一.基本原理
基于条件独立的假设,先计算输入和输出的联合概率密度,然后根据所输入的x计算y的概率,然后选择具有最大后验概率的类作为它的类别

二.优缺点
优点
- 小规模数据集表现好,适合多分类
- 对于在小数据集上有显著特征的相关对象,朴素贝叶斯可以对其进行快速分类
- 对大数据量训练和查询时具有较高的速度。即使使用超大规模的训练集,针对每个项目通常也只会有相对较少的特征数,并且对项目的训练和分类也仅仅是特征概率的数学运算而已
- 支持增量式运算,即可以实时的对新增的样本进行训练
- 对结果解释容易理解
- 对于噪声和无关属性比较健壮。噪声点和无关属性对算法影响较小,在很多邮件服务中仍然一直沿用这个方法进行垃圾邮件过滤
缺点
- 需要条件独立假设,会牺牲一定准确率,分类性能不一定高。因为在实际应用中,属性之间完全独立的情况是很少出现的,如果属性相关度较大,那么分类的效果就会变差。所以在具体应用的时候要好好考虑特征之间的相互独立性,再决定是否使用该算法,比如,维度太多的数据可能就不太适合,因为在维度很多的情况下,不同的维度之间越有可能存在联合的情况,而不是相互独立的,那么模型的效果就会变差
- 对于连续性特征变量要求其满足正态分布
三.适用场景
- 需要一个比较容易解释,而且不同维度之间相关性比较小的模型的时候
- 可以高效处理数据,虽然结果不尽人意
- 中文文本分类
- TF-IDF 文本词频统计转换
- 垃圾邮件的分类
- 信用评估
- 情感识别
- 多分类实时预测(因为速度快)
- 推荐系统(朴素贝叶斯 + 协同过滤)
- 欺诈检测
- 钓鱼网检测
四.推导

五.常见面试题
1.什么是贝叶斯决策理论?
贝叶斯的底层思想:如果能够掌握一个事物的全部信息,就一定可以计算出一个客观概率。但是我们遇到的绝大多数事物的信息都是不全的,贝叶斯决策就是在不完全信息下,对部分未知的状态用主观概率估计,然后用贝叶斯公式对发生概率进行修正,最后再利用期望值和修正概率做出最优决策(选择概率最大的类别),即:
- 已知类条件概率密度参数表达式和先验概率
- 利用贝叶斯公式转换成后验概率
- 根据后验概率大小进行决策分类
2.朴素贝叶斯算法的前提假设是什么?
- 特征之间相互独立
- 每个特征同等重要
3.朴素贝叶斯为什么朴素?
朴素的含义是“单纯天真”。因为它假定所有的特征在数据集中的作用是同样重要和独立的。这个假设现实中基本上不存在,因此说朴素贝叶斯真的很朴素。很多情况下,所有变量几乎不可能满足两两之间的条件。用贝叶斯公式表达如下:
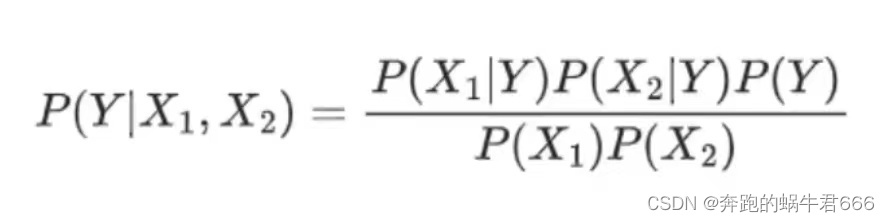 4.先验概率,后验概率,条件概率,联合概率,全概率公式和贝叶斯公式的理解
4.先验概率,后验概率,条件概率,联合概率,全概率公式和贝叶斯公式的理解
- 先验概率:表示事件发生前的预判概率。这个可以是基于历史数据统计,也可以由背景常识得出,也可以是主观观点得出。一般都是单独事件发生的概率,如P(A)
- 后验概率:基于先验概率求得的反向条件概率,形式上与条件概率相同,但是意义不同。后验概率是具体场景下条件概率的深入,具有一种建模意义,而条件概率只是一个数学名称
- 条件概率:P(A|B)表示B发生的条件下A发生的概率
- 联合概率:P(AB)表示事件A和事件B同时发生的概率
- 全概率公式:是对结果成立的所有可能情况的概率求和
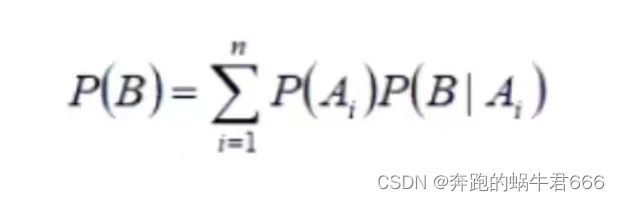
- 贝叶斯公式:当已知结果,问导致这个结果的第 i 个原因的可能性是多少?
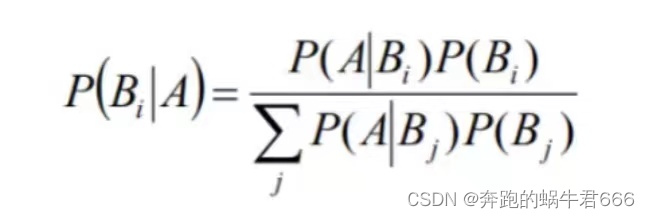
5.为什么属性独立性假设在实际情况中很难成立,但朴素贝叶斯仍能取得较好的效果?
首先独立性假设在实际中不存在,确实会导致朴素贝叶斯不如一些其他算法,但是就算法本身而言,朴素贝叶斯也会有不错的分类效果,原因是:
- 对于分类任务来说,只要各类别的条件概率排序正确,无需精准概率值即可正确分类
- 如果属性间依赖对所有类别影响相同,或依赖关系的影响能相互抵消,则属性条件独立性假设在降低计算开销的同时不会对性能产生负面影响
6.什么是朴素贝叶斯中的零概率问题?如何解决?
- 零概率现象:在进行分类的时候,可能会出现某个属性在训练集中没有与某个类同时出现过的情况,如果直接基于朴素贝叶斯分类器的表达式进行计算的话就会出现零概率现象
- 解决方法:为了避免其他属性所携带的信息被训练集中未出现过的属性值抹去,一般使用拉普拉斯估计器进行修正
- 具体方法:在分子上加1,对于先验概率,在分母上加上训练集中label的类别数;对于特征 i 在label下的条件概率,则在分母上加上第 i 个属性可能的取值数
7.朴素贝叶斯中概率计算的下溢问题如何解决?
- 下溢问题:在朴素贝叶斯的计算过程中,需要对特定分类中各个特征出现的概率进行连乘,小数相乘,越乘越小,这样就造成下溢出。在程序中,在相应小数位置进行四舍五入,计算结果可能就变成0了
- 解决方法:对乘积结果取自然对数。将小数的乘法操作转化为取对数后的加法操作,规避了变为0的风险的同时并不影响分类结果
8.朴素贝叶斯为什么适合增量计算?
因为朴素贝叶斯在训练过程中实际只需要计算出各个类别的概率和各个特征的类条件概率,这些概率值可以快速的根据增量数据进行更新,无需重新全量训练,所以其十分适合增量计算。该特性可以使用在超出内存的大量数据计算和按小时级等获取的数据计算中
9.朴素贝叶斯怎么处理连续变量?
当朴素贝叶斯算法数据的属性为连续型变量时,有两种方法可以计算属性的类条件概率
第一种方法:把一个连续的属性离散化,然后相应的离散区间替换连续属性值
- 但这种方法不好控制离散区间划分的粒度。如果粒度太细,就会因为每个区间内训练记录太少而不能对P(X|Y),做出可靠的估计
- 如果粒度太粗,那么有些区间就会有来自不同类的记录,因此失去了正确的决策边界
第二种方法:假设连续变量服从某种概率分布,然后使用训练数据估计分布的参数,例如可以使用高斯分布来表示连续属性的类条件概率分布

最后
以上就是眼睛大帅哥最近收集整理的关于机器学习 | 朴素贝叶斯一.基本原理二.优缺点三.适用场景四.推导五.常见面试题的全部内容,更多相关机器学习内容请搜索靠谱客的其他文章。








发表评论 取消回复