1. 剪枝(pruning)处理
首先,我们先说一下剪枝的目的——防止“过拟合”。
在决策树的学习过程中,为了保证正确性,会不断的进行划分,这样可能会导致对于训练样本能够达到一个很好的准确性,但是对于测试集可能就不是很好了,这样的模型不具备泛化性。
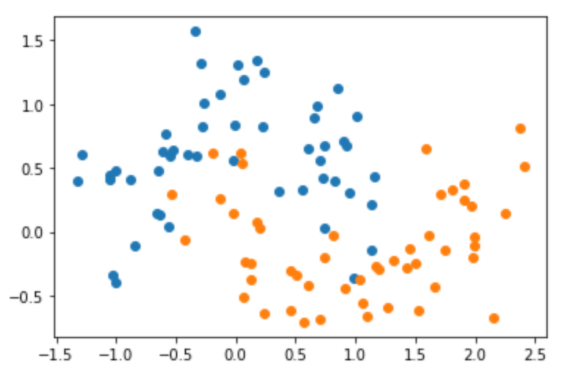
举一个例子,有如下的数据集:
坐标轴的上的每一个点代表一个样本,有x,y两种属性,其中,蓝色的点代表类0,橙色的点代表类1。
当我们使用决策树进行训练后,模型对于数据的识别区域如下,在粉红色区域,其认为里面的点为类0,蓝色的区域为类1:
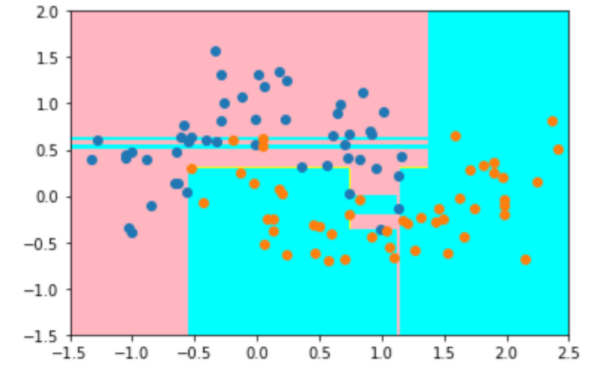
大家可能发现一个问题,那就是这个区域划分的太“细致”了。因为数据是有噪音(noise)的,这样划分明显是不合理的。
这里大家可以看一看决策树的图片:
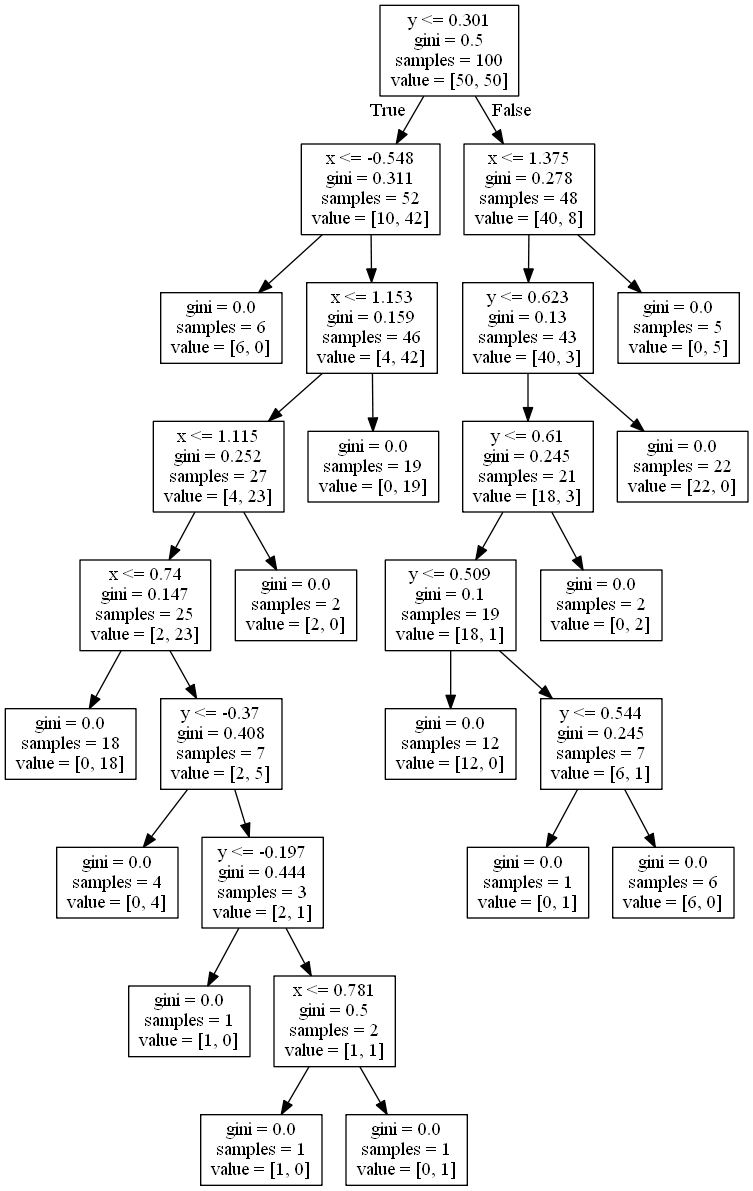
那么如何来缓解这种问题呢?其中有一种方法就是去掉一些分支(剪枝)来降低过拟合的风险。
关于剪枝处理请看这里【paper】。
剪枝有两种方案:
- 预剪枝(prepruning)
- 后剪枝(post-pruning)
1.1. 预剪枝(prepruning)
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。
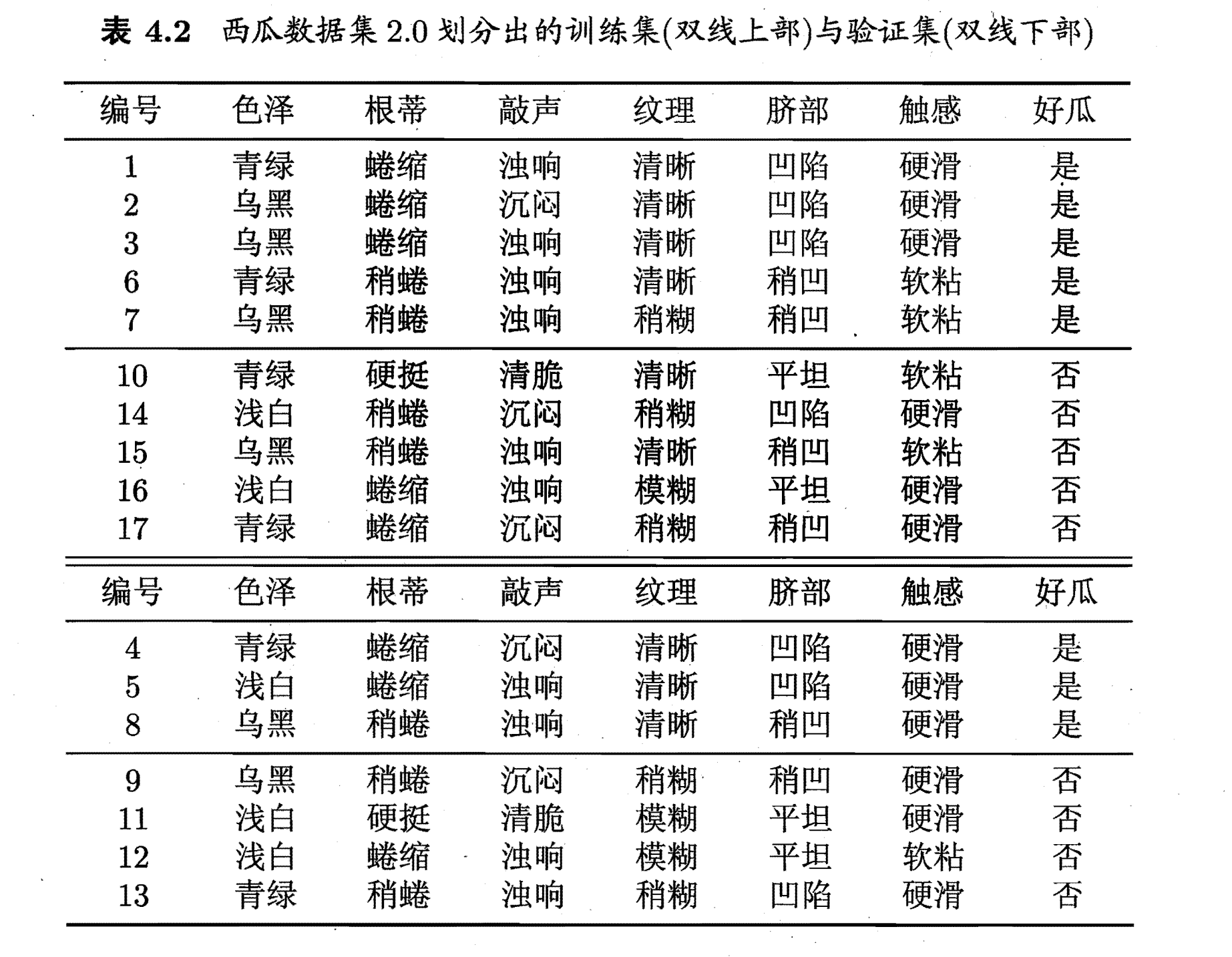
用通俗的话来说,就是如果进行划分能够带来更好的结果就进行划分,否则不进行划分。首先,我们定义一个训练集和一个验证集如下:(西瓜书中间的例子)
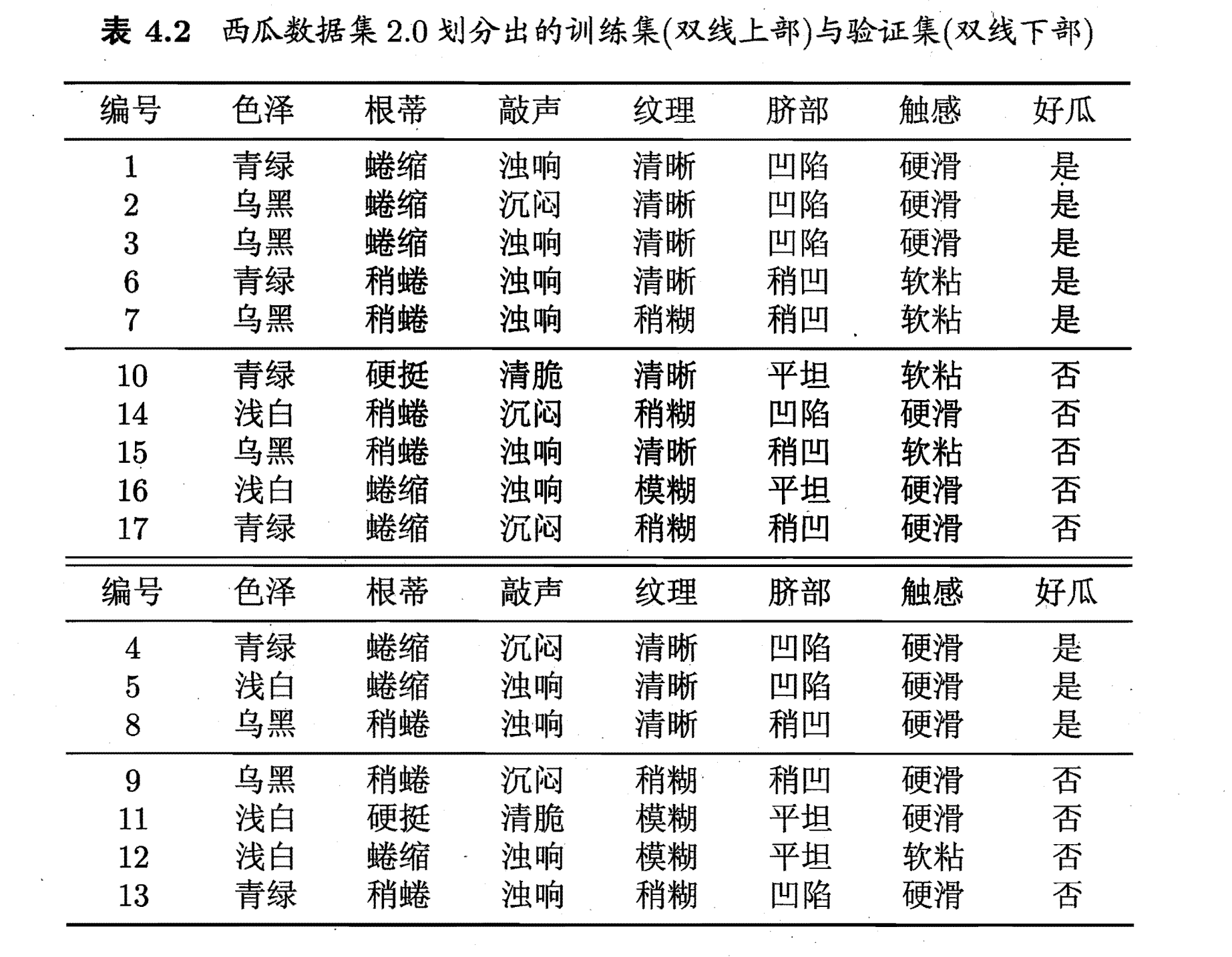
上面一部分是训练集,下面一部分是测试集。然后让我们来对训练集(记住是训练集)进行划分,划分的规则与上面的一样。
下面的这幅图是未剪枝的情况。
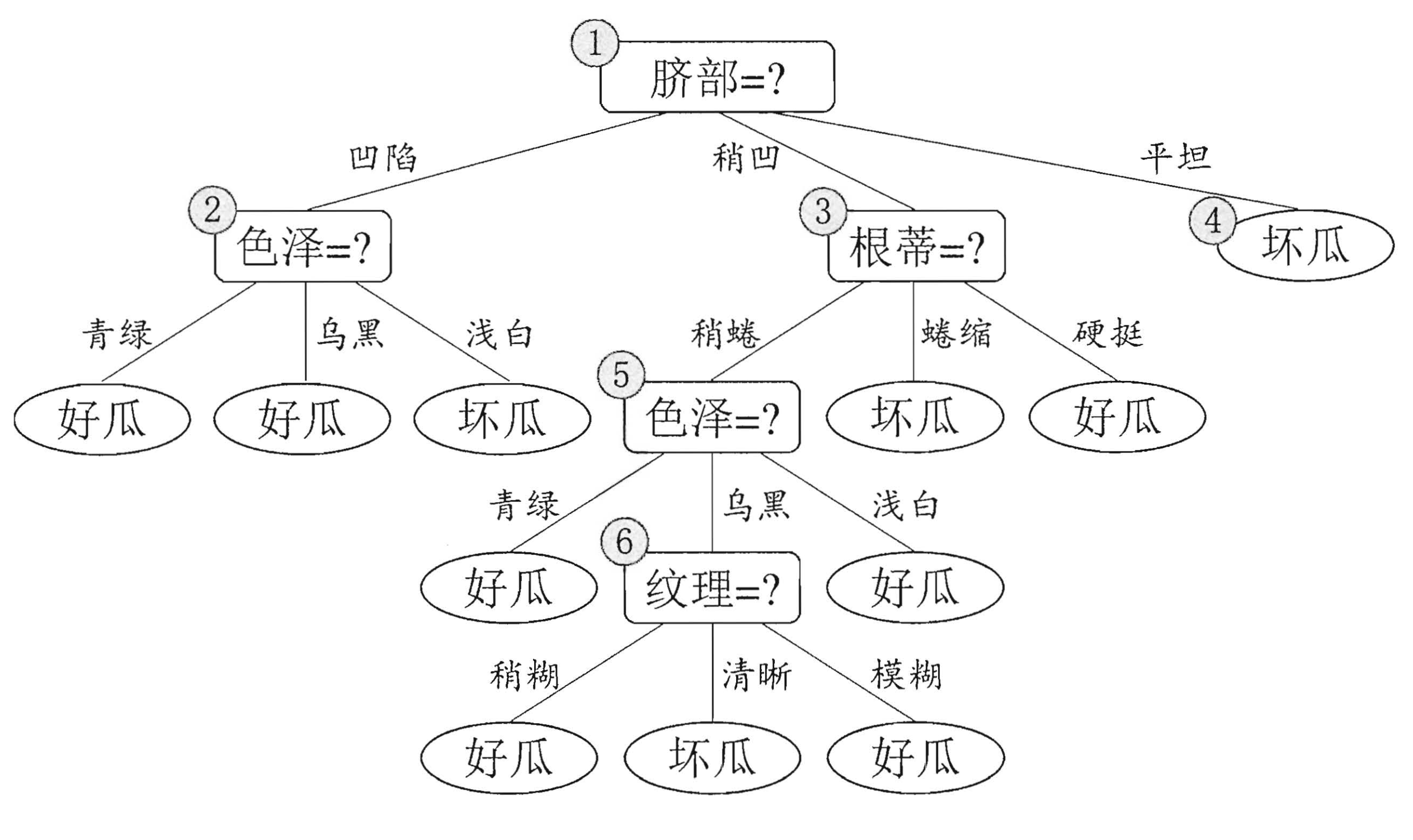
那么,剪枝是如何进行的呢?
首先,我们先判断“脐部”,如果我们不对“脐部”进行划分,也就是说这棵决策树是这样的:
只有一个好瓜的判断结果(根据上面的算法流程图,node节点直接就是叶子节点,其类别由样本中最多的决定【这里既可以是好瓜也可以是坏瓜,因为数量一样】)
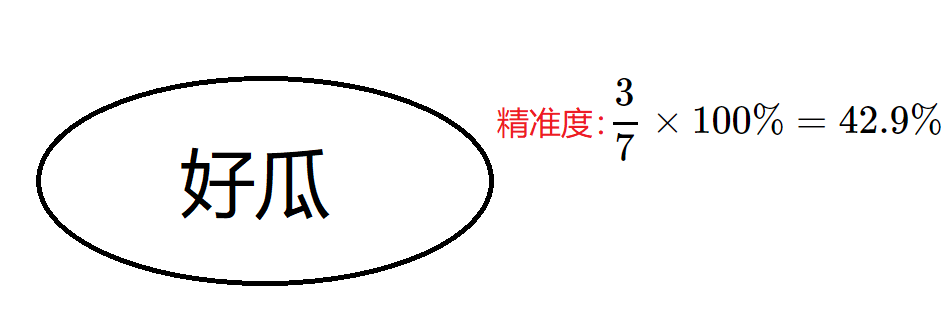
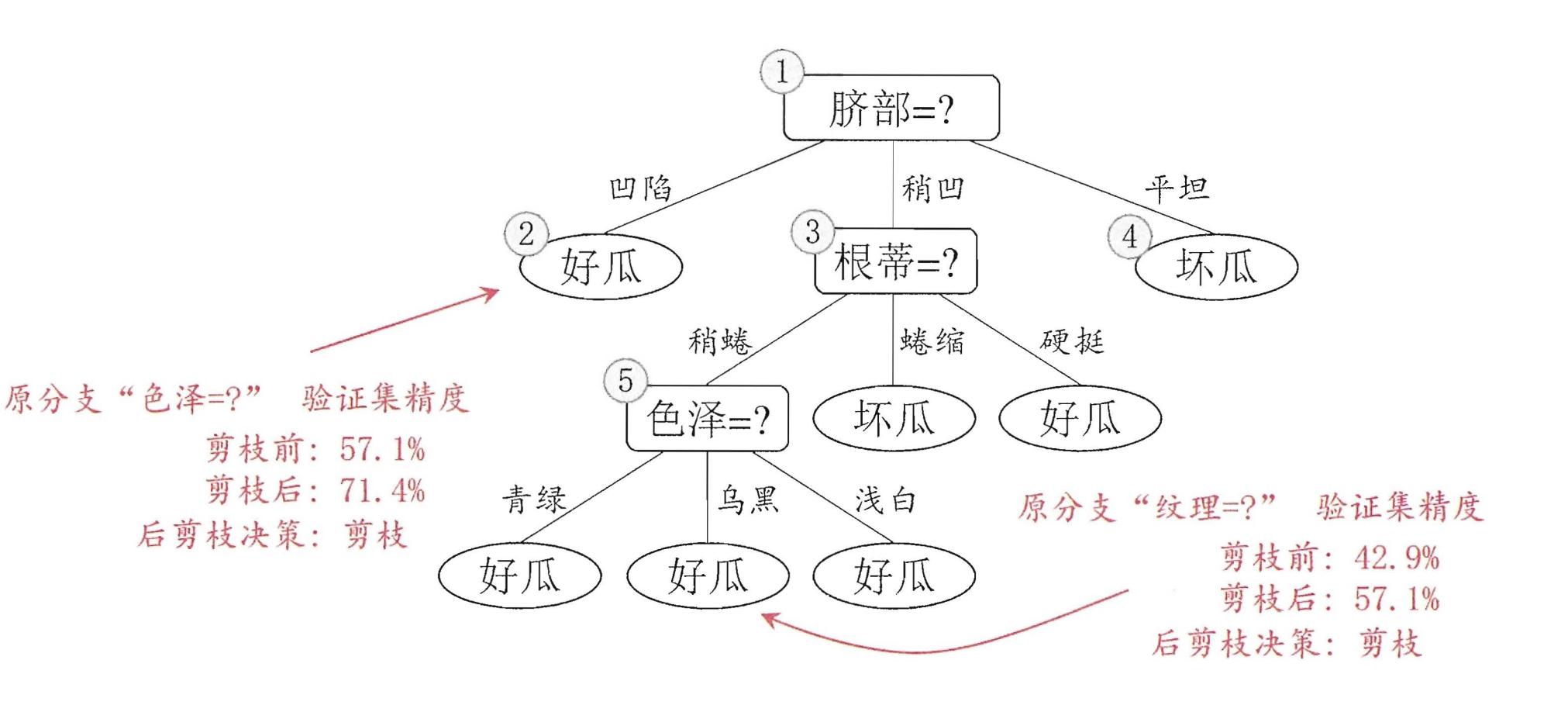
这样下来,也就是说无论你什么瓜过来我都判断它是好瓜。使用验证集进行验证,验证的精准度为:
3
7
frac{3}{7}
73×100%=42.9%。如果进行划分呢?
下图便是进行划分的情况,其中被红色圆圈框出来的部分表示验证正确。
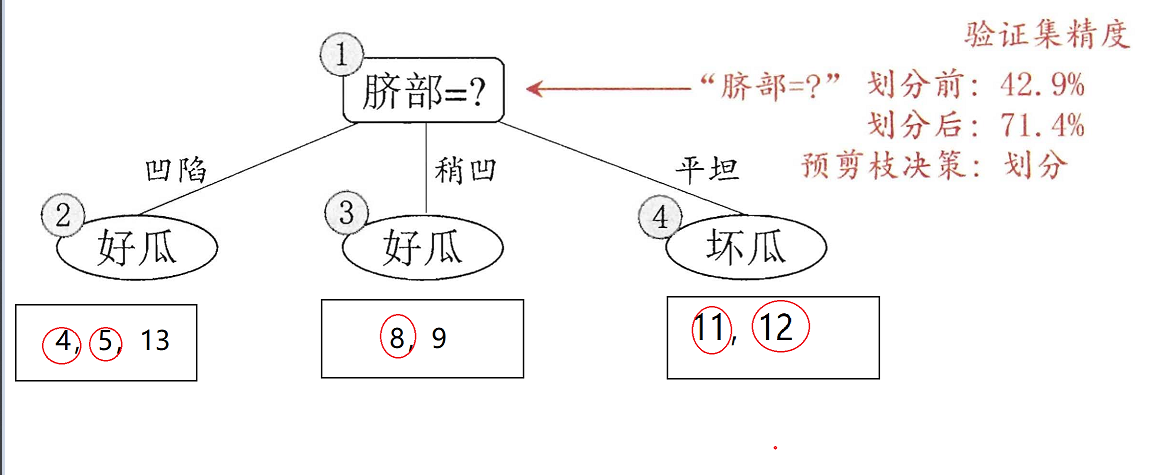
如果只划分“脐部”这个属性,我们可以通过其来划分好瓜和坏瓜,通过验证机去测试,我们可以得到划分后的准确性为:
5
7
frac{5}{7}
75×100%=71.4%>42.9%,所以选择划分。
下面便是进行前剪枝后的划分结果,使用验证集进行验证,精度为71.4%
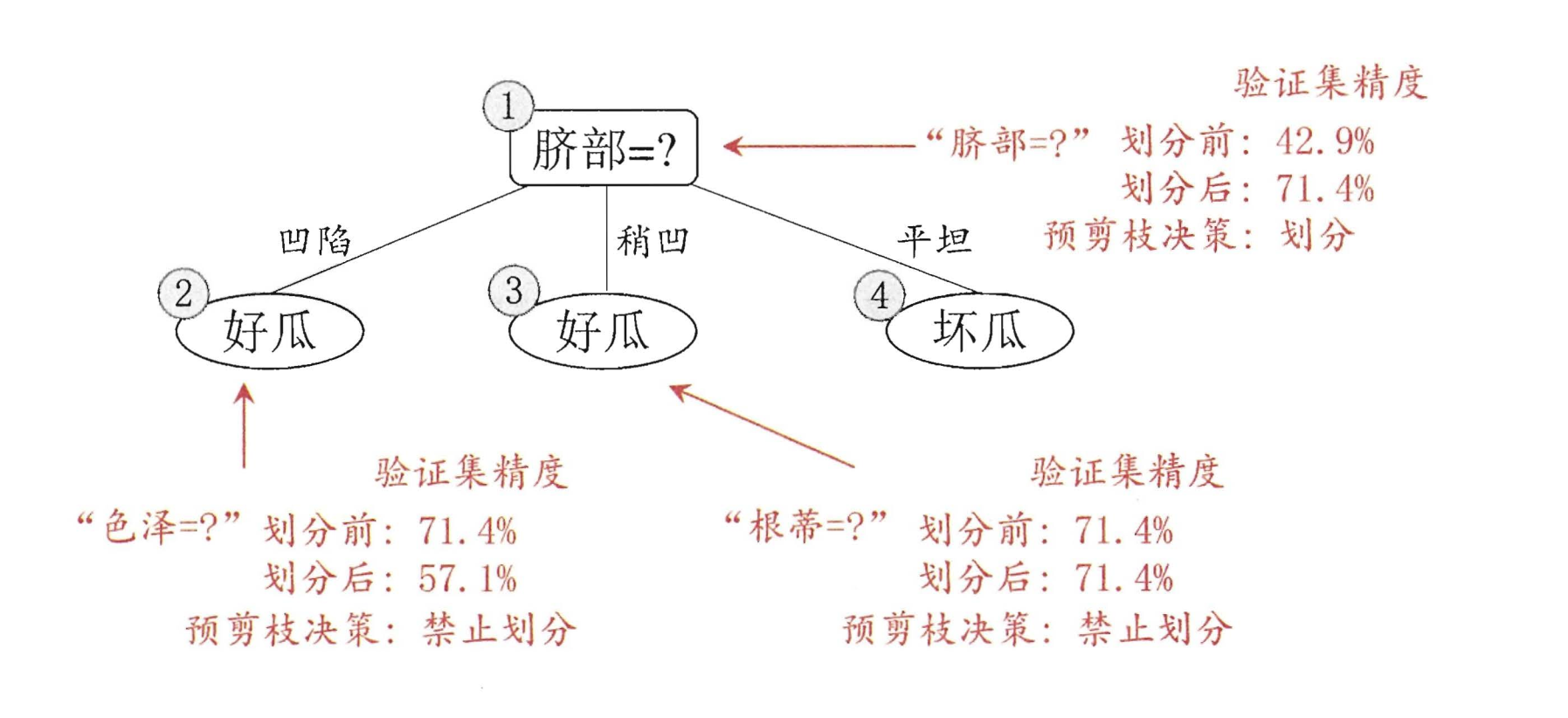
尽管该方案可以降低过拟合的风险,并在一定程度上能够降低算法的复杂度,但也会带来欠拟合的风险。因为会出现另外一种情况:有可能当前划分不能提升泛化能力,但是在此基础上的后续的划分也许可以导致性能显著提高。
1.2. 后剪枝(post-pruning)
后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
后剪枝和前剪枝的不同在于后剪枝是在生成决策树后再进行剪枝。顺序是由下到上。
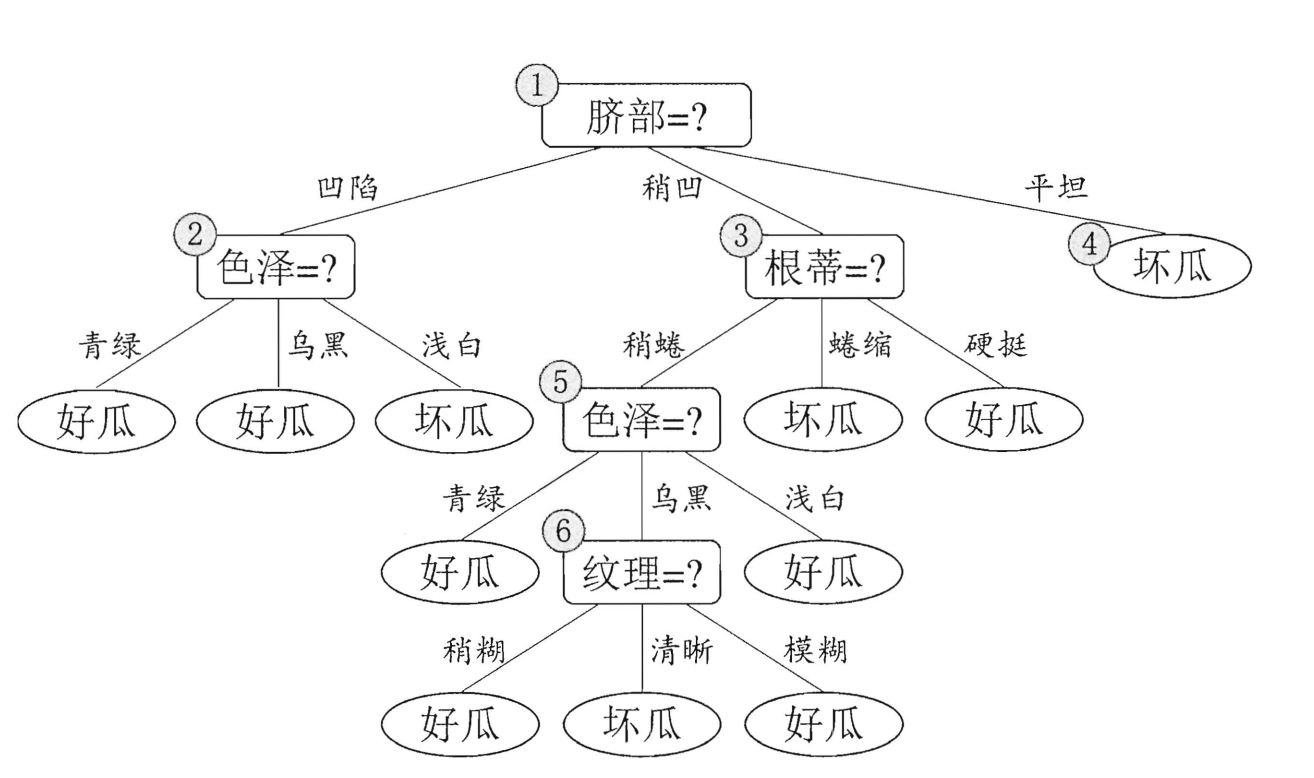
我们继续来看这幅图:
通过验证集,我们易得到该决策树的识别率为42.9%。
让我们重新看一下数据吧,数据集和验证集如下:
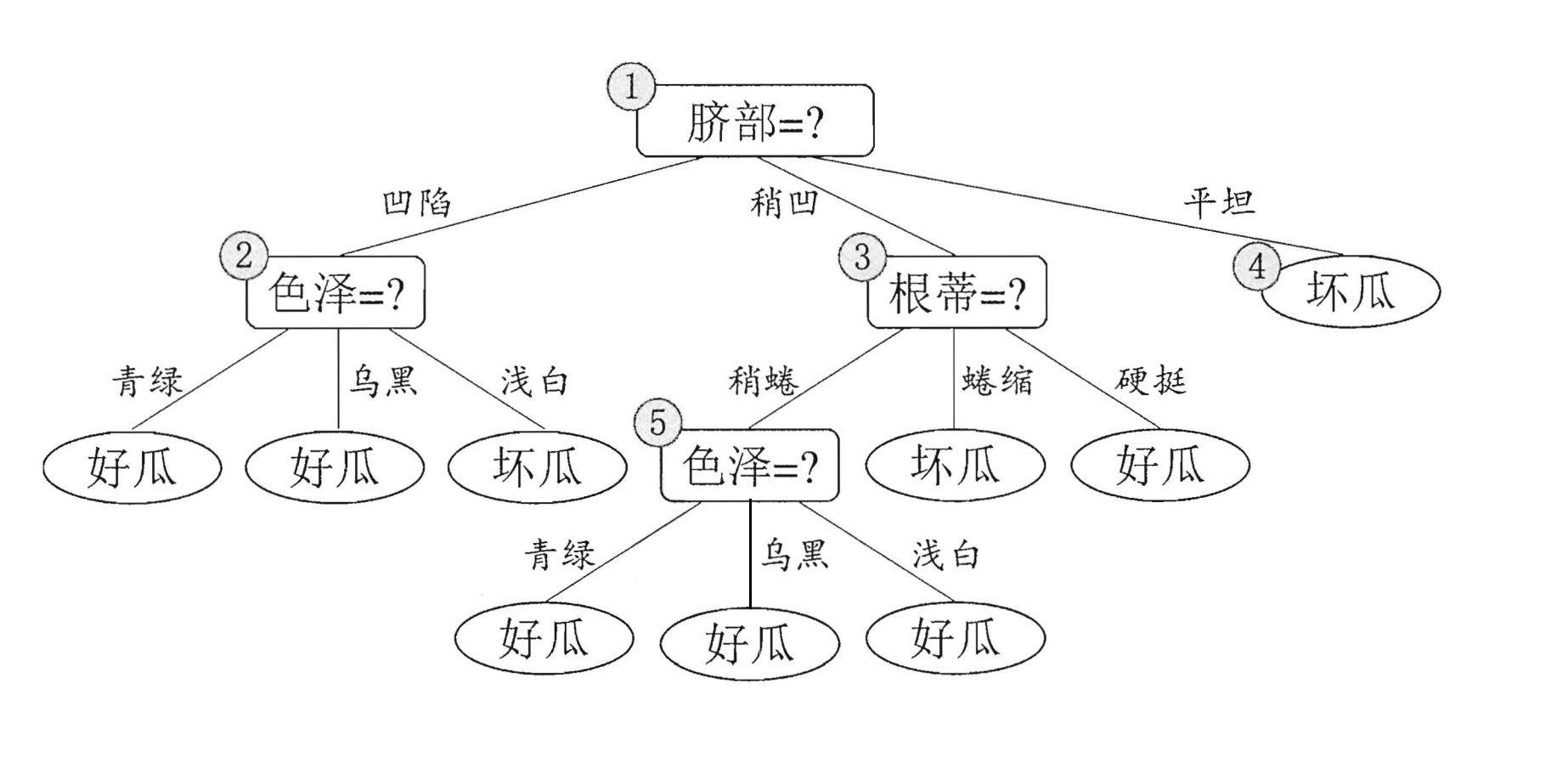
现在让我们来进行剪枝吧!!首先先看节点⑥,节点6中包含编号为{7(好瓜),15(坏瓜)}的训练样本,因此我们将节点⑥变成叶节点并标记为“好瓜(坏瓜也ok)”。如下所示:
在这种情况下,验证集中序号为{4,8,11,12}验证正确,精度调高到
4
7
frac{4}{7}
74×100%=57.1%,因此可以进行剪枝。
考虑结点⑤,包含编号为{6,7,15},将其变成叶节点(标记为“好瓜”),使用验证集去验证,其精度仍为57.1%,没有提高,进行考虑。同理可得到下面的这副图片:
最终,该决策树的精度为71.4%
比较预剪枝和后剪枝,后剪枝保留的分支更多,同时后剪枝的欠拟合的风险很小,泛化性能往往优于预剪枝决策树,但是显而易见,训练的时间要比预剪枝大得多。
参考
https://www.cnblogs.com/xiaohuiduan/p/12490064.html
最后
以上就是香蕉心情最近收集整理的关于【ML】决策树--剪枝处理(预剪枝、后剪枝)的全部内容,更多相关【ML】决策树--剪枝处理(预剪枝、后剪枝)内容请搜索靠谱客的其他文章。








发表评论 取消回复