2021SC@SDUSC
特色垂类模型有两个模型 一个是车辆检测 一个是行人检测 查看源代码是痛苦的事 因此只看他的关键算法
基于Dacknet53的YOLOv3算法
darknet53一共53层卷积,除去最后一个FC(全连接层,实际上是通过1x1卷积实现的)总共52个卷积用于当做主体网络。
首先分析darknet53的网络结构
这52个卷积层是这样组成的:
首先是1个32个过滤器的卷积核,然后是5组重复的残差单元resblock_body(这5组残差单元,每个单元由1个单独的卷积层与一组重复执行的卷积层构成,重复执行的卷积层分别重复1次、2次、8次、8次、4次;在每个重复执行的卷积层中,先执行1x1的卷积操作,再执行3x3的卷积操作,过滤器数量先减半,再恢复),一共是52层。残差计算不属于卷积层计算。
52 = 1+ (1+1*2 ) + (1+2*2) + (1+8*2) + (1+8*2) + (1+4*2)
每组残差单元的第一个单独的卷积层操作均是一次步长为2的卷积操作,因此整个YOLO v3网络一共降维5次32倍,即:32=2^5,最后输出的特征图维度是13,即:13=416/32;最后1层的通道数是1024,最终的输出结构是(?, 13, 13, 1024)。所以,darknet53模型的输入是(?, 416, 416, 3),输出是(?, 13, 13, 1024)。
这个52层网络是这么定义的:
def darknet_body(x):
'''Darknent body having 52 Convolution2D layers'''
x = DarknetConv2D_BN_Leaky(32, (3, 3))(x)
x = resblock_body(x, num_filters=64, num_blocks=1)
x = resblock_body(x, num_filters=128, num_blocks=2)
x = resblock_body(x, num_filters=256, num_blocks=8)
x = resblock_body(x, num_filters=512, num_blocks=8)
x = resblock_body(x, num_filters=1024, num_blocks=4)
return x
其中,
(1)第1个卷积层DarknetConv2D_BN_Leaky,是这么定义的:
def DarknetConv2D_BN_Leaky(*args, **kwargs):
"""Darknet Convolution2D followed by BatchNormalization and LeakyReLU."""
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
LeakyReLU(alpha=0.1))
即:
(1.1)1个Darknet的2维卷积Conv2D层,即DarknetConv2D;
(1.2)1个批正则化层,将输入数据x进行正则化,即BatchNormalization();
(1.3)1个LeakyReLU层,斜率是0.1,LeakyReLU是在ReLU基础改进后的激活函数。
LeakyReLU的激活函数,如下图所示:
(2)Darknet的2维卷积DarknetConv2D,是这么定义的:
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
"""Wrapper to set Darknet parameters for Convolution2D."""
darknet_conv_kwargs = {'kernel_regularizer': l2(5e-4)}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides') == (2, 2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
即:
(2.1)将核权重矩阵的正则化,使用L2正则化,参数是5e-4,将核权重参数w进行正则化;
(2.2)Padding,一般使用same模式,只有当步长为(2,2)时,使用valid模式。避免在降采样中,引入无用的边界信息;
(2.3)其余参数不变,都与二维卷积操作Conv2D()一致。
(2.4)所谓2D卷积,就是横向和纵向均卷积,计算方式举例如下:
输入和核如下,没有padding,stride=1
输出为:将卷积核对应在input上,第一行对应算完,再算第二行,可以动手写一下。
14 = 4 * 1 + 3 * 0 + 1 * 1 + 2 * 2 + 1 * 1 + 0 * 0 + 1 * 0 + 2 * 0 + 4 * 1
6 = 3 * 1 + 1 * 0 + 0 * 1 + 1 * 2 + 0 * 1 + 1 * 0 + 2 * 0 + 4 * 0 + 1 * 1
6 = 2 * 1 + 1 * 0 + 0 * 1 + 1 * 2 + 2 * 1 + 4 * 0 + 3 * 0 + 1 * 0 + 0 * 1
12 = 1 * 1 + 0 * 0 + 1 * 1 + 2 * 2 + 4 * 1 + 1 * 0 + 1 * 0 + 0 * 0 + 2 * 1
这里所使用的Conv2D()函数,是Keras提供的二维卷积函数,在运算时会加载YOLO v3模型的各项参数(权重、偏置等)。比较简单的二维卷积函数,如:tf.nn.conv2d()函数运算的具体说明,可以参考:
https://blog.csdn.net/weixin_41943311/article/details/94570067
(3)残差网络resblock_body,是这么定义的:
def resblock_body(x, num_filters, num_blocks):
'''A series of resblocks starting with a downsampling Convolution2D'''
# Darknet uses left and top padding instead of 'same' mode
x = ZeroPadding2D(((1, 0), (1, 0)))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (3, 3), strides=(2, 2))(x)
for i in range(num_blocks):
y = compose(
DarknetConv2D_BN_Leaky(num_filters // 2, (1, 1)),
DarknetConv2D_BN_Leaky(num_filters, (3, 3)))(x)
x = Add()([x, y])
return x
即:
(3.1)ZeroPadding2D:填充x的边界为0,由(?, 416, 416, 32)转换为(?, 417, 417, 32)。因为下一步卷积操作的步长为2,所以图的边长需要是奇数;
(3.2)DarknetConv2D_BN_Leaky:DarkNet的2维卷积操作,核是(3,3),步长是(2,2),因此会导致特征尺寸变小,由(?, 417, 417, 32)转换为(?, 208, 208, 64)。由于num_filters是64,所以产生64个通道。
(3.3)compose:输出预测图y,功能是组合函数,先执行1x1的卷积操作,再执行3x3的卷积操作,过滤器数量先减半,再恢复,最后与输入相同,都是64;
(3.4)x = Add()([x, y]):残差操作,将x的值与y的值相加。残差操作可以避免,在网络较深时所产生的梯度弥散问题。
接下来
darknet53网络的输出
darknet53输出3个不同尺度的检测图,用于检测不同大小的物体。调用3次make_last_layers,产生3个检测图,即y1、y2和y3,如下图所示(图中,y1、y2和y3分别叫Predict one、Predict two和Predict three):
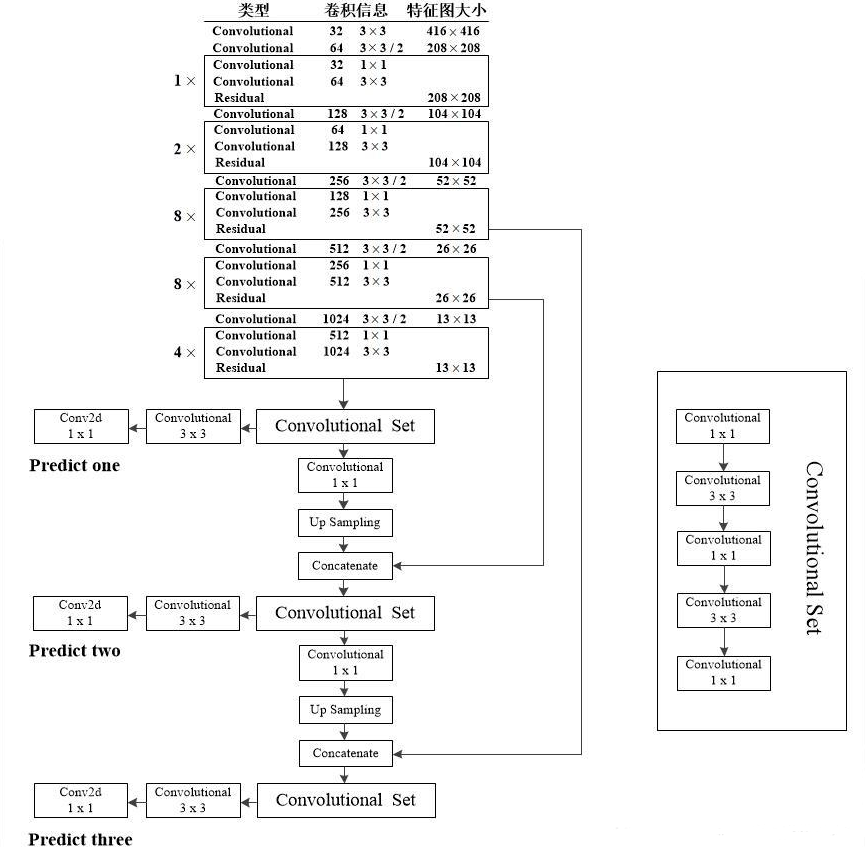
def yolo_body(inputs, num_anchors, num_classes):
"""Create YOLO_V3 model CNN body in Keras."""
darknet = Model(inputs, darknet_body(inputs))
x, y1 = make_last_layers(darknet.output, 512, num_anchors*(num_classes+5))
x = compose(
DarknetConv2D_BN_Leaky(256, (1,1)),
UpSampling2D(2))(x)
x = Concatenate()([x,darknet.layers[152].output])
x, y2 = make_last_layers(x, 256, num_anchors*(num_classes+5))
x = compose(
DarknetConv2D_BN_Leaky(128, (1,1)),
UpSampling2D(2))(x)
x = Concatenate()([x,darknet.layers[92].output])
x, y3 = make_last_layers(x, 128, num_anchors*(num_classes+5))
return Model(inputs, [y1,y2,y3])
其中,
(1)y1:输入是darnknet.output,shape是[?,13,13,1024],作为第1个make_last_layers()的输入,输出x的shape是[?, 13, 13, 512],输出y1的shape是[?, 13, 13, num_anchors*(num_classes+5) ]。
YOLOv3通过聚类算法得到了3组先验框(即:anchor box,预训练得到的默认边界框),目标检测器通过预测对数空间(log-space)变换来确定边界框。
YOLOv3 的先验框anchor box一共有3组共9个,由k-means聚类得到。在COCO数据集上,这9个先验框按不同尺寸特征图分组如下,每组3个:
13x13特征图对应:【(116*90),(156*198),(373*326)】
26x26特征图对应:【(30*61),(62*45),(59*119)】
52x52特征图对应:【(10*13),(16*30),(33*23)】
特征图越小,感受野越大,对大目标越敏感,选用大的anchor box;特征图越大,感受野越小,对小目标越敏感,选用小的anchor box。
所以,对于每一个特征图(featue map)而言,num_anchors是3,num_classes是检测类别的数量(比如:person、car、sports ball等,在YOLOv3提供的训练好的模型中,num_classes = 80)。
5 = 4+1,4为边界框中心点坐标(x , y)、宽w 和高h ;1为置信度。
(2)y2:输入是(x,y1)输出的x,shape是[?, 13, 13, 512]。先执行一次有256个滤波器(所以,输出是256个通道)的1x1卷积操作DarknetConv2D_BN_Leaky();然后做一次上采样操作UpSampling2D(),将输入为13x13的结构,转换为26x26的结构。将x与darknet的第152层拼接Concatenate(拼接后张量的shape是[?, 26, 26, 768]),作为第2个make_last_layers()的输入,输出x的shape是[?, 26, 26, 256],输出y2的shape是[?, 26, 26, num_anchors*(num_classes+5) ]。
(3)y3:输入是(x,y2)输出的x,shape是[?, 26, 26, 256]。先执行一次有128个滤波器(所以,输出是128个通道)的1x1卷积操作DarknetConv2D_BN_Leaky();然后做一次上采样操作UpSampling2D(),将输入为26x26的结构,转换为52x52的结构。将x与darknet的第92层拼接Concatenate(拼接后张量的shape是[?, 52, 52, 384]),作为第3个make_last_layers()的输入,输出x忽略,输出y3的shape是[?, 52, 52, num_anchors*(num_classes+5) ]。
最后,根据整个逻辑的输入和输出,构建模型Model(inputs,[y1,y2, y3]):输入inputs为(?, 416, 416, 3),输出为3个尺度的预测层,即[y1, y2, y3]。其中,y2、y3比y1更适用于发现尺寸比较小的物体。
Model是Keras中最主要的数据结构之一,该数据结构定义了一个完整的图。因此,在这篇文章中,所有的描述都是在讲解darknet53这个神经网络的结构和数据流动的路径,而不是在具体执行一个函数或一段程序,这样就比较容易理解这里的每一个DarknetConv2d()函数的输入为什么只有输入张量,而不需要每次匹配对应的卷积核(因为训练好的卷积核会通过load_weights方法加载到Model中,并与每一个卷积计算相匹配)。
make_last_layers()的函数如下所示,是一组连续的2D卷积操作,先执行5次DarknetConv2D_BN_Leaky()卷积操作,返回x;然后再执行1次DarknetConv2D_BN_Leaky()卷积操作和1次不含BN和Leaky的1x1的卷积操作DarknetConv2D()(作用类似于全连接操作),返回y。
def make_last_layers(x, num_filters, out_filters):
'''6 Conv2D_BN_Leaky layers followed by a Conv2D_linear layer'''
x = compose(
DarknetConv2D_BN_Leaky(num_filters, (1,1)),
DarknetConv2D_BN_Leaky(num_filters*2, (3,3)),
DarknetConv2D_BN_Leaky(num_filters, (1,1)),
DarknetConv2D_BN_Leaky(num_filters*2, (3,3)),
DarknetConv2D_BN_Leaky(num_filters, (1,1)))(x)
y = compose(
DarknetConv2D_BN_Leaky(num_filters*2, (3,3)),
DarknetConv2D(out_filters, (1,1)))(x)
return x, y
作为初学者,这里有一个额外的有意思的问题,按照前图,26x26尺寸的卷积运算的输出应该是darknet53的第43层卷积层,即:
43 = 1+ (1+1*2 ) + (1+2*2) + (1+8*2) + (1+8*2)
为什么在yolo_body()的定义里,却使用下面的语句来定义拼接操作呢?
x = Concatenate()([x,darknet.layers[152].output])
原来,Model(inputs, [y1,y2,y3]) 所定义的卷积神经网络,darknet53只是按照53层卷积运算的主体来命名的,而在实际的Model模型中,残差操作add、批正则化batch_normalization、leaky_re_lu、zero_padding2d、拼接操作concatenate、上采样up_sampling2d等与conv2d一样都是要计入层数(layers)的,并且每一层都有不同的名字和序号。按照这样的定义,每个DarknetConv2D结构的层数是1,每个DarknetConv2D_BN_Leaky结构的层数是3,每个resblock_body结构的层数是4+7*num_blocks(num_blocks为循环次数),则26x26尺寸的卷积运算的输出实际上是darknet53的第152层:
152 = 3+(4+7)+(4+7*2)+(4+7*8)+(4+7*8)
同时,每个make_last_layers结构共有6*3+1=19层,加上1个输入层input,因此整个darknet53一共有252层:
252 = 1+ 3+(4+7)+(4+7*2)+(4+7*8)+(4+7*8)+(4+7*4)+19+5+19+5+19
最后
以上就是开心龙猫最近收集整理的关于PaddleDetection算法分析(2)的全部内容,更多相关PaddleDetection算法分析(2)内容请搜索靠谱客的其他文章。
![[深度学习][原创]旋转目标检测框架yolov5_obb,paddledetection-s2anet和mmrotate谁最好用?](https://www.shuijiaxian.com/files_image/reation/bcimg18.png)







发表评论 取消回复