模型开发好后,能不能在真实生产环境中使用,是需要通过模型评审会议来决定的。
模型评审会议一般由业务方(策略方)和模型团队组织,通过模型评审文档内容的讲解,来确定后续的工作事项(调整/review/上线)。
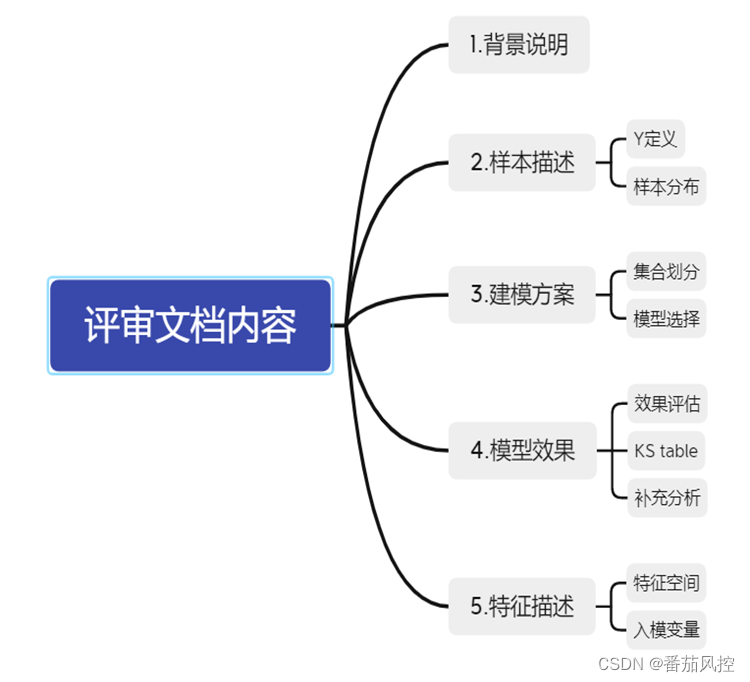
所以模型开发文档的整理显得尤为重要,它是对整个建模过程及结果的描述,主要包含:
①背景说明、
②样本描述、
③建模方案简介、
④模型效果分析、
⑤特征描述这5个部分内容。
在开发文档完成后,最重要的工作也有三步,分别是:
①模型部署
②模型验证
③模型监控指
一.模型部署
模型部署流程
模型同学的真实工作中绝非只是按流程开发一个模型而已,我们需要和上下游的同学沟通对接。首先需要明确各协同部门同学的职责,这里简单说明,各个公司具体情况不一样,但大多大同小异。
????模型同学:根据业务需求,基于离线数据构建风控模型,并负责模型部署、监控等。
????策略同学:根据离线预测的模型分数,制订相应的风控策略方案,配置策略包等。
????开发同学:支持底层数据源接入、问题排查、上线部署、平台搭建等工作。
通常情况下,风控模型一旦正式上线运行后,将会保持运行至少半年以上。这就要求我们把模型的稳定性、可控性放在第一位。
模型在通过模型评审和策略评估后,模型人员一般需要联合开发同学牵头进行模型的部署。
其主要流程包括:配置模型文件、确定离线任务还是实时任务、部署验证(包括历史分区的回刷和每日的例行生产验证)、最后由策略同学根据策略正式调用。
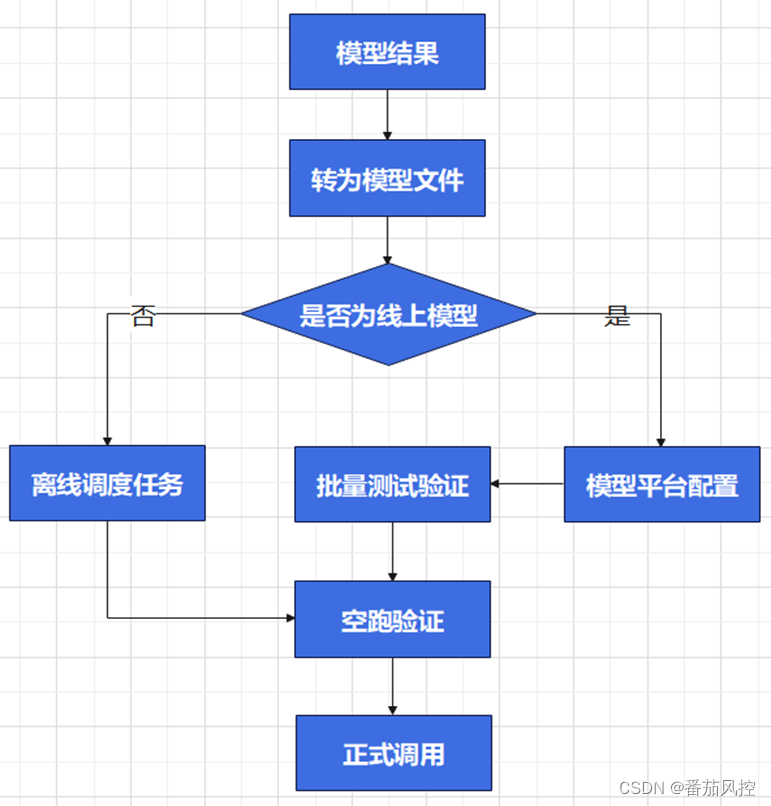
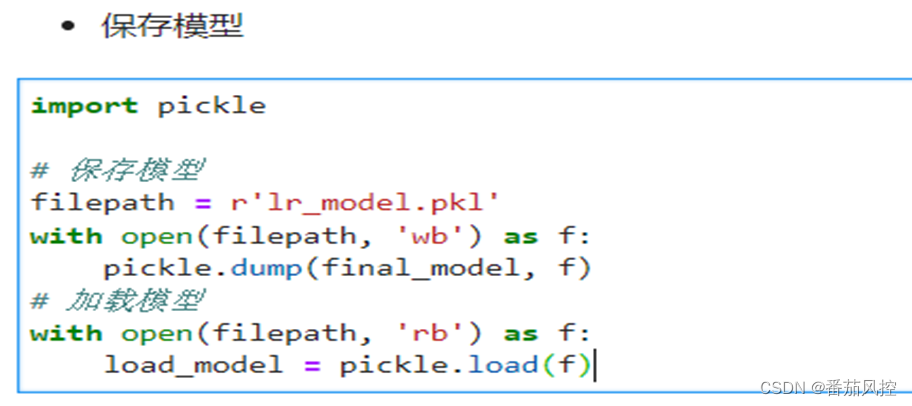
一般python开发的模型,会转成PKL文件或PMML文件供下游使用。
需要以下几点:
①原始特征在入模前的数据预处理(如缺失值填充)
②入模变量的顺序需要固定(入模顺序不一致,可能会造成预测结果误差)
③本地自行加载模型文件打分验证
二. 模型验证
在模型正式调用阶段,需要经过两个层面的验证。
(1)回溯打分验证:是指模型文件部署好后,回溯历史样本进行本地和服务器模型打分对比。
因为模型文件在本地跑,还是给开发同学在服务器上跑,其变量调用以及模型运行 环境都不一样,所以这一步回溯验证是为了部署的模型是否与本地模型打分逻辑一致。
(2)线上线下打分验证:是指部署好的模型在线空跑一批后,对应的样本在本地进行打分,与线上的样本进行一致性验证;并且这部分样本与前期线下的样本进行变量分布的稳定性检验。
因为线上跑分其数据并不是回溯而来,而是通过各种接口进行调用,由于数据的传输性能等等,排除可能对模型打分造成的误差,并且同时可以监测新样本与建模样本的分布差异。
三. 模型监控
风控模型上线部署后,将运行较长一段时间才会更新换代。此时监控就是非常需要完成的工作。
3.1.稳定性是模型需要考虑的重要因素。
模型之所以出现不稳定,主要因为以下两个方面造成的:
①样本(客群)的变化:而导致客群发生变化的原有主要有:政策市场变化、经济环境变化等各种内外部因素。一旦客群发生明显变化,那么原理的分数或者根据分数而指定的策略,将不再有效。(比如根据评分制定的拦截分数线,客群下沉后,通过率将大幅降低)
②评分系统出问题:数据源获取、系统bug等均会造成模型打分出现误差。(某个数据源出现误差,或者停止更新,会造成入模的某个变量出现问题从而造成打分失效)
为了能在第一时间发现上述问题,我们需要对模型进行动态监控。监控是构成闭环控制非常重要的一环,相当于控制系统的眼睛。
3.2.模型监控的指标
模型监控的内容主要包含稳定性监控和效果监控两个方面
①稳定性监控:
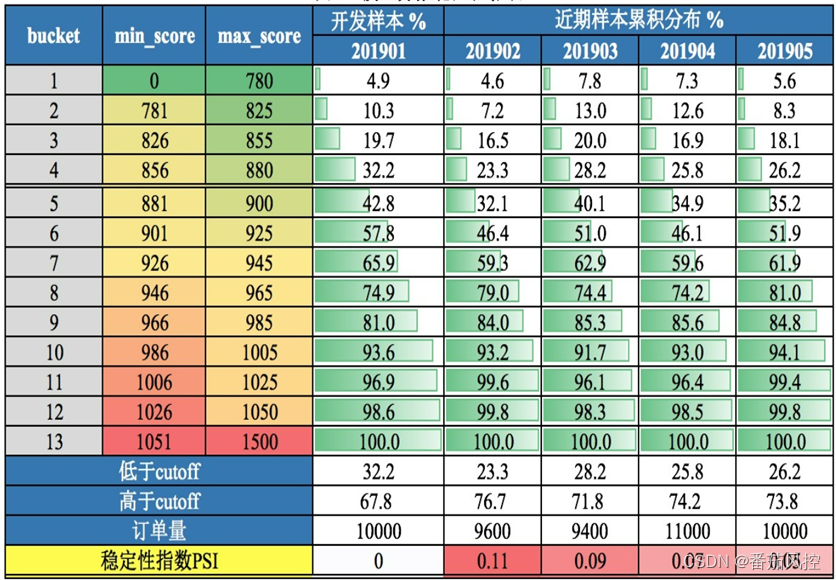
- 评分分布:模型分数在各分段的分布(PSI+明细)
- 特征分布:入模特征在各分段的分布(PSI+明细)
②模型效果监控:
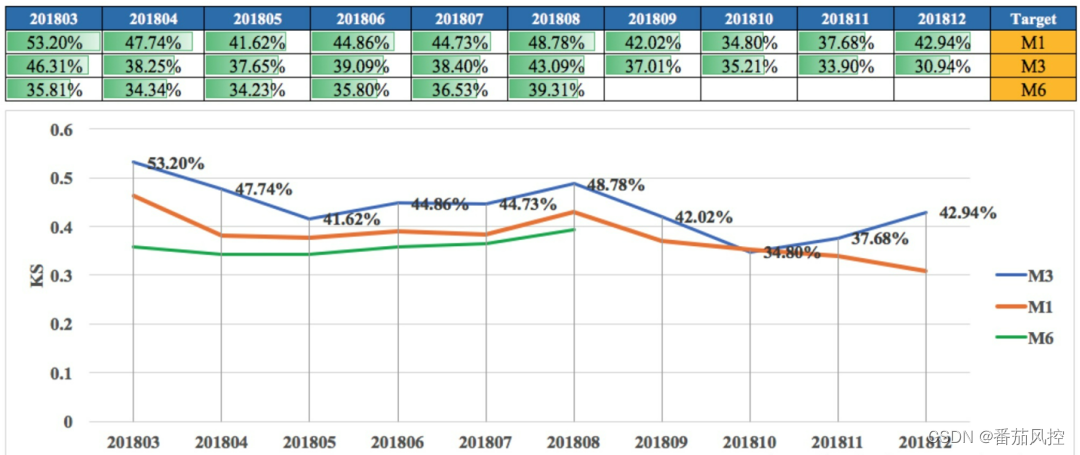
1.模型排序性评估:PR-表格。
2.模型区分度评估:包括KS、AUC、Gini等指标。
3. 模型监控
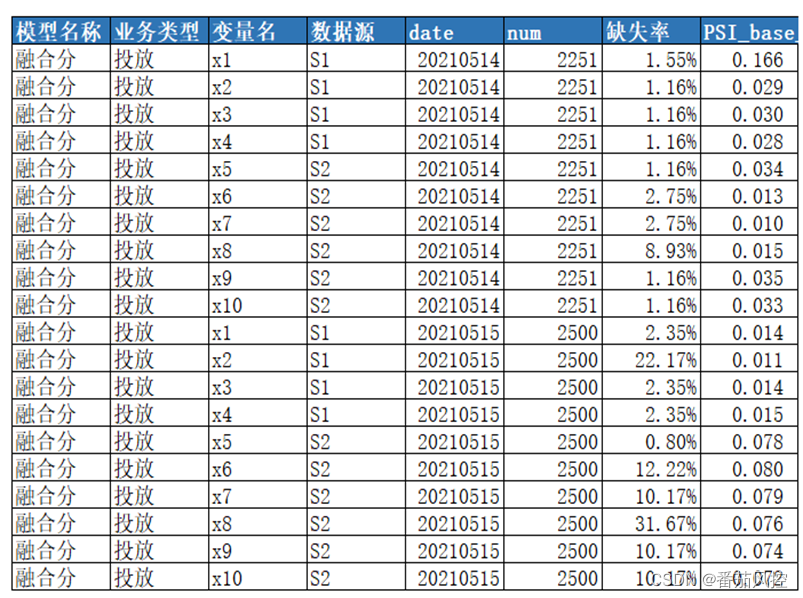
【模型评分分布】统计周期可以按日/周/月 拆分成在各个周期内要统计的内容,以报表的形式
【模型效果】统计周期可以按周/月 一般统计ks和auc,逐周或者逐月以报表的形式展示
以上关于风控模型相关的内容,可关注:

…
~原创文章
最后
以上就是魁梧翅膀最近收集整理的关于缀写风控模型评审文档与部署监控文档的要点的全部内容,更多相关缀写风控模型评审文档与部署监控文档内容请搜索靠谱客的其他文章。








发表评论 取消回复