在的obs进行对比,只要这一步骤比上一步骤绝对值之和要小,就给予奖励,这个奖励使得程序很快就能趋向于选取让角度减小的力矩值,不然程序自己随机选取很可能直接发散掉,这种奖励函数的选取一定程度上增强了稳定性。
这一部分将preobs引入,是上一步的状态量,取它的第1,3,5,是三个角度量,和现在的obs进行对比,只要这一步骤比上一步骤绝对值之和要小,就给予奖励,这个奖励使得程序很快就能趋向于选取让角度减小的力矩值,不然程序自己随机选取很可能直接发散掉,这种奖励函数的选取一定程度上增强了稳定性。
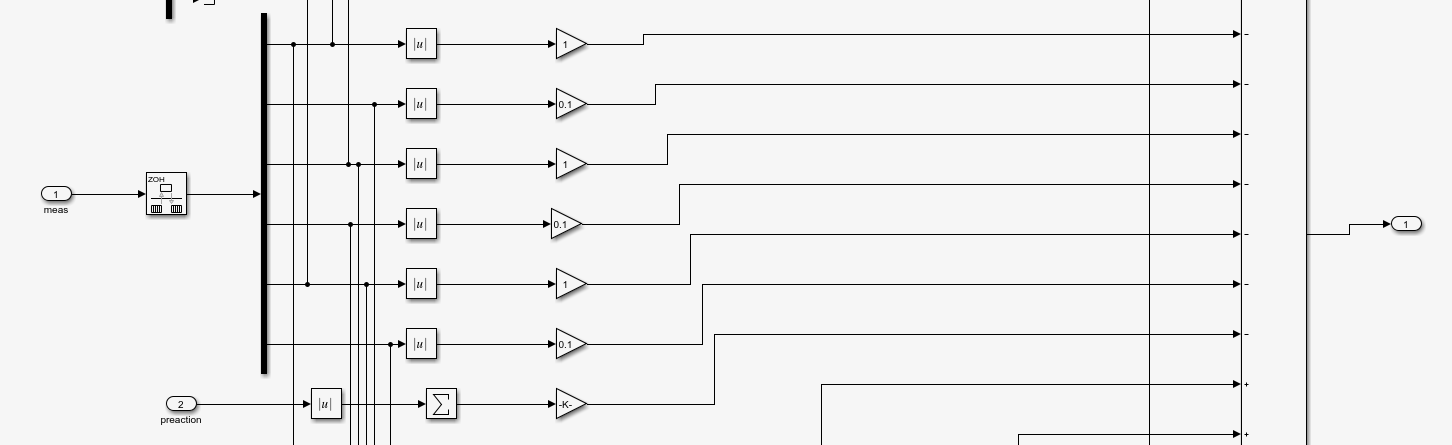
第二部分为所有的角度,角速度,力矩都是不好的,这些项都会给agent带来负的奖励,这激励着agent向完全稳定方向前进。
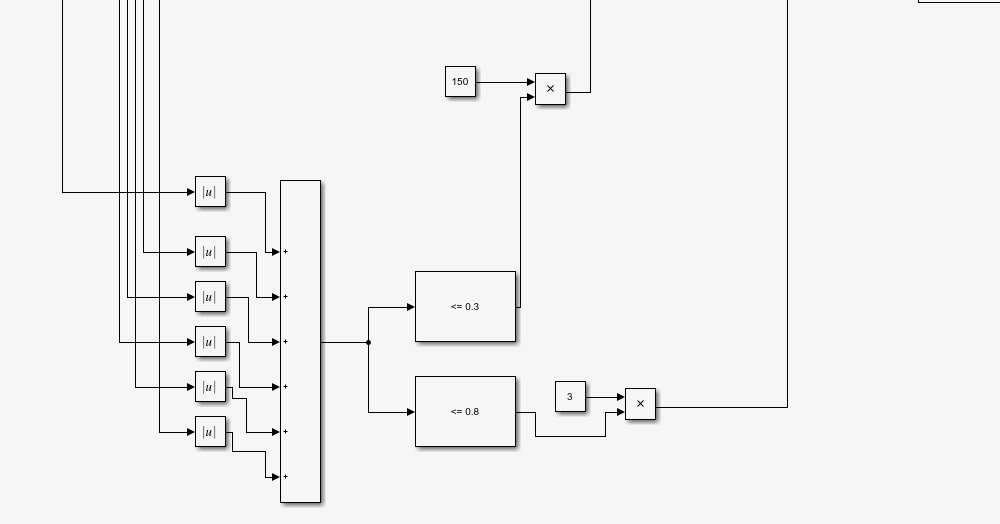 第三部分为完成任务后的奖励,可见六个值的绝对值之和小于0.8就会给出一个奖励,这让agent在后期都会收敛到0.8°之内,另外,当程序六个值之和小于0等于0.3都会有一个很大的奖励,让agent趋向于做出这样的动作。
第三部分为完成任务后的奖励,可见六个值的绝对值之和小于0.8就会给出一个奖励,这让agent在后期都会收敛到0.8°之内,另外,当程序六个值之和小于0等于0.3都会有一个很大的奖励,让agent趋向于做出这样的动作。
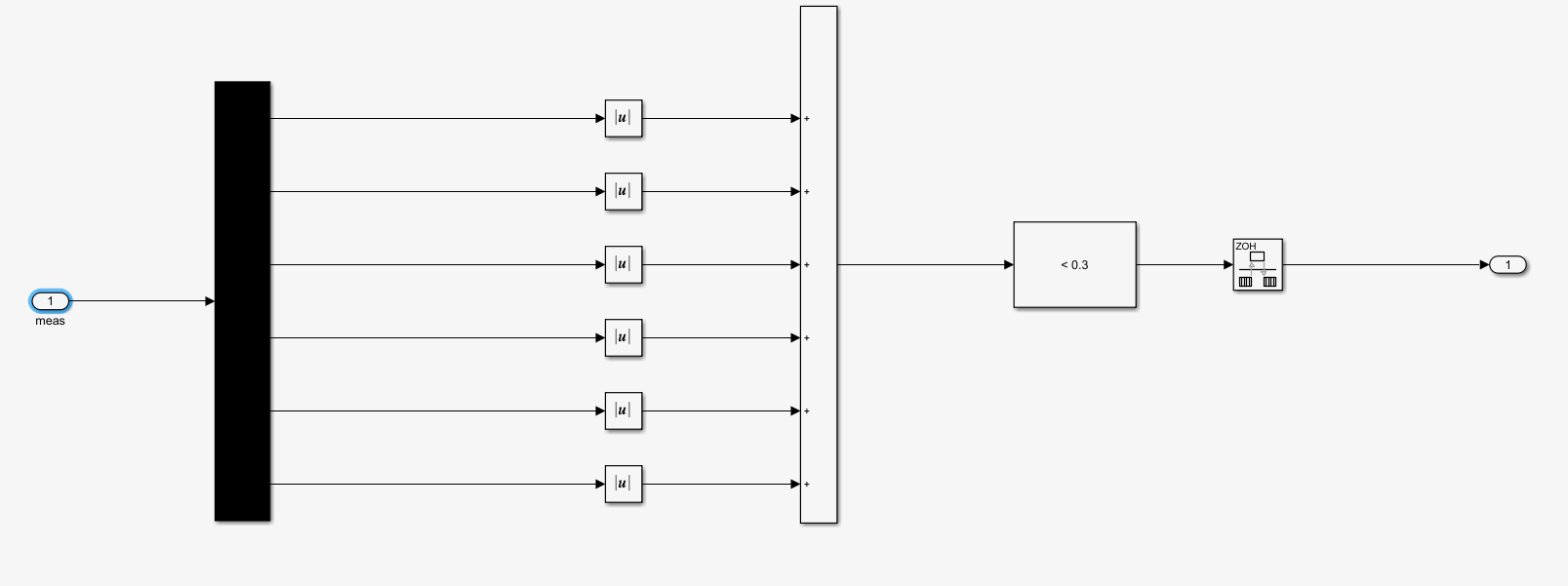
最后是isdone的搭建,如图,只有六个值绝对值之和小于0.3才能退出循环,这就使得agent只有超过最大时间或者完成目标两种方式退出循环,而只要在想错误的方向运动,reward就会给出负值,相当于给agent一个惩罚,所以这个操作也能加强系统稳定性。
完整代码和simulink可以在我的资源里找哦。
结果展示与分析
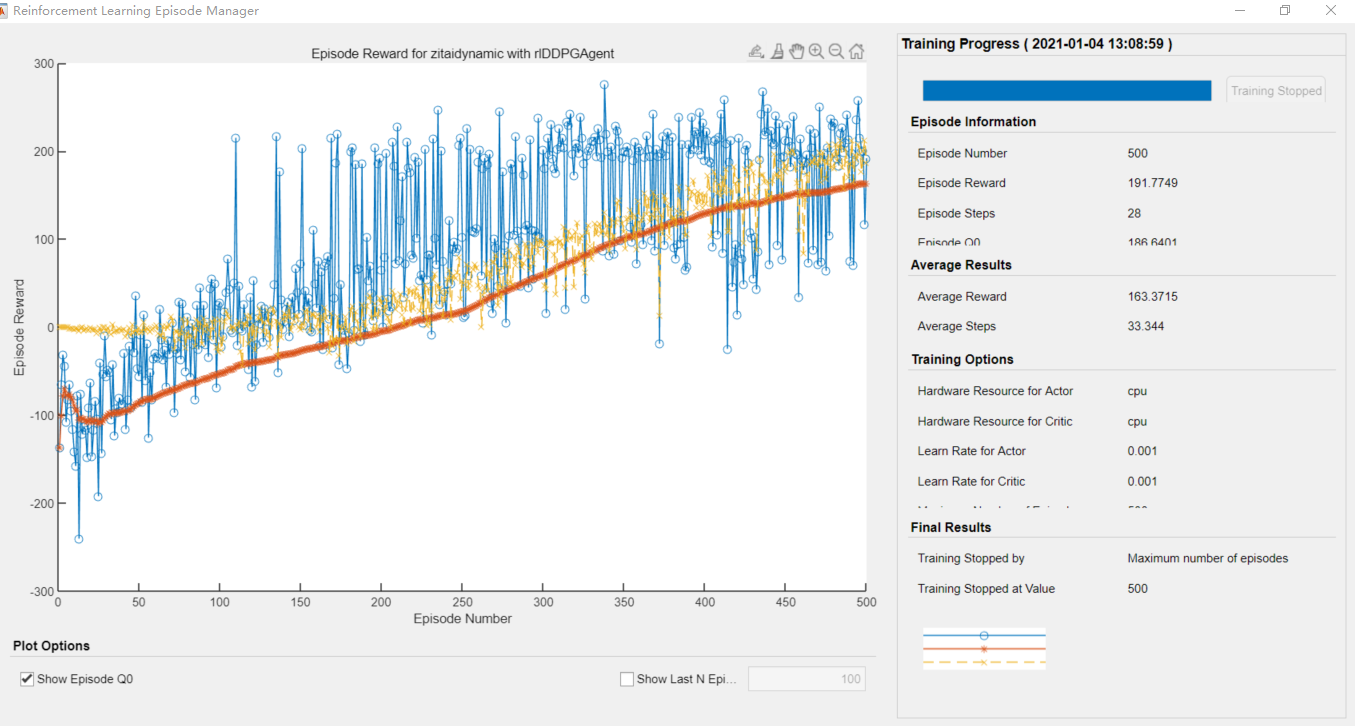 可见在100多次的学习之后,agent就可以达到0.3以内退出循环了,可以看到,最终收敛于达到目标0.3,退出循环。所有的学习过程分为三部分。
可见在100多次的学习之后,agent就可以达到0.3以内退出循环了,可以看到,最终收敛于达到目标0.3,退出循环。所有的学习过程分为三部分。
第一部分:随机取值,一百次之前,奖励是负的。
第二部分:开始收敛,可以达到0.8。
第三部分:可以达到0.3的推出条件。
这种递进是在奖励函数的编写时就应该想好的,不然很容易就发散掉了。
一些心得
最重要的就是奖励函数的编写,这玩意弄不好,出来的错误奇奇怪怪的。
还有isdone也要写好,我之前有一段时间,把isdone写成了如果角度错的太大也会退出,然后agent学了几次之后,还没有遇到正的反馈时就收敛到最快达到错误角度,受到最小的惩罚了,于是agent就疯了一样往扩大误差的方向跑,我一度怀疑这破电脑让我倒腾坏了。
另外,第一部分的奖励函数很重要,不然智能体很可能找不到自动控制在0.8之内获得奖励的方式,由于这个问题是一个三维非线性问题,耦合在一起,如果没有一个策略去鼓励它做正确的动作,他还是很傻的。
不过最后出结果还是很开心的,快乐地像个两百斤的胖子。
写在最后
水平有限,请有幸看到的您多多指正。在工作之余,祝您早安,午安,晚安。Have a nice day。
(可能的话点个赞再走吧)
P.S.完整程序在我的资源里找。博主还会不定时更新的,喜欢的话就收藏吧。
最后
以上就是精明狗最近收集整理的关于matlab强化学习DDPG算法改编/菜鸟理解2——航天器三轴姿态稳定器学习算例matlab强化学习库简介航天器三轴姿态稳定器介绍算法流程代码/simulink结果展示与分析一些心得写在最后的全部内容,更多相关matlab强化学习DDPG算法改编/菜鸟理解2——航天器三轴姿态稳定器学习算例matlab强化学习库简介航天器三轴姿态稳定器介绍算法流程代码/simulink结果展示与分析一些心得写在最后内容请搜索靠谱客的其他文章。








发表评论 取消回复