前言:
本次讲解参考的仍是周志华的《机器学习》,采用的是书中的样例,按照我个人的理解对其进行了详细解释,希望大家能看得懂。
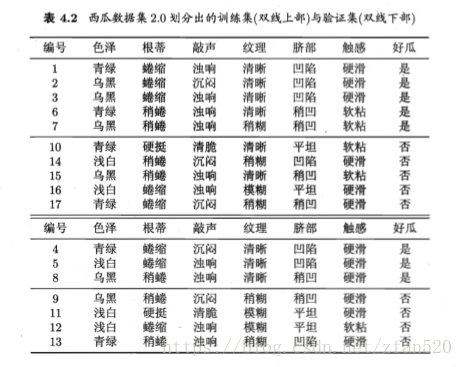
1、数据集
其中{1,2,3,6,7,10,14,15,16,17}为测试集,{4,5,8,9,11,12,13}为训练集。
2、预剪枝
预剪枝是要对划分前后泛化性能进行评估。对比决策树某节点生成前与生成后的泛化性能。
(1)在未划分前,根据训练集,类别标记为训练样例数最多的类别,由于训练集中的好瓜与坏瓜是相同多的类别,均为5,因此任选其中一类,书中选择了好瓜作为标记类别。
当所有节点集中在根节点,所有训练集属于标记类别的仅有{4,5,8},因此分类正确的是3/7*100%=42.9%
| 编号 | 好瓜(正确结果) |
| 4 | 是 |
| 5 | 是 |
| 8 | 是 |
| 9 | 否 |
| 11 | 否 |
| 12 | 否 |
| 13 | 否 |
| 3/7 |
(2)计算训练集的信息增益,得知脐部的信息增益最大,因此按照脐部进行划分。又因为在训练集中,凹陷特征好瓜的占比多,因此凹陷划分为好瓜,稍凹特征好过占比多,因此将其标记为好瓜,因此按照脐部划分的子树结果如下:
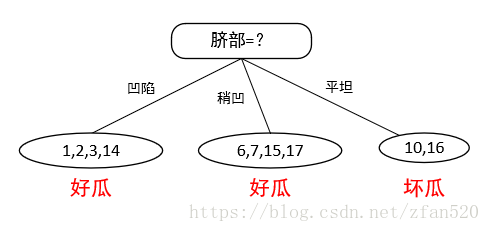
划分后,对比结果如下:
| 编号 | 好瓜(正确结果) | 按照脐部划分 |
| 4(凹陷) | 是 | 是 |
| 5(凹陷) | 是 | 是 |
| 8(稍凹) | 是 | 是 |
| 9(稍凹) | 否 | 是(划分错误) |
| 11(平坦) | 否 | 否 |
| 12(平坦) | 否 | 否 |
| 13(凹陷) | 否 | 是(划分错误) |
| 正确率 | 3/7 | 5/7(精度提高,划分) |
(3)在脐部划分的基础上,进一步计算凹陷、根蒂特征下,其他属性的信息增益,根据计算结果可知,在凹陷的情况下,色泽的信息增益最大,因此对于凹陷的西瓜,进一步确定按照色泽进行划分,划分结果如下:
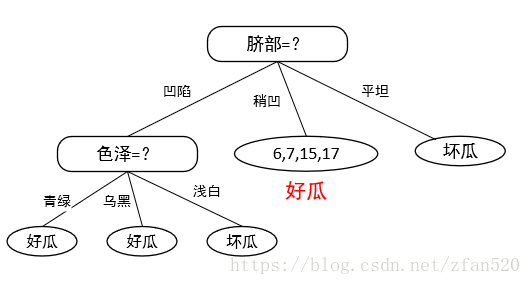
对于凹陷数据,进一步按照色泽进行划分后,对比划分前后的准确性:
| 编号 | 好瓜(正确结果) | 按照脐部划分 | 对凹陷,按照色泽划分 |
| 4(凹陷、青绿) | 是 | 是 | 是 |
| 5(凹陷、浅白) | 是 | 是 | 否 |
| 8(稍凹) | 是 | 是 | 是(不满足条件的,按照上一次划分结果照写) |
| 9(稍凹) | 否 | 是(划分错误) | 是 |
| 11(平坦) | 否 | 否 | 否 |
| 12(平坦) | 否 | 否 | 否 |
| 13(凹陷、青绿) | 否 | 是(划分错误) | 是 |
| 正确率 | 3/7 | 5/7(精度提高,划分) | 4/7(精度降低,不划分) |
对稍凹数据集,进一步计算其他属性的信息增益,确定根蒂的信息增益最大,因此对稍凹,进一步按照根蒂进行划分:
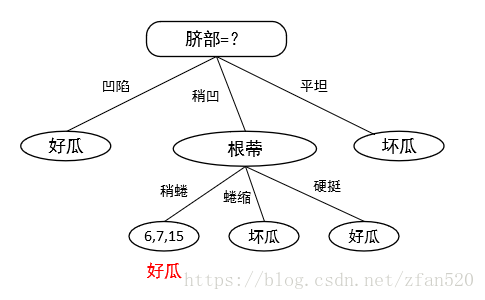
对于稍凹数据,进一步按照根蒂进行划分后,对比划分前后的准确性:
| 编号 | 好瓜(正确结果) | 按照脐部划分 | 对稍凹,按照根蒂划分 |
| 4(凹陷) | 是 | 是 | 是(不满足条件的,按照上次换发你结果照写) |
| 5(凹陷) | 是 | 是 | 是 |
| 8(稍凹、蜷缩) | 是 | 是 | 否 |
| 9(稍凹、蜷缩) | 否 | 是(划分错误) | 否 |
| 11(平坦) | 否 | 否 | 否 |
| 12(平坦) | 否 | 否 | 否 |
| 13(凹陷) | 否 | 是(划分错误) | 是 |
| 正确率 | 3/7 | 5/7(精度提高,划分) | 5/7(精度不变,不划分) |
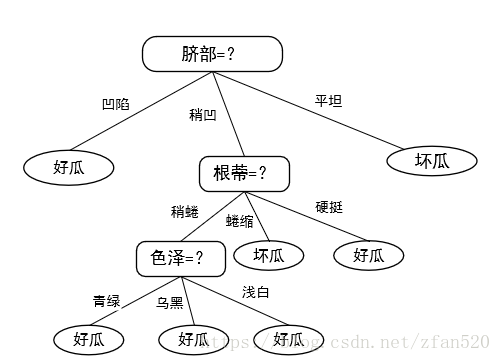
(4)因此按照预剪枝,最终形成的决策树如下图,其泛化性为71.4%。
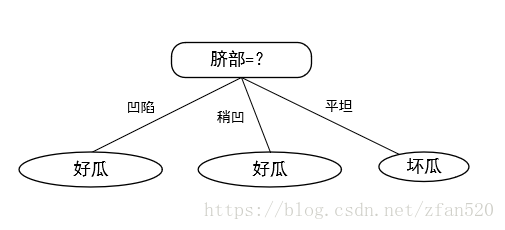
由图可知,预剪枝使得很多分支没有展开,这不仅降低了过拟合的风险,还显著减少了决策树的训练时间开销和测试时间。但是,有些分支虽当前不能提升泛化性。甚至可能导致泛化性暂时降低,但在其基础上进行后续划分却有可能导致显著提高,因此预剪枝的这种贪心本质,给决策树带来了欠拟合的风险。
3、后剪枝
后剪枝表示先从训练集中生成一颗完整决策树。
(1)我在此生成的决策树上将测试集的数据在此树上进行了标记,如下图所示:
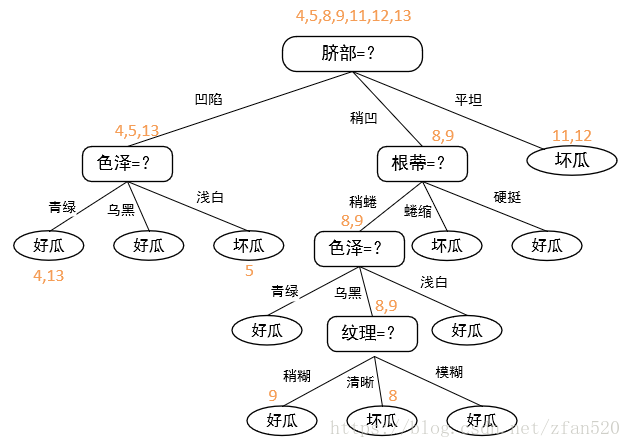
对比标记节点的划分类与各数据的真实分类,计算准确率,如下表所示:
| 编号 | 好瓜(正确结果) | 按照整棵树进行划分 |
| 4 | 是 | 是 |
| 5 | 是 | 否 |
| 8 | 是 | 否 |
| 9 | 否 | 是 |
| 11 | 否 | 否 |
| 12 | 否 | 否 |
| 13 | 否 | 是 |
| 正确率 | 3/7 |
生成的决策树,在验证集上的准确度为3/7*100%=42.9%
(2)后剪枝将从决策树的底部往上进行剪枝,先看最底部的纹理,将其领衔的分支减掉,即将其换成叶子节点。由于在训练集上,替换后,包含的样本号为{7,15},好瓜坏瓜比例相等,因此选择好瓜进行标记,剪枝后的决策树为:
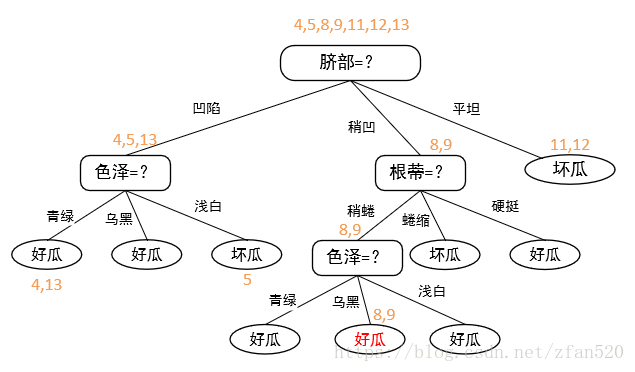
| 编号 | 好瓜(正确结果) | 按照整棵树进行划分 | 减掉底部纹理划分 |
| 4 | 是 | 是 | 是(其他不变,照写) |
| 5 | 是 | 否 | 否 |
| 8 | 是 | 否 | 是(改变) |
| 9 | 否 | 是 | 是 |
| 11 | 否 | 否 | 否 |
| 12 | 否 | 否 | 否 |
| 13 | 否 | 是 | 是 |
| 正确率 | 3/7 | 4/7(准确率提高) |
当减掉底部纹理划分后,准确率提高,因此按照纹理划分需裁剪掉。
(3)接着往上裁剪,此时应该是色泽部分,由于在训练集上,替换后,包含的样本号为{6,7,15},好瓜(2个)多于坏瓜(1个),因此选择好瓜进行标记,剪枝后的决策树为:
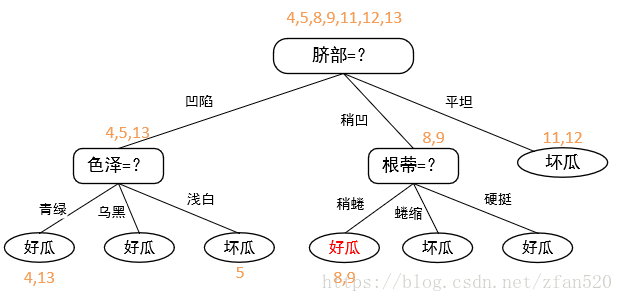
| 编号 | 好瓜(正确结果) | 按照整棵树进行划分 | 减掉底部纹理划分 | 减掉底部色泽划分 |
| 4 | 是 | 是 | 是(其他不变,照写) | 是(其他不变,照写) |
| 5 | 是 | 否 | 否 | 否 |
| 8 | 是 | 否 | 是(改变) | 是 |
| 9 | 否 | 是 | 是 | 是 |
| 11 | 否 | 否 | 否 | 否 |
| 12 | 否 | 否 | 否 | 否 |
| 13 | 否 | 是 | 是 | 是 |
| 正确率 | 3/7 | 4/7(准确率提高) | 4/7(准确率不变) |
此时决策树验证集精度仍为57.1%,因此可不进行剪枝,即对于脐部稍凹,根蒂稍蜷部分,可保留按照色泽进一步划分。
(4)接下来,我们看脐部凹陷分支。由于在训练集上,将色泽替换为叶节点后,包含的样本号为{1,2,3,14},好瓜(3个)多于坏瓜(1个),因此选择好瓜进行标记,剪枝后的决策树为:
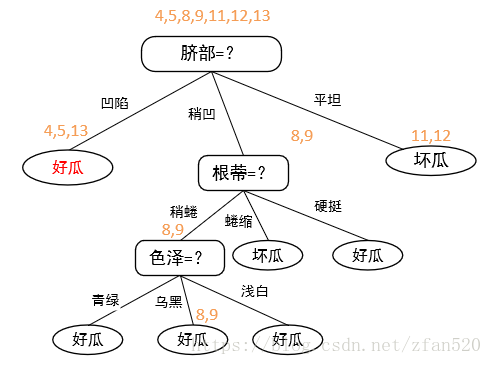
| 编号 | 好瓜(正确结果) | 按照整棵树进行划分 | 减掉底部纹理划分 | 减掉底部色泽划分 | 减调色泽划分(最左侧色泽) |
| 4 | 是 | 是 | 是(其他不变,照写) | 是(其他不变,照写) | 是 |
| 5 | 是 | 否 | 否 | 否 | 是(新划分,发生改变) |
| 8 | 是 | 否 | 是(改变) | 是 | 是(其他不变,照写) |
| 9 | 否 | 是 | 是 | 是 | 是 |
| 11 | 否 | 否 | 否 | 否 | 否 |
| 12 | 否 | 否 | 否 | 否 | 否 |
| 13 | 否 | 是 | 是 | 是 | 是 |
| 正确率 | 3/7 | 4/7(准确率提高) | 4/7(准确率不变) | 5/7(准确率提高) |
当减掉最左侧色泽划分后,准确率提高,因此按照色泽划分需裁剪掉。
(5)整棵树遍历基本完成,因此该决策树最终后剪枝的结果如下图所示,其验证精度为71.4%。
4、总结
对比预剪枝与后剪枝生成的决策树,可以看出,后剪枝通常比预剪枝保留更多的分支,其欠拟合风险很小,因此后剪枝的泛化性能往往由于预剪枝决策树。但后剪枝过程是从底往上裁剪,因此其训练时间开销比前剪枝要大。
最后
以上就是激动太阳最近收集整理的关于决策树的预剪枝与后剪枝的全部内容,更多相关决策树内容请搜索靠谱客的其他文章。








发表评论 取消回复