是否曾想知道一种快速的方法来告知某些文档所关注的内容? 它的主要主题是什么? 让我给你这个简单的把戏。 列出文档中提到的唯一单词,然后检查每个单词被提及了多少次(频率)。 通过这种方式,您可以了解文档的主要内容。 但这手动操作并不容易,所以我们需要一些自动化的过程,不是吗?
是的,自动化过程将使这一过程变得更加容易。 让我们看看如何在文本文件中列出不同的唯一单词,并使用Python检查每个单词的出现频率。
测试文件
在本教程中,我们将使用test.txt作为测试文件。 继续下载它,但是不要打开它! 让我们做一个小游戏。 该测试文件中的文本来自我在Envato Tuts +的其中一篇教程。 根据单词的出现频率,让我们猜出该文本是从我的哪个教程中提取的。
让游戏开始吧!
常用表达
由于我们要在游戏中应用模式,因此我们需要使用正则表达式(regex)。 如果“正则表达式”是您的新名词,那么这是Wikipedia的一个很好的定义:
定义搜索模式的字符序列,主要用于与字符串进行模式匹配或字符串匹配(即类似“查找和替换”的操作)。 这个概念出现于1950年代,当时美国数学家Stephen Kleene将正规语言的描述形式化,并与Unix文本处理实用程序ed(编辑器)和grep(过滤器)共同使用。
如果您想在继续学习本教程之前进一步了解正则表达式,可以查看我的其他教程《 Python中的正则表达式》 ,然后再次回来继续本教程。
建立程序
让我们逐步开发这款游戏。 我们要做的第一件事是将文本文件存储在字符串变量中。
document_text = open('test.txt', 'r')
text_string = document_text.read()现在,为了使我们的正则表达式更容易应用,让我们使用lower()函数将文档中的所有字母变成小写字母,如下所示:
text_string = document_text.read().lower() 让我们写一个正则表达式,它将返回字符数在[3-15]范围内的所有单词。 从3开始,将有助于避免我们可能不想对它们的频率进行计数的单词,例如if , of , in 等等,而长度大于15单词可能不是正确的单词。 这种模式的正则表达式如下所示:
b[a-z]{3,15}b b与单词边界有关 。 有关单词边界的更多信息,可以查看本教程 。
上面的正则表达式可以编写如下:
match_pattern = re.search(r'b[a-z]{3,15}b', text_string) 由于我们要遍历文档中的多个单词,因此可以使用findall函数:
返回string中的pattern的所有非重叠匹配项,作为字符串列表。 从左到右扫描该字符串 ,并以找到的顺序返回匹配项。 如果模式中存在一个或多个组,则返回一个组列表;否则,返回一个列表。 如果模式包含多个组,则这将是一个元组列表。 空匹配项将包括在结果中,除非它们碰到另一个匹配项的开头。
在这一点上,我们希望找到文档中每个单词的出现频率。 此处使用的合适概念是Python的Dictionaries ,因为我们需要key-value对,其中key是word ,并且value表示出现在文档中的频率单词。
假设我们声明了一个空的字典frequency = { } ,则上段如下所示:
for word in match_pattern:
count = frequency.get(word,0)
frequency[word] = count + 1现在,我们可以使用以下命令查看密钥:
frequency_list = frequency.keys()最后,为了获得单词及其频率(出现在文本文件中的次数),我们可以执行以下操作:
for words in frequency_list:
print words, frequency[words]让我们在下一节中将程序放在一起,看看输出是什么样子。
放在一起
在逐步讨论了程序之后,现在让我们看一下程序的外观:
import re
import string
frequency = {}
document_text = open('test.txt', 'r')
text_string = document_text.read().lower()
match_pattern = re.findall(r'b[a-z]{3,15}b', text_string)
for word in match_pattern:
count = frequency.get(word,0)
frequency[word] = count + 1
frequency_list = frequency.keys()
for words in frequency_list:
print words, frequency[words]如果您运行该程序,则应该得到如下内容:
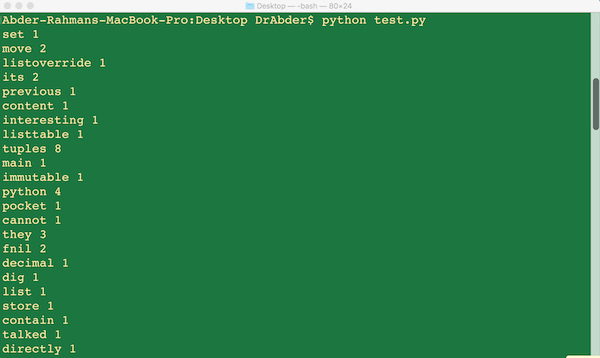
让我们回到我们的游戏。 通过频率一词,您认为测试文件(包含我其他Python教程的内容)在谈论什么?
(提示:以最大频率检查单词)。
翻译自: https://code.tutsplus.com/tutorials/counting-word-frequency-in-a-file-using-python--cms-25965
最后
以上就是优秀小甜瓜最近收集整理的关于使用Python计算文件中的单词频率的全部内容,更多相关使用Python计算文件中内容请搜索靠谱客的其他文章。








发表评论 取消回复