在机器学习中,我们经常会遇到分类特征,例如:人的性别有男女,这些特征是离散、无序的。我们需要对其进行特征数字化。
什么是特征数字化?例子如下:
- 性别特征:[“男”,“女”]
- 国籍特征:[“中国”,“美国”,“法国”]
- 运动特征:[“足球”,“篮球”,“羽毛球”,“乒乓球”]
假如某个样本,他的特征是这样的[“男”,“中国”,“乒乓球”],我们可以用[0,0,4]来表示,但是这样的特征处理并不能直接放入机器学习算法中。因为类别之间是无序的。
什么是独热编码(One-Hot)?
One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
One-Hot 编码是分类变量作为二进制向量的表示。首先先要求将分类值映射到整个数值。然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。
One-Hot实际案例
假设我们有四个样本(行),每个样本有三个特征(列),如图:
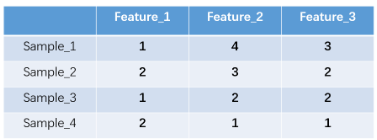
上图中我们已经对每个特征进行了普通的数字编码:我们的feature_1有两种可能的取值,比如男/女,这里男用1表示,女用2表示。那么拿feature_2来说one-hot编码怎样处理
这里feature_2有4种取值(状态),我们就用4个状态位来表示这个特征,one-hot编码就是保证每个样本中的单个特征只有1位处于状态1,其它都是0。

对于2、3甚至更多种状态都是这样表示,所以我们可以得到这些样本特征的心表示:
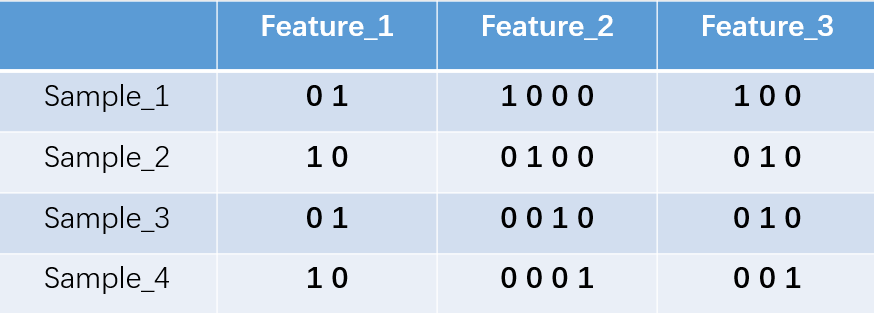
one-hot编码将每个状态都看成一个特征。对于前两个样本我们可以得到它的特征向量分别为

1.2 one-hot在提取文本特征上的应用
one-hot在特征提取上属于词袋模型(bag of words)。one-hot如何抽取文本特征向量呢?
假设我们的语料库有三段话:
我爱中国
爸爸妈妈爱我
爸爸妈妈爱中国
我们首先对语料库分离并获取其中所有的词,然后对每个词进行编号:
1 我 ; 2 爱; 3 爸爸; 4 妈妈; 5 中国
然后使用one-hot 对每段话提取特征向量:
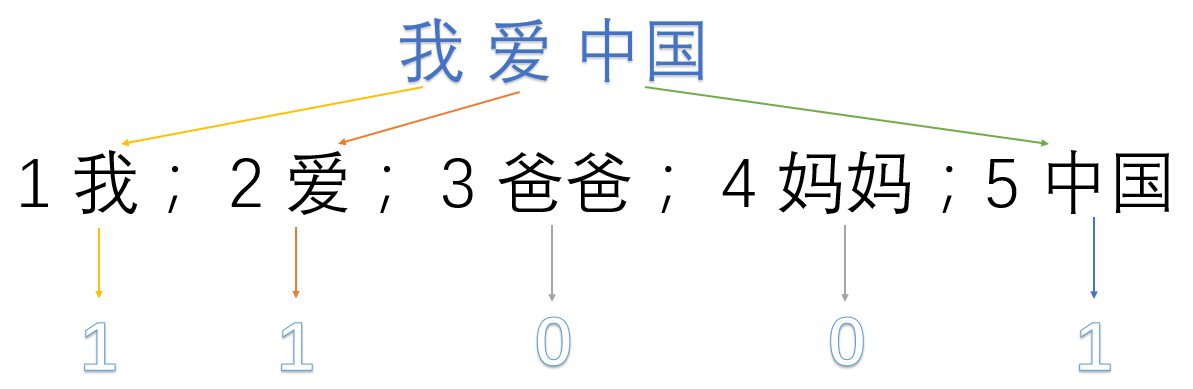
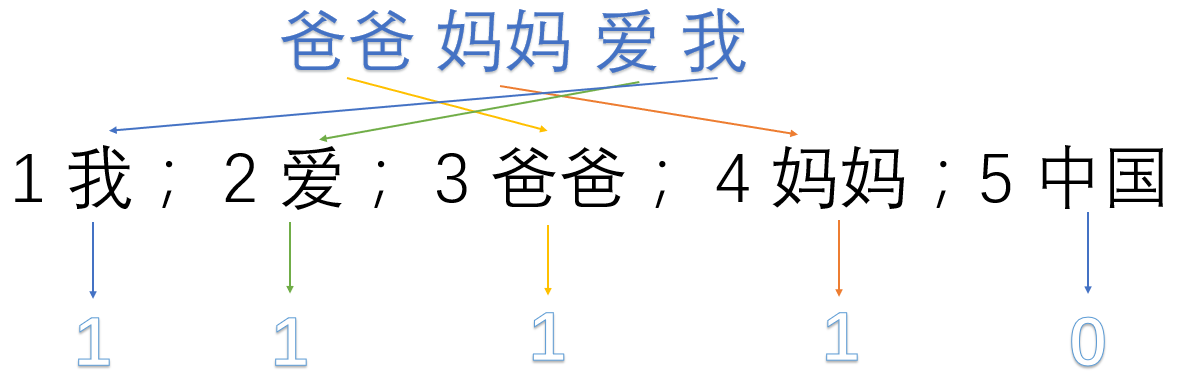

因此我们得到了最终的特征向量为
我爱中国——> 1,1,0,0,1
爸爸妈妈爱我——>1,1,1,1,0
爸爸妈妈爱中国——>0,1,1,1,1
one-shot encoding
one-hot的基本思想:将离散型特征的每一种取值都看成一种状态,若你的这一特征中有N个不相同的取值,那么我们就可以将该特征抽象成N种不同的状态,one-hot编码保证了每一个取值只会使得一种状态处于“激活态”,也就是说这N种状态中只有一个状态位值为1,其他状态位都是0。举个例子,假设我们以学历为例,我们想要研究的类别为小学、中学、大学、硕士、博士五种类别,我们使用one-hot对其编码就会得到:

dummy encoding
哑变量编码直观的解释就是任意的将一个状态位去除。还是拿上面的例子来说,我们用4个状态位就足够反应上述5个类别的信息,也就是我们仅仅使用前四个状态位 [0,0,0,0] 就可以表达博士了。只是因为对于一个我们研究的样本,他已不是小学生、也不是中学生、也不是大学生、又不是研究生,那么我们就可以默认他是博士,是不是。(额,当然他现实生活也可能上幼儿园,但是我们统计的样本中他并不是)。所以,我们用哑变量编码可以将上述5类表示成:

one-hot编码和dummy编码:区别与联系
假设我们现在获得了一个模型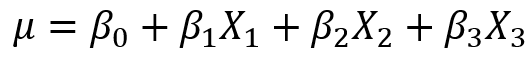
,这里变量满足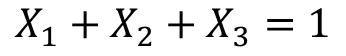
(因为特征是one-shot获得的,所以只有一个状态位1,其他都为0,所以它们相加和总是等于1),故我们可以用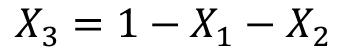 表示第三个特征,将其带入模型中,得到:
表示第三个特征,将其带入模型中,得到:
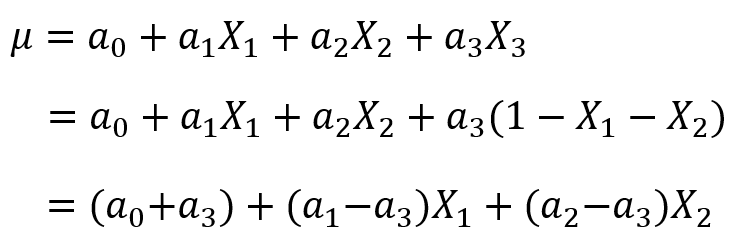
这时,我们发现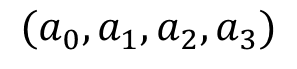
和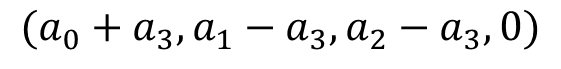
两个参数是等价的,那么我们模型的稳定性就成了一个待解决的问题。那么这个问题怎么解决呢?有如下三种方法:
1、使用L2正则化手段,将参数的选择加上一个限制,就是选择参数元素值小的那个作为最终参数,这样我们得到的参数就唯一了,模型也就稳定了。
2、把偏置项β0去掉,这时我们发现也可以解决同一个模型参数等价问题。
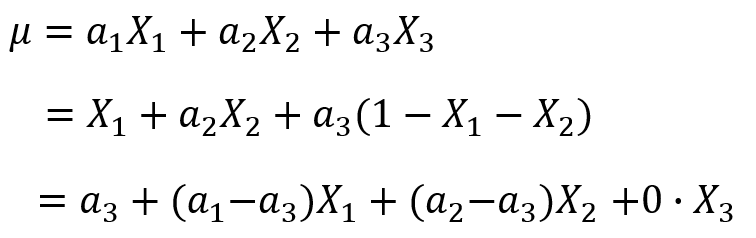
因为有了bias项,所以和我们去掉bias项的模型是完全不同的模型,不存在参数等价的问题。
3、再加上bias项的前提下,使用哑变量编码代替one-hot编码,这时去除了X3,也就不存在之前一种特征可以用其他特征表示的问题了。
总结:我们使用one-hot编码时,通常我们的模型不加bias项或者加上bias项然后使用L2正则化手段去约束参数;当我们使用哑变量编码时,通常我们的模型都会家bias项,因为不加bias项会导致固有属性丢失。
选择建议:正则化+one-hot编码;
连续值的离散化为什么会提升模型的非线性能力?
简单来说,使用连续变量的LR模型,模型表示我为公式(1),而使用one-hot或哑变量编码后的模型公式(2)
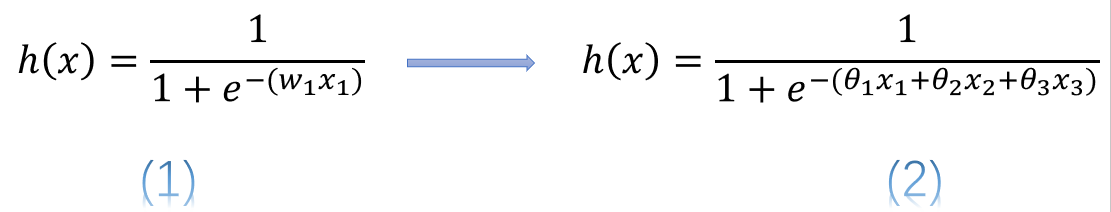
式中表示连续型特征,、、分别是离散化后在使用one-hot或哑变量编码后的若干个特征表示。这时我们发现使用连续值的LR模型用一个权值去管理该特征,而one-hot后有三个权值管理了这个特征,这样使得参数管理的更加精细,所以这样拓展了LR模型的非线性能力。
这样做除了增强了模型的非线性能力外,还有什么好处呢?这样做了我们至少不用再去对变量进行归一化,也可以加速参数的更新速度;再者使得一个很大权值管理一个特征,拆分成了许多小的权值管理这个特征多个表示,这样做降低了特征值扰动对模型为稳定性影响,也降低了异常数据对模型的影响,进而使得模型具有更好的鲁棒性。
原文链接https://www.cnblogs.com/lianyingteng/p/7755545.html
https://www.cnblogs.com/lianyingteng/p/7792693.html
最后
以上就是清秀云朵最近收集整理的关于one-hot编码的全部内容,更多相关one-hot编码内容请搜索靠谱客的其他文章。








发表评论 取消回复