一、前言
在讲网络协议栈前,先理解一个数据包在网络传输是一个怎么样的流程,如下图所示。
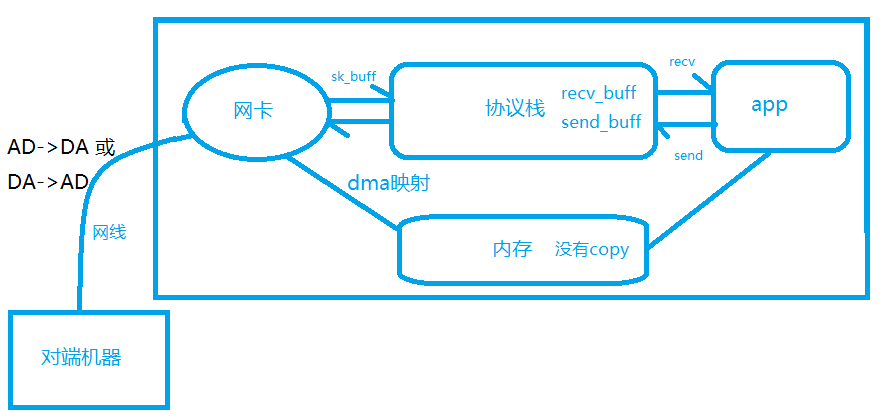
正常的流程是网卡接收到数据后,把数据copy到协议栈(sk_buff),协议栈把sk_buff数据解析完后再把数据放到recv_buff,此时应用程序调用recv把数据从协议栈copy到应用程序;发送数据包,则与之相反,应用程序调用send把数据包copy到send_buff,协议栈从send_buff取数据放到sk_buff,交给网卡发送出去。这个过程有多次拷贝,为避免多次拷贝,使用dma的方式(零拷贝),把网卡的数据直接映射到内存,再由应用程序访问内存。
二、数据包分析
从网卡接收到一帧完整的数据包,可以使用原生的socket、netmap、dpdk等,完整的一帧数据由以太网头、IP头、tcp/udp头、用户数据构成,这些层级涉及到7层网络模型OSI,如udp协议分布到7层OSI如下图所示。
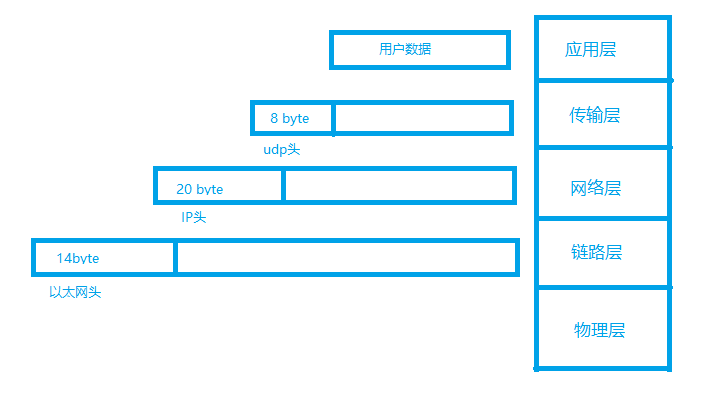
由上图可知,以太网头属于链路层、IP头属于网络层、UDP头属于传输层,而实际的用户数据在应用层。
(1)以太网头
以太网头分布如下图所示。

对应结构体如下,由此可知MAC地址存在以太网头。
#define ETH_LEN 6
//14字节以太网头---->链路层---->MAC地址,
struct ethhdr{
unsigned char dst[ETH_LEN];//6字节 目的地址即MAC地址
unsigned char src[ETH_LEN];//6字节 源地址
unsigned short proto;//2字节 协议类型,形容网络层使用的协议
}
//在计算上没有那个固件叫MAC地址,IP地址、端口
//所谓的MAC地址,IP地址、端口只不过是协议栈里面一个字段名而已,不要与固件捆绑(2)IP头
IP头结构如下图所示。
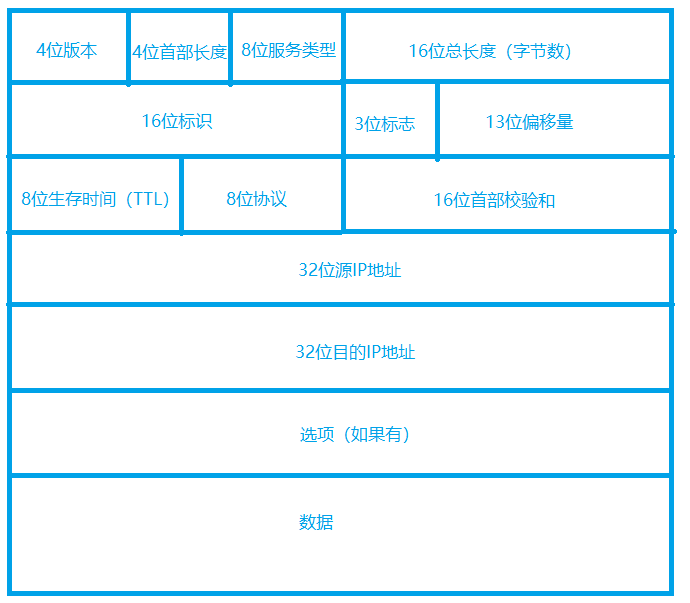
其数据结构如下所示,IP地址在IP头中,属于网络层。
//iphdr(ip头)---->网络层--->IP地址
struct iphdr{
unsigned char version:4,//4位版本
hdrlen:4;//4位首部长度
unsigned char tos;//8位服务类型
unsigned short totlen;//16位总长度,有65535也就是说一次可传64k,注意MTU是1500这是网卡的限制,在网卡传输数据是它会分片发送,一个片就是一个MTU
unsigned short id;//16位标识,每一个数据包都有一个id,与tcp里面的seq num没有关系
unsigned short flag:3,
offset:13;
unsigned char ttl;// ttl = 64 - 路由数量/网关,当ttl为0,就会返回无法访问目标地址,不可达
unsigned char proto;//8位协议类型,形容传输层使用什么协议
unsigned short check;//16位首部校验和,计算的是首部的校验和,计算校验前一定要赋值为0,再计算,否则接收端无法收到数据
unsigned int sip;//源ip
unsigned int dip;//目的ip
}(3)协议头
该层涉及到具体的不同协议,就有不同的结构,本文主要分析udp和tcp
(a)udp 协议结构如图所示。

其数据结构如下,由此可知端口在协议头里面,属于传输层。
//udp头(8个字节头)---->传输层--->端口
struct udphdr{
unsigned short sport;//源端口
unsigned short dport;//目的端口
unsigned short length;//长度
unsigned short check;//校验和
}(b) tcp 协议头如图所示。
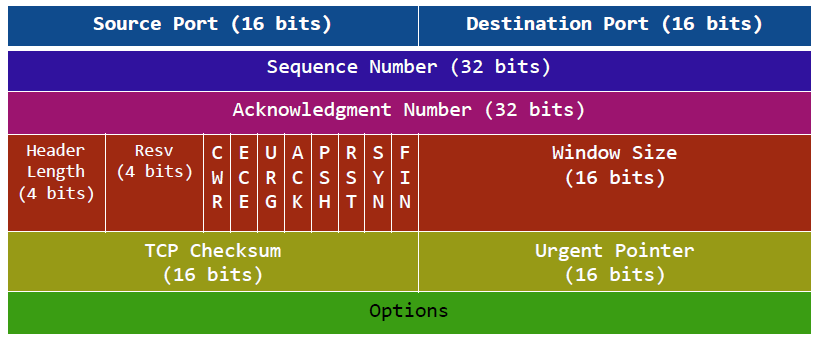
其数据结构如下,属于传输层。
struct tcphdr{
unsigned short sport;//源端口
unsigned short dport;//目的端口
unsigned int seqnum;//序号:包的序号,唯一id,随机起始值,之后就递增
unsigned int acknum;
unsigned char hdrlen:4,//头长度
resv:4;//保留位
//以下的标识置1,对应的字段有效
unsigned char cwr:1,
ece:1,
urg:1,
ack:1,
psh:1,
rst:1,
syn:1,
fin:1;
unsigned short win;//窗口大小
unsigned short check;
unsigned short urg_pointer;
}(c)arp和icmp
arp和icmp头定义如下。
//arp_head
struct arphdr {
unsigned short h_type;
unsigned short h_proto;
unsigned char h_addrlen;
unsigned char protolen;
unsigned short oper;
unsigned char smac[ETH_ALEN];//源mac
unsigned int sip;//源ip
unsigned char dmac[ETH_ALEN];//目的mac
unsigned int dip;//目的ip
};
//icmp_head
struct icmphdr {
unsigned char type;
unsigned char code;
unsigned short check;
unsigned short identifier;
unsigned short seq;
unsigned char data[32];
};arp是地址解析协议,在局域网中,每一台主机都会对局域网内每一台机器进行广播arp包,当收到对端主机arp请求包后,把本机的IP和MAC地址做为响应发送回请求方,发出请求的主机便可获得整个局域网内所有主机的IP和MAC地址,并保存到arp表中,记录着局域网所有机器的IP和MAC地址信息;当arp表中某台机器的arp信息超时后,就会从arp表中删除,导致收不到数据;所以在局域网内网络通信看似是通过IP,其实是通过MAC地址。
ICMP是Internet控制报文协议,在命令行上ping + IP地址,此时发送的就是向目标主机发送ICMP请求,目标主机收到ICMP求情后,就会响应ICMP,表明两台主机的网络是畅通的。
相关视频推荐
手写一个用户态网络协议栈,瞬间提升你网络功底
100行源代码搞定用户态协议栈
用户态协议栈—uio,数据帧,协议栈
C/C++Linux服务器开发高级架构师/C++后台开发架构师免费学习地址
另外还整理一些C++后台开发架构师 相关学习资料,面试题,教学视频,以及学习路线图,免费分享有需要的可以自行添加:Q群720209036~点击加入 需要自取
由以上每个协议头的定义,得到udp、tcp、arp、icmp它们的协议packet可定义如下。
struct arppkt {
struct ethhdr eh;
struct arphdr arp;//arp头属于网络层,与IP头同一层
};
struct icmppkt {
struct ethhdr eh;
struct iphdr ip;
struct icmphdr icmp;
};
struct udppkt {
struct ethhdr eh;//14
struct iphdr ip;//20
struct udphdr udp;//8
//用户数据,柔性数组相当于一个标签,指向用户数据的首地址
unsigned char payload[0];//柔性数组,使用条件:1.内存已经分配好,2.柔性数组的长度可以通过其它方法计算出来
};
//sizeof(udppkt) = 44,为啥不是42,因为结构体设置了是以1个字节对齐,导致有一个地方有2个字节的空窗期
struct tcppkt {
struct ethhdr eh;
struct iphdr ip;
struct tcphdr tcp;
unsigned char payload[0];
};三、深入理解网络协议栈
从网络协议栈是如何实现tcp连接、传输数据、断开连接,经过这3个方面加深对网络协议栈了解。
(1)三次握手
tcp三次握手流程图如下。
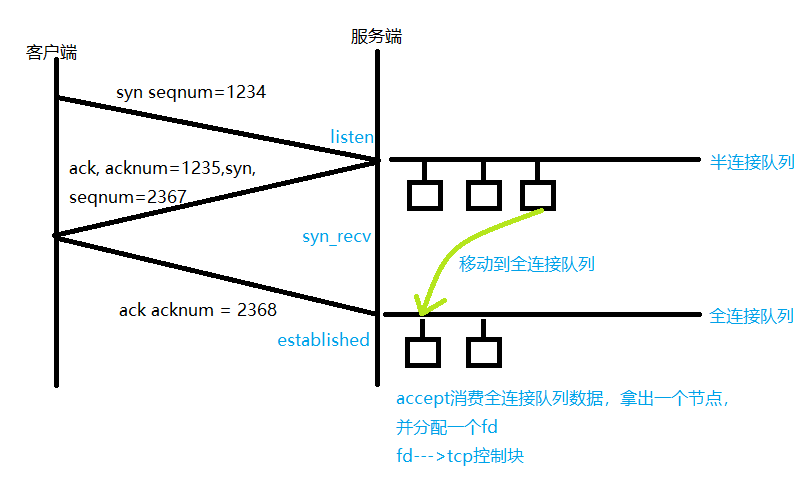
客户端发送syn包开始第一次握手,服务端收到syn后完成第一次握手;服务端发送ack包开始第二次握手,acknum等于第一次握手seqnum+1,客户端收到ack后完成第二次握手,客户端发送ack开始第三次握手,acknum等于第二次握手seqnum+1,服务端收到ack后完成第三次握手。
第一次握手完成时,服务端从IP头、TCP头获取到源IP、目的IP、源端口、目的端口、协议等信息构成五元组,存到半连接队列节点中;当第三次握手完成,遍历半连接队列找到对应的节点,并把节点移动到全连接队列中,应用层调用accept消费全连接队列数据,并分配fd,全连接队列每个节点可以叫tcp控制块,fd与tcp控制块一一对应。
在三次握手过程中存在3个状态(状态机):
(a)listen:服务器处于listen状态;
(b)syn_recv:服务器接收到数据包之后进入syn_recv状态;
(c)established:在接收完数据后进入established状态。
以上3个状态存在tcp控制块中。
应用层调用listen(fd, backlog),参数backlog有两种理解,在linux系统中指的是半连接队列的长度,在unix系统中指半连接队列和全连接队列大小之和。
如果第三次握手ack包丢失,那么第二次握手会不会重发ack包, 答案是不会重发,没有重发得意义,但是包的超时可以设置。这就引出了超时怎么计算,客户端发包到服务端,服务端发包到客户端,客户端发包开始记录一个时间,到客户端收到包时也记录一个时间,服务端也类似发包记录一个时间到收包也记录一个时间,这个往返的时间叫做RTT,当前RTT往返时间 = 上一次RTT*0.9 + 下一次RTT*0.1。
(2)数据传输
tcp传输并不是发一个包回一个ack再发下一个包,这样速度很慢,实际是多个包一起发,再等待ack确认。这样导致不能保证先发的数据就是先到,后发的数据后到,tcp为了保证顺序,引入了超时重传的机制。收到一个包,启动一个200ms定时器,等待接收到下一个包,如果在200ms内收到,就会重置定时器等待接收下一个包,如果200ms没收到就会超时,超时后,就会遍历那个包没有收到,并回一个ack确认消息告知发送端那没有收到,让发送端从该数据包开始,包括之后的数据包都要重新发。
慢启动,拥塞控制如下图所示。
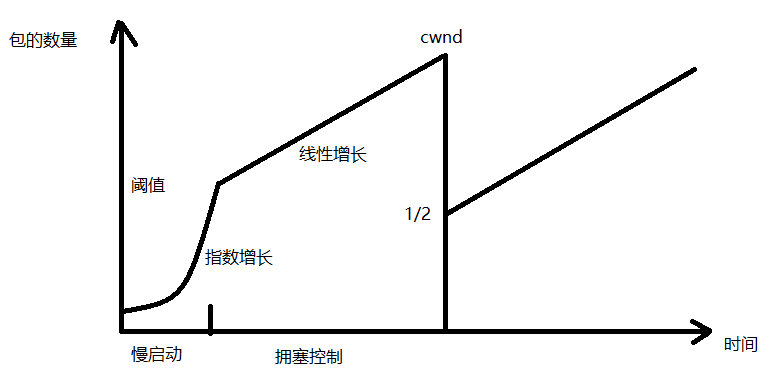
一开始数量是指数级增长(慢启动),到达初始化的阈值后线性增长,增长到对方接收数据时,回ack的包超过RTT时间,这时网络拥塞,数据包太多来不及处理,此时降一半。
tcp重要的定时器有:
(a)超时重传
(b)坚持定时器,当cwin=0时,接收端告诉发送端不能再发数据了,如果客户端想再发送数据,就会启动一个坚持定时器,发一个探测包给接收端,告诉对端你能不能接收数据,接收端 recv_buff不满时,就会回ack告知发送端可以发数据了。
(c)keepalive
(d)time_wait,4次挥手中避免最后一次ack丢失
(3)四次挥手
四次挥手的流程如下图所示。
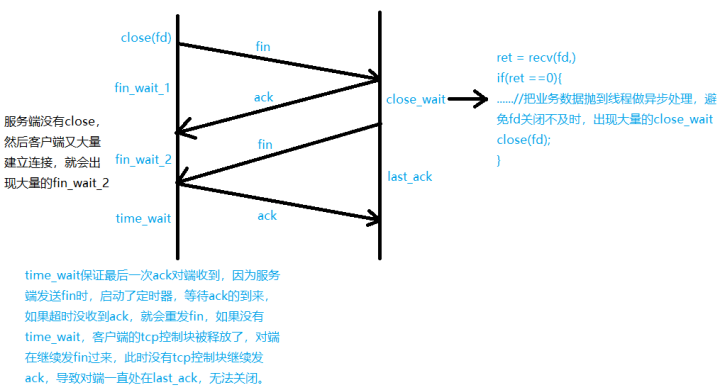
(a) 客户端调用close(fd)发送fin包,服务端收到fin包后,回ack包确认;
(b) 服务端在处理完缓冲区的数据后,调用close(fd)关闭对应的fd,发送fin包;
(c) 客户端收到fin包后,回ack包确认,等待2msl(2个数据包发送周期)后释放连接;
(d) 服务端收到ack包后,释放连接。
思考:
(1)服务端大量出现close_wait如何解?
原因:
服务端recv()返回0后,处理数据不及时,导致close调用不及时。
解决思路:
(a)检查代码有没有调用close;
(b)把处理数据做成异步处理,即抛到线程异步处理;
(2)客户端出现大量的fin_wait_2如何解?
原因:
服务端recv返回0后,不调用close,客户端就会出现fin_wait_2
解决思路:
(a)服务端处理;
(b)客户端 kill;
(c)重新建个连接。
(3)客户端出现大量的time_wait?
原因是客户端发送的最后一次ack包,服务端没有收到,超时后服务端重发fin包,导致客户端出现大量的time_wait。
(4)TCP既然有keepalive探活包,为什么应用层也需要做心跳检测?
因为探活包在传输层,无法判断进程阻塞或者死锁的情况。
原文:用户态协议栈分析 - MrJuJu - 博客园
最后
以上就是瘦瘦外套最近收集整理的关于深入浅出用户态协议栈的全部内容,更多相关深入浅出用户态协议栈内容请搜索靠谱客的其他文章。








发表评论 取消回复