朴素贝叶斯公式来历
NaïveBayes算法,又叫朴素贝叶斯算法。
朴素:特征条件独立;
贝叶斯:基于贝叶斯定理。属于监督学习的生成模型,实现简单,没有迭代,并有坚实的数学理论(即贝叶斯定理)作为支撑。在大量样本下会有较好的表现,不适用于输入向量的特征条件有关联的场景。
朴素贝叶斯(Naive Bayesian)是基于贝叶斯定理和特征条件独立假设的分类方法,它 通过特征计算分类的概率,选取概率大的情况,是基于概率论的一种机器学习分类(监督学习)方法,被广泛应用于情感分类领域的分类器。
朴素贝叶斯算法是应用最为广泛的分类算法之一,在垃圾邮件分类等场景展露出了非常优秀的性能。
在介绍朴素贝叶斯公式前,先介绍一下条件概率公式。条件概率表示在B已经发生的条件下,A发生概率。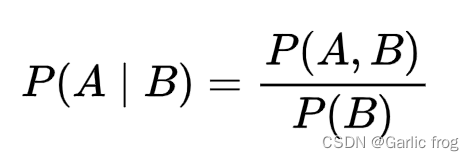
朴素贝叶斯公式就是条件概率的变形。
假设已有数据为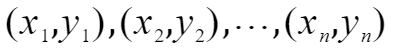
其中x为属性值,y为分类结果,共有n个已有数据。每个x有多种属性,以第一组数据为例,上标表示第几个属性值,x的具体表示如下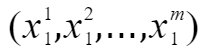
假设y的可取值为(c1,c2,…,ck)
则贝叶斯公式表示为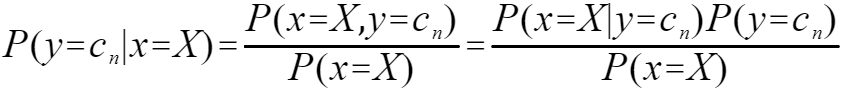
由公式可以看出,贝叶斯公式就是条件概率的公式。贝叶斯公式的解释很简单:在已有数据的基础上,出现了一个新数据,只有X=(a1,a2,…,am),来预测y的取值。贝叶斯公式就是求在目前X发生的情况下,y取不同值的概率大小进行排序,取最大概率的y值。
其中X有多个属性,朴素贝叶斯假设各个属性之间是独立的,因此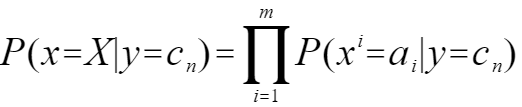
因此朴素贝叶斯公式可以写成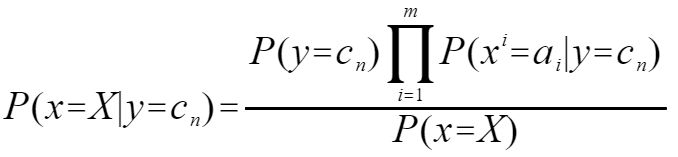
此公式的含义就是在目前已知历史数据数据的前提下,出现了一个新的X,求在X已经发生的条件下,y取不同值的概率,然后取使得条件概率最大的y作为预测结果。也就是说寻找y的取值Cn,使得上式最大。
举例:在夏季,某公园男性穿凉鞋的概率为 1/2 ,女性穿凉鞋的概率为 2/3 ,并且该公园中男女比例通常为 2:1 ,问题:若你在公园中随机遇到一个穿凉鞋的人,请问他的性别为男性或女性的概率分别为多少?
分析:
在例子中,根据男女比例2:1,可得 P(Y=ymen)=2/3,P(Y=ywomen)=1/3
在例子中:男性穿凉鞋的概率为 1/2,也就是说“是男性的前提下,穿凉鞋的概率是 1/2,此概率为条件概率,即 P(X=x1|Y=ymen)=1/2。同理“女性穿凉鞋的概率为 2/3” 为条件概率 P(X=x1|Y=ywomen)=2/3。
则P(X=x1)=(1/2*2+2/3*1)/3=5/9
则可得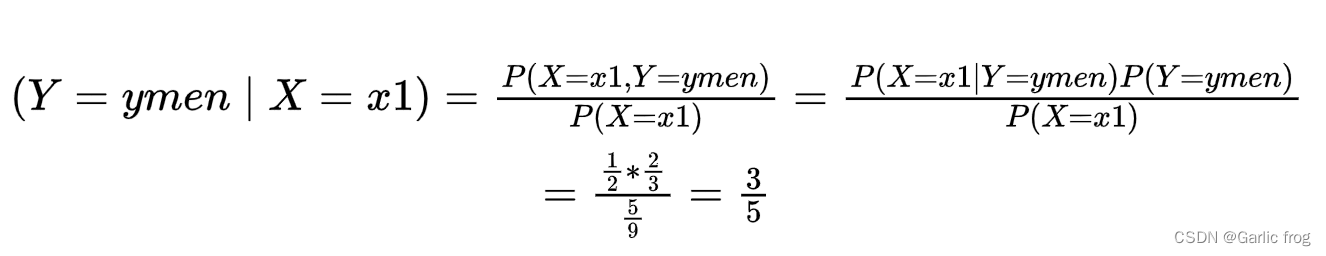
同理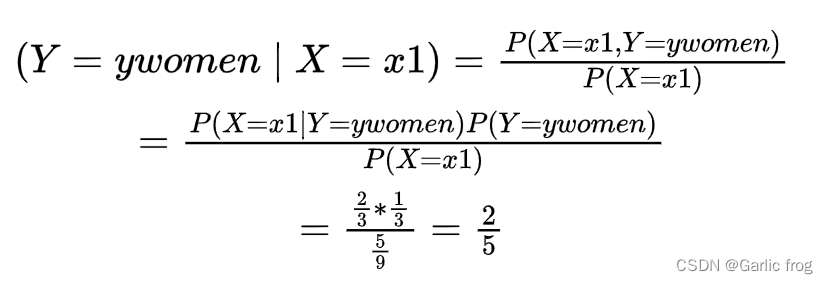
则为男性的概率为3/5 为女性的概率为2/5.
垃圾邮件分类实现
步骤:
收集数据:提供文本文件。
准备数据:将文本文件解析成词条向量。
分析数据:检查词条确保解析的正确性。
训练算法:计算不同的独立特征的条件概率。
测试算法:计算错误率。
使用算法:构建一个完整的程序对一组文档进行分类训练集的准备与处理
准备两个文件夹分别存入垃圾邮件及正常邮件两种邮件当作训练集。

准备数据:从文本中构建词向量
def loadDataSet():
postingList=[['my','dog','has','flea','problems','help','please'],
['maybe','not','take','him','to','dog','park','stupid'],
['my','dalmatian','is','so','cute','I','love','him'],
['stop','posting','stupid','worthless','garbage'],
['mr','licks','ate','my','steak','how','to','stop','him'],
['quit','buying','worthless','dog','food','stupid']]
classVec=[0,1,0,1,0,1] #1代表侮辱性文字,0代表正常言论(对应6个文档)
return postingList,classVec
def createVocabList(dataSet):
vocabSet=set()
for document in dataSet:
vocabSet=vocabSet|set(document) #两个集合的并集
return list(vocabSet)
def setOfWords2Vec(vocabList,inputSet):
returnVec=[0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)]=1
else:
print("the word:%s is not in my vocabulary!"%word)
return returnVec
训练算法:从词向量计算概率
import numpy as np
def trainNB0(trainMatrix,trainCategory):
numTrainDocs=len(trainMatrix)
numWords=len(trainMatrix[0])
pABusive=sum(trainCategory)/float(numTrainDocs)
# p0Num=np.zeros(numWords)
# p1Num=np.zeros(numWords)
# p0Denom=0.0
# p1Denom=0.0
p0Num=np.ones(numWords)
p1Num=np.ones(numWords)
p0Denom=2.0
p1Denom=2.0
for i in range(numTrainDocs):
if trainCategory[i]==1:
p1Num+=trainMatrix[i]
p1Denom+=sum(trainMatrix[i])
else:
p0Num+=trainMatrix[i]
p0Denom+=sum(trainMatrix[i])
# p1Vect=p1Num/p1Denom
# p0Vect=p0Num/p0Denom
p1Vect=np.log(p1Num/p1Denom)
p0Vect=np.log(p0Num/p0Denom)
return p0Vect,p1Vect,pABusive
贝叶斯分类函数
#贝叶斯分类函数
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
p1=sum(vec2Classify*p1Vec)+np.log(pClass1)
p0=sum(vec2Classify*p0Vec)+np.log(1-pClass1)
if p1>p0:
return 1
else:
return 0
def NBtesting():
listOPosts,listClasses=loadDataSet()
myVocabList=createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList,postinDoc))
p0V,p1V,pAb=trainNB0(np.array(trainMat),np.array(listClasses))
testEntry=['love','my','dalmation']
thidDoc=np.array(setOfWords2Vec(myVocabList,testEntry))
print(testEntry,'classified as:',classifyNB(thidDoc,p0V,p1V,pAb))
testEntry=['stupid','garbage']
thisDoc=np.array(setOfWords2Vec(myVocabList,testEntry))
print(testEntry,'classified as:',classifyNB(thisDoc,p0V,p1V,pAb))
文档词袋模型
#朴素贝叶斯词袋模型
def bagOfWords2Vec(vocabList,inputSet):
returnVec=[0*len(vocabList)]
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)]+=1
return returnVec
切分文本
mySent='This book is the best book on python or M.L. I have ever laid eyes upon.'
print(mySent.split())
import re
mySent='This book is the best book on python or M.L. I have ever laid eyes upon.'
regEX=re.compile('\W+')
listOfTokens=regEX.split(mySent)
print(listOfTokens)
import re
mySent='This book is the best book on python or M.L. I have ever laid eyes upon.'
regEX=re.compile('\W+')
listOfTokens=regEX.split(mySent)
print([tok for tok in listOfTokens if len(tok)>0])
print([tok.lower() for tok in listOfTokens if len(tok)>0])
使用朴素贝叶斯进行交叉验证
def textParse(bigString):
import re
listOfTokens = re.split(r'W*', bigString)
return [tok.lower() for tok in listOfTokens if len(tok) > 2]
import random
def spamTest():
docList = []
classList = []
fullText = []
for i in range(1, 26): # 遍历25个txt文件
wordList = textParse(open('C:/Users/Administrator/Desktop/email/spam/%d.txt' % i).read()) # 读取每个垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
fullText.append(wordList)
classList.append(1) # 标记垃圾邮件,1表示垃圾文件
wordList = textParse(open('C:/Users/Administrator/Desktop/email/ham/%d.txt' % i).read()) # 读取每个非垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
fullText.append(wordList)
classList.append(0) # 标记正常邮件,0表示正常文件
vocabList = createVocabList(docList) # 创建词汇表,不重复
trainingSet = list(range(50))
testSet = [] # 创建存储训练集的索引值的列表和测试集的索引值的列表
for i in range(10): # 从50个邮件中,随机挑选出40个作为训练集,10个做测试集
randIndex = int(random.uniform(0, len(trainingSet))) # 随机选取索索引值
testSet.append(trainingSet[randIndex]) # 添加测试集的索引值
del (trainingSet[randIndex]) # 在训练集列表中删除添加到测试集的索引值
trainMat = []
trainClasses = [] # 创建训练集矩阵和训练集类别标签系向量
for docIndex in trainingSet: # 遍历训练集
trainMat.append(setOfWords2Vec(vocabList, docList[docIndex])) # 将生成的词集模型添加到训练矩阵中
trainClasses.append(classList[docIndex]) # 将类别添加到训练集类别标签系向量中
p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses)) # 训练朴素贝叶斯模型
errorCount = 0 # 错误分类计数
for docIndex in testSet: # 遍历测试集
wordVector = setOfWords2Vec(vocabList, docList[docIndex]) # 测试集的词集模型
if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: # 如果分类错误
errorCount += 1 # 错误计数加1
# print("分类错误的测试集:",docList[docIndex])
print('错误率:%.2f%%' % (float(errorCount) / len(testSet) * 100))
spamTest()
测试结果: (随机获取10个训练集里的文本当做测试集)


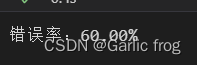
由结果可知错误率平均为0.6 我认为错误率这么大的原因是因为我的训练集样本不够丰富而且训练集样本中很多文档的内容相似,如果有够好的训练集的话训练结果应该会更好。
总结
朴素贝叶斯优缺点:
优点:在数据较少的情况下仍然有效,可以处理多类别问题
缺点:对于输入数据的准备方式较为敏感,由于朴素贝叶斯的“特征条件独立”特点,所以会带来一些准确率上的损失
代码参考机器学习实战课本
最后
以上就是沉默歌曲最近收集整理的关于朴素贝叶斯算法朴素贝叶斯公式来历垃圾邮件分类实现总结的全部内容,更多相关朴素贝叶斯算法朴素贝叶斯公式来历垃圾邮件分类实现总结内容请搜索靠谱客的其他文章。








发表评论 取消回复