目录
- Task2 数据分析
- 1. 内容
- 2. 代码
- 2.1 所需的库
- 2.2 读取数据集
- 2.2.1 导入训练集train.csv、测试集testA.csv数据
- 2.2.2 查看数据首尾数据情况
- 2.3 总览数据概况
- 2.3.1 获取train数据的相关统计量
- 2.3.2 获取train数据类型
- 2.3.3 获取testA数据的相关统计量
- 获取testA的数据类型
- 2.4 判断数据缺失和异常
- 2.4.1 查看trian和testA每列的存在nan情况
- 2.5 了解预测值的分布
- 2.5.1 预测值的分布
- 3.5.2 查看skewness(偏态) and kurtosis(峰度)
- 2.5.3 查看预测值的具体频数
- 2.6 用pandas_profiling生成数据报告
Task2 数据分析
1. 内容
- 使用数据科学库和可视化库
- pandas、numpy、sicpy
- matplotlib、seaborn、pycharts
- 数据类型处理
- 缺失值和异常值处理
- 查看每一列的nan情况
- 异常值检测
- 了解预测值的分布情况
- 总体分布情况
- skewness and kurtosis
- 预测值的具体频数
2. 代码
2.1 所需的库
import numpy as np
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
import warnings
warnings.filterwarnings('ignore')
2.2 读取数据集
2.2.1 导入训练集train.csv、测试集testA.csv数据
train = pd.read_csv('./train.csv')
test = pd.read_csv('./testA.csv')
2.2.2 查看数据首尾数据情况
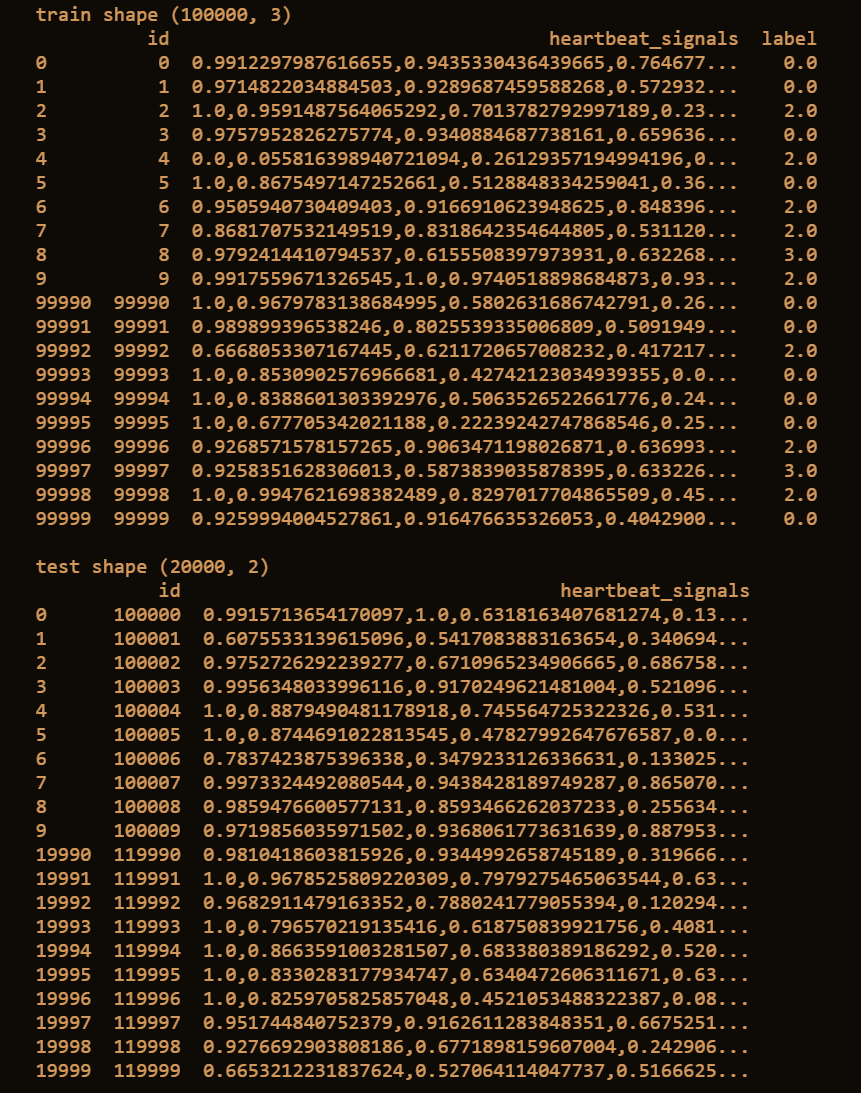
print("train shape", train.shape)
print(train.head(10).append(train.tail(10)))
print("test shape", test.shape)
print(test.head(10).append(test.tail(10)))
运行结果
2.3 总览数据概况
- describe种有每列的统计量,观察数据是否异常值和缺失值。比如分位数值相差太大则有异常值,或发现999 9999和-1 等值则有缺失值。
- info 通过info来了解数据每列的type,也可以查看列是否有缺失值。
2.3.1 获取train数据的相关统计量
print(train.describe([0.01, 0.05, 0.1, 0.25, 0.5, 0.85, 0.9, 0.95, 0.99]))
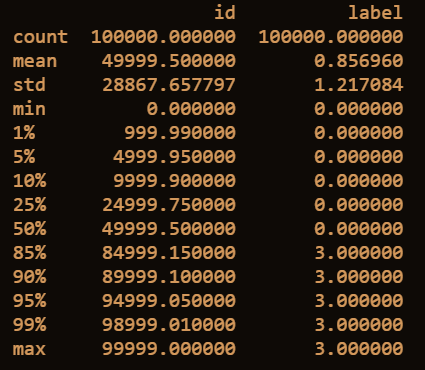
2.3.2 获取train数据类型
print(train.info())
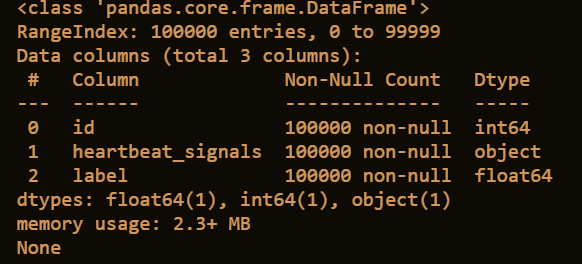
2.3.3 获取testA数据的相关统计量
print(test.describe([0.01, 0.05, 0.1, 0.25, 0.5, 0.85, 0.9, 0.95, 0.99]))
运行结果:
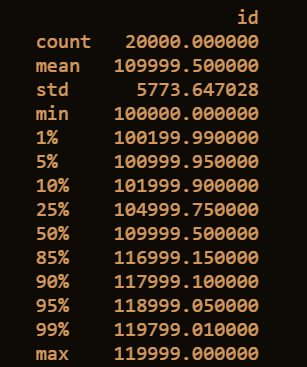
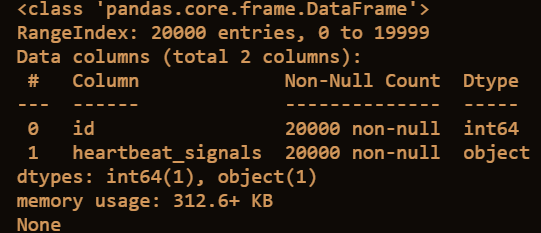
获取testA的数据类型
print(test.info())
运行结果:
2.4 判断数据缺失和异常
data.isnull().sum()查看每列的nan情况
2.4.1 查看trian和testA每列的存在nan情况

2.5 了解预测值的分布
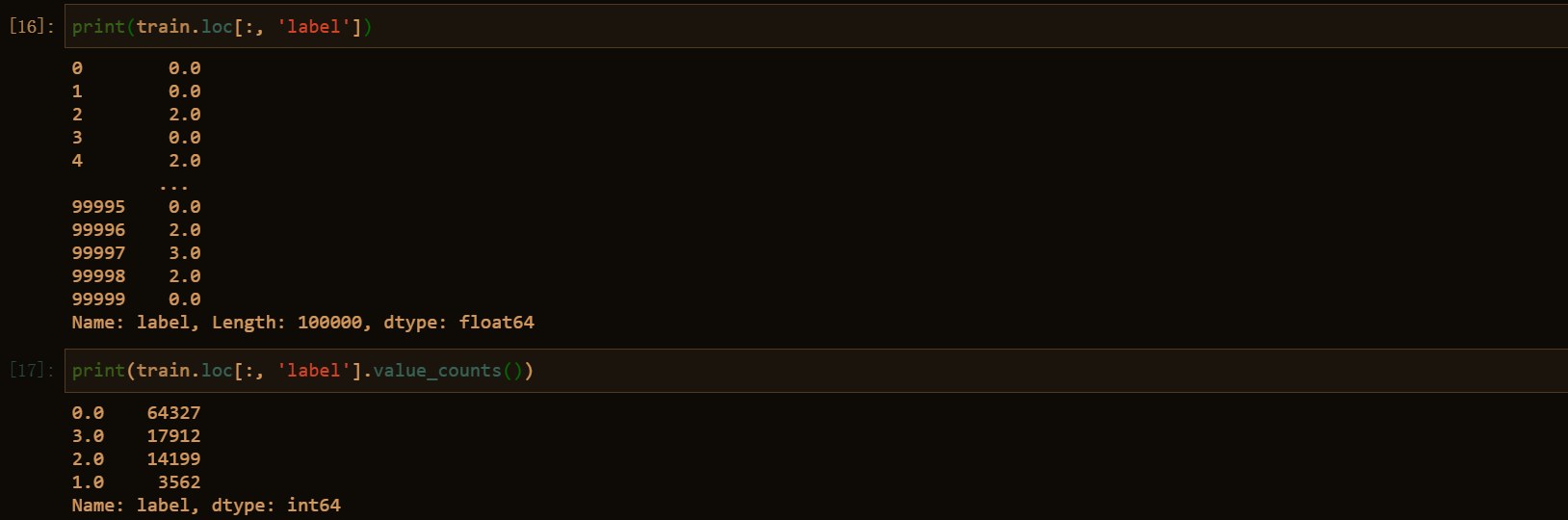
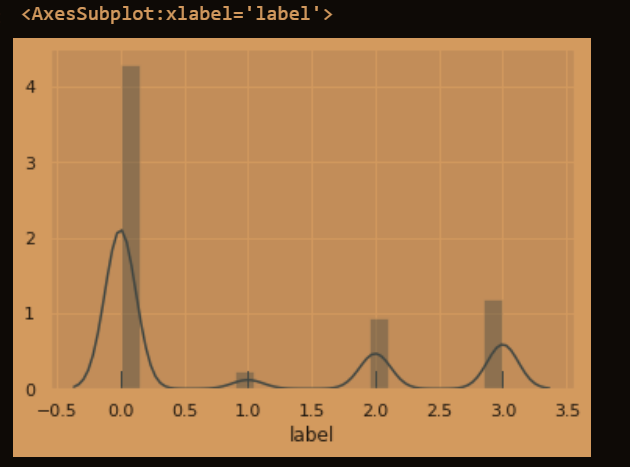
2.5.1 预测值的分布
sns.set(color_codes=True)
y = train.loc[:, 'label']
plt.figure(1)
sns.distplot(y, rug=True, bins=20)
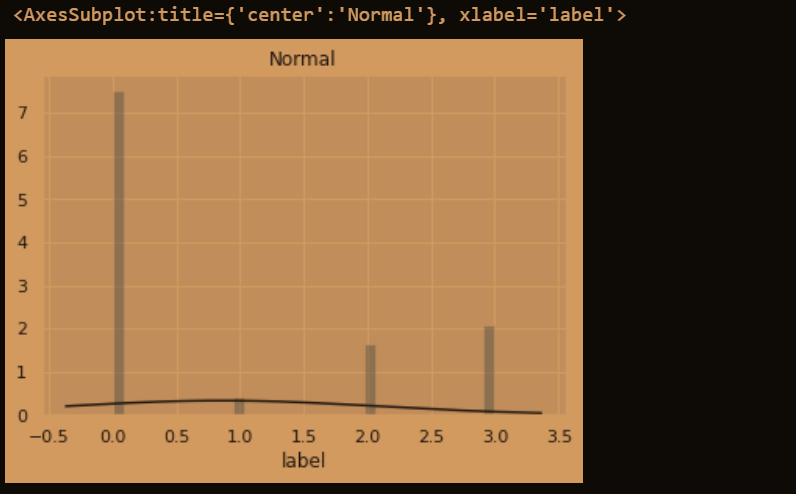
plt.figure(2); plt.title('Normal')
sns.distplot(y, kde=False, fit=stats.norm)
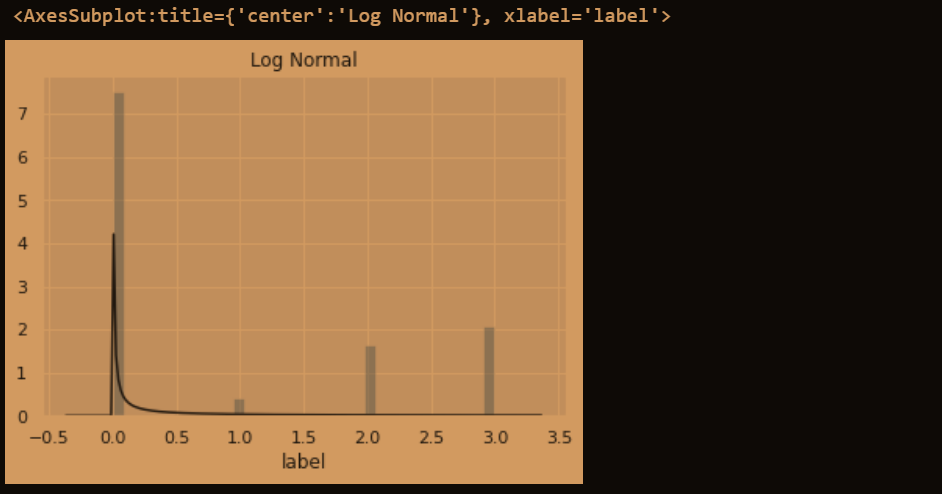
plt.figure(3); plt.title('Log Normal')
sns.distplot(y, kde=False, fit=stats.lognorm)
3.5.2 查看skewness(偏态) and kurtosis(峰度)
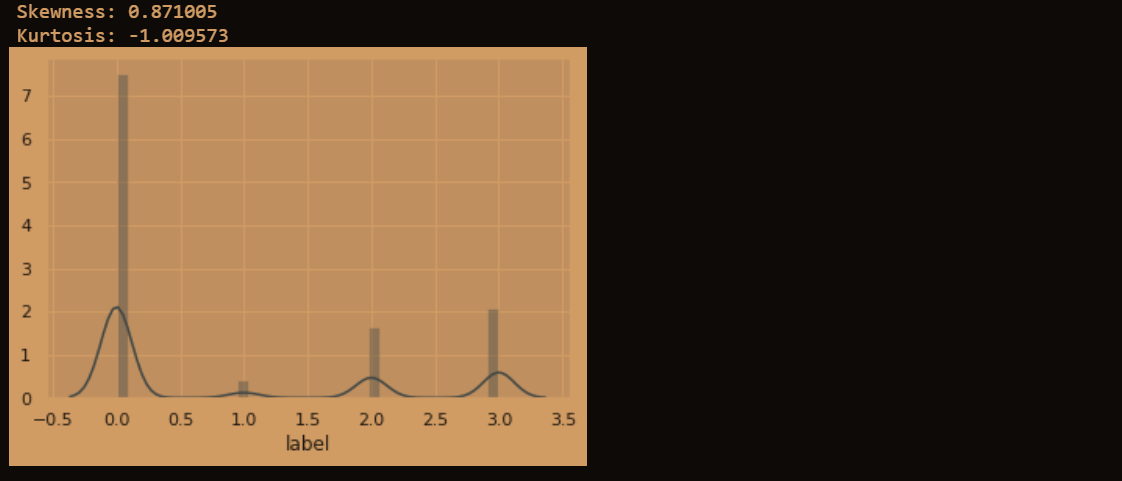
偏度能够反应分布的对称情况,右偏(也叫正偏),表现为数据右边脱了一个长长的尾巴,这时大多数值分布在左侧,有一小部分值分布在右侧。
峰度反应的是图像的尖锐程度:峰度越大,表现在图像上面是中心点越尖锐。在相同方差的情况下,中间一大部分的值方差都很小,为了达到和正太分布方差相同的目的,必须有一些值离中心点越远,所以这就是所说的“厚尾”,反应的是异常点增多这一现象。
sns.distplot(train['label']);
print("Skewness: %f" % train['label'].skew())
print("Kurtosis: %f" % train['label'].kurt())
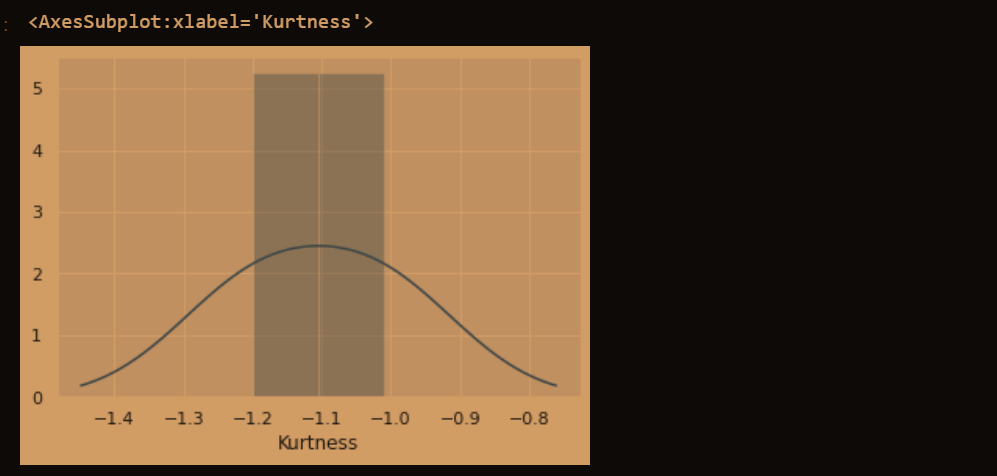
sns.distplot(train.kurt(), axlabel ='Kurtness')
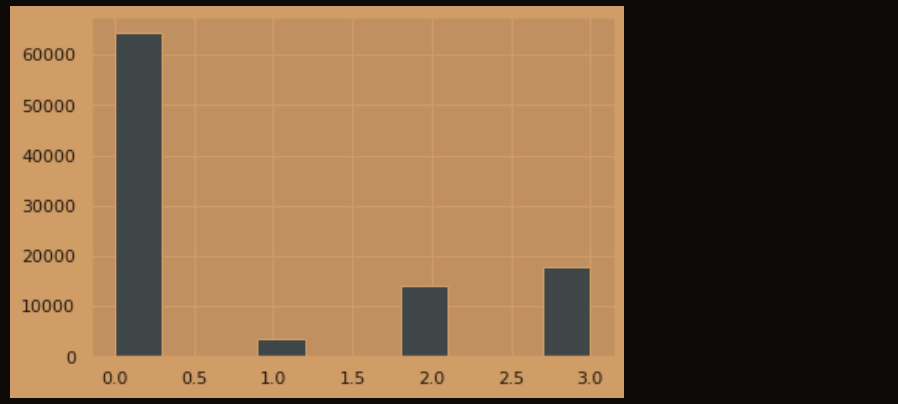
2.5.3 查看预测值的具体频数
plt.hist(train['label'], orientation = 'vertical',histtype = 'bar', color ='red')
plt.show()
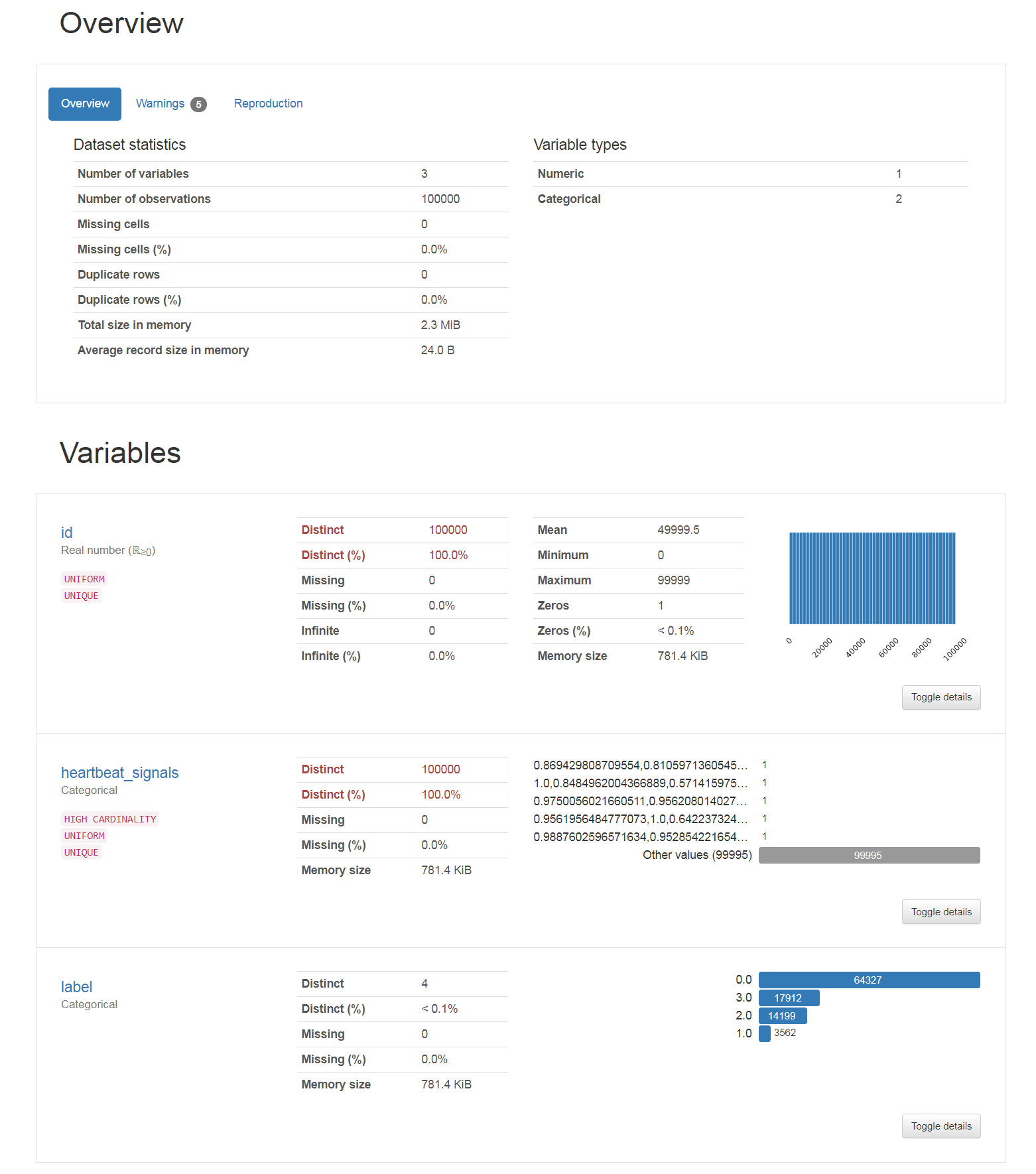
2.6 用pandas_profiling生成数据报告
import pandas_profiling
pr = pandas_profiling.ProfileReport(train)
pr.to_file("./report.html")
最后
以上就是平淡羽毛最近收集整理的关于心电图心跳分类(二)--EDATask2 数据分析的全部内容,更多相关心电图心跳分类(二)--EDATask2内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复