文章转载于:http://www.open-open.com/lib/view/open1455691160276.html
数据库分库分表从互联网时代开启至今,一直是热门话题。在NoSQL横行的今天,关系型数据库凭借其稳定、查询灵活、兼容等特性,仍被大多数公司作为首选数据库。因此,合理采用分库分表技术应对海量数据和高并发对数据库的冲击,是各大互联网公司不可避免的问题。
虽然很多公司都致力于开发自己的分库分表中间件,但截止目前,仍无完美的开源解决方案覆盖此领域。
分库分表适用场景
分库分表用于应对当前互联网常见的两个场景——大数据量和高并发。通常分为垂直拆分和水平拆分两种。
垂直拆分是根据业务将一个库(表)拆分为多个库(表)。如:将经常和不常访问的字段拆分至不同的库或表中。由于与业务关系密切,目前的分库分表产品均使用水平拆分方式。
水平拆分则是根据分片算法将一个库(表)拆分为多个库(表)。如:按照ID的最后一位以3取余,尾数是1的放入第1个库(表),尾数是2的放入第2个库(表)等。
关系型数据库在大于一定数据量的情况下检索性能会急剧下降。在面对互联网海量数据情况时,所有数据都存于一张表,显然会轻易超过数据库表可承受的数据量阀值。这个单表可承受的数据量阀值,需根据数据库和并发量的差异,通过实际测试获得。
单纯的分表虽然可以解决数据量过大导致检索变慢的问题,但无法解决过多并发请求访问同一个库,导致数据库响应变慢的问题。所以通常水平拆分都至少要采用分库的方式,用于一并解决大数据量和高并发的问题。这也是部分开源的分片数据库中间件只支持分库的原因。
但分表也有不可替代的适用场景。最常见的分表需求是事务问题。同在一个库则不需考虑分布式事务,善于使用同库不同表可有效避免分布式事务带来的麻烦。目前强一致性的分布式事务由于性能问题,导致使用起来并不一定比不分库分表快。目前采用最终一致性的柔性事务居多。分表的另一个存在的理由是,过多的数据库实例不利于运维管理。综上所述,最佳实践是合理地配合使用分库+分表。
Sharding-JDBC简介
Sharding-JDBC是当当应用框架ddframe中,从关系型数据库模块dd-rdb中分离出来的数据库水平分片框架,实现透明化数据库分库分表访问。Sharding-JDBC是继dubbox和elastic-job之后,ddframe系列开源的第3个项目。
Sharding-JDBC直接封装JDBC API,可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零:
- 可适用于任何基于Java的ORM框架,如JPA、Hibernate、Mybatis、Spring JDBC Template或直接使用JDBC。
- 可基于任何第三方的数据库连接池,如DBCP、C3P0、 BoneCP、Druid等。
- 理论上可支持任意实现JDBC规范的数据库。虽然目前仅支持MySQL,但已有支持Oracle、SQLServer等数据库的计划。
Sharding-JDBC定位为轻量Java框架,使用客户端直连数据库,以jar包形式提供服务,无proxy代理层,无需额外部署,无其他依赖,DBA也无需改变原有的运维方式。
Sharding-JDBC分片策略灵活,可支持等号、between、in等多维度分片,也可支持多分片键。
SQL解析功能完善,支持聚合、分组、排序、limit、or等查询,并支持Binding Table以及笛卡尔积表查询。
与常见开源产品对比
为了对其他开源项目表示尊重,我们无意评论目前仍在更新中的项目。这里仅列出目前停止更新,但仍然在数据库分片领域非常有影响力的几个项目,请参见表1。
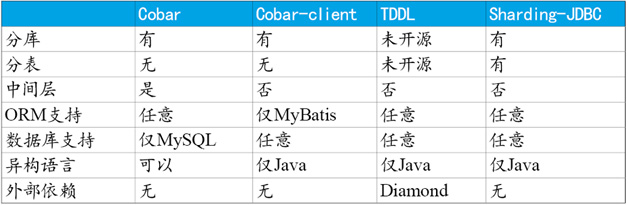
表1 数据库分片工具对比
通过以上表格可以看出,Cobar属于中间层方案,在应用程序和MySQL之间搭建一层Proxy。中间层介于应用程序与数据库间,需要做一次转发,而基于JDBC协议并无额外转发,直接由应用程序连接数据库,性能上有些许优势。这里并非说明中间层一定不如客户端直连,除了性能,需要考虑的因素还有很多,中间层更便于实现监控、数据迁移、连接管理等功能。
Cobar-Client、TDDL和Sharding-JDBC均属于客户端直连方案。此方案的优势在于轻便、兼容性、性能以及对DBA影响小。其中Cobar-Client的实现方式基于ORM(Mybatis)框架,其兼容性与扩展性不如基于JDBC协议的后两者。
实现原理
前文已介绍了Sharding-JDBC是实现了JDBC协议的jar文件。基于JDBC协议的实现与基于MySQL等数据库协议实现的中间层略有差别。
无论使用哪种架构,核心逻辑均极为相似,除了协议实现层不同(JDBC或数据库协议),都会分为分片规则配置、SQL解析、SQL改写、SQL路由、SQL执行以及结果归并等模块。
Sharding-JDBC的整体架构图参见图1。
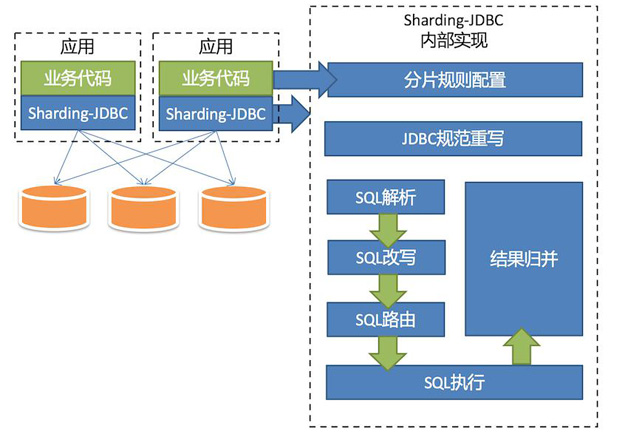
分片规则配置
Sharding-JDBC的分片逻辑非常灵活,支持分片策略自定义、复数分片键、多运算符分片等功能。
如:根据用户ID分库,根据订单ID分表这种分库分表结合的分片策略;或根据年分库,月份+用户区域ID分表这样的多片键分片。
Sharding-JDBC除了支持等号运算符进行分片,还支持in/between运算符分片,提供了更加强大的分片功能。
Sharding-JDBC提供了spring命名空间用于简化配置,以及规则引擎用于简化策略编写。由于目前刚开源分片核心逻辑,这两个模块暂未开源,待核心稳定后将会开源其他模块。
JDBC规范重写
Sharding-JDBC对JDBC规范的重写思路是针对DataSource、Connection、Statement、PreparedStatement和ResultSet五个核心接口封装,将多个真实JDBC实现类集合(如:MySQL JDBC实现/DBCP JDBC实现等)纳入Sharding-JDBC实现类管理。
Sharding-JDBC尽量最大化实现JDBC协议,包括addBatch这种在JPA中会使用的批量更新功能。但分片JDBC毕竟与原生JDBC不同,所以目前仍有未实现的接口,包括Connection游标,存储过程和savePoint相关、ResultSet向前遍历和修改等不太常用的功能。此外,为了保证兼容性,并未实现JDBC 4.1及其后发布的接口(如:DBCP 1.x版本不支持JDBC 4.1)。
SQL解析
SQL解析作为分库分表类产品的核心,性能和兼容性是最重要的衡量指标。目前常见的SQL解析器主要有fdb/jsqlparser和Druid。Sharding-JDBC使用Druid作为SQL解析器,经实际测试,Druid解析速度是另外两个解析器的几十倍。
目前Sharding-JDBC支持join、aggregation(包括avg)、order by、 group by、limit、甚至or查询等复杂SQL的解析。目前不支持union、部分子查询、函数内分片等不太应在分片场景中出现的SQL解析。
SQL改写
SQL改写分为两部分,一部分是将分表的逻辑表名称替换为真实表名称。另一部分是根据SQL解析结果替换一些在分片环境中不正确的功能。这里具两个例子:
第1个例子是avg计算。在分片的环境中,以avg1 +avg2+avg3/3计算平均值并不正确,需要改写为(sum1+sum2+sum3)/(count1+count2+ count3)。这就需要将包含avg的SQL改写为sum和count,然后再结果归并时重新计算平均值。
第2个例子是分页。假设每10条数据为一页,取第2页数据。在分片环境下获取limit 10, 10,归并之后再根据排序条件取出前10条数据是不正确的结果。正确的做法是将分条件改写为limit 0, 20,取出所有前2页数据,再结合排序条件算出正确的数据。可以看到越是靠后的Limit分页效率就会越低,也越浪费内存。有很多方法可避免使用limit进行分页,比如构建记录行记录数和行偏移量的二级索引,或使用上次分页数据结尾ID作为下次查询条件的分页方式。
SQL路由
SQL路由是根据分片规则配置,将SQL定位至真正的数据源。主要分为单表路由、Binding表路由和笛卡尔积路由。
单表路由最为简单,但路由结果不一定落入唯一库(表),因为支持根据between和in这样的操作符进行分片,所以最终结果仍然可能落入多个库(表)。
Binding表可理解为分库分表规则完全一致的主从表。举例说明:订单表和订单详情表都根据订单ID作为分片键,任意时刻分片逻辑均相同。这样的关联查询和单表查询难度和性能相当。
笛卡尔积查询最为复杂,因为无法根据Binding关系定位分片规则的一致性,所以非Binding表的关联查询需要拆解为笛卡尔积组合执行。查询性能较低,而且数据库连接数较高,需谨慎使用。
SQL执行
路由至真实数据源后,Sharding-JDBC将采用多线程并发执行SQL,并完成对addBatch等批量方法的处理。
结果归并
结果归并包括4类:普通遍历类、排序类、聚合类和分组类。每种类型都会先根据分页结果跳过不需要的数据。
普通遍历类最为简单,只需按顺序遍历ResultSet的集合即可。
排序类结果将结果先排序再输出,因为各分片结果均按照各自条件完成排序,所以采用归并排序算法整合最终结果。
聚合类分为3种类型,比较型、累加型和平均值型。比较型包括max和min,只返回最大(小)结果。累加型包括sum和count,需要将结果累加后返回。平均值则是通过SQL改写的sum和count计算,相关内容已在SQL改写涵盖,不再赘述。
分组类最为复杂,需要将所有的ResultSet结果放入内存,使用map-reduce算法分组,最后根据排序和聚合条件做相关处理。最消耗内存,最损失性能的部分即是此,可以考虑使用limit合理的限制分组数据大小。
结果归并部分目前并未采用管道解析的方式,之后会针对这里做更多改进。
性能
路由结果在单库单表的性能测试报告:
查询操作:Sharding-JDBC的TPS为JDBC的TPS的99.8%;
插入操作:Sharding-JDBC的TPS为JDBC的TPS的90.2%;
更新操作:Sharding-JDBC的TPS为JDBC的TPS的93.1%;?
可以看到,Sharding-JDBC性能损失非常低。
路由结果在多库多表的性能测试报告:
查询操作:TPS双库比单库可以增加大约94%的性能;?
插入操作:TPS双库比单库可以增加大约60%的性能;
更新操作:TPS双库比单库可以增加大约89%的性能;?
结果表明,Sharding-JDBC可有效利用多线程与分布式资源大幅度提升性能;?
更多详细情况可查看Sharding-JDBC的性能测试报告。
Roadmap
目前Sharding-JDBC集中于分库分表核心逻辑开发,在功能稳定之后将会按照如下线路持续更新:
- 读写分离;
- 柔性分布式事务;
- 分布式主键生成策略;
- SQL重写优化,进一步提升性能;
- SQL Hint,可指定某SQL在某具体库表执行,基于业务规则而非SQL解析路由;?
小表广播; - HA相关;
- 流量控制;
- 数据库建表工具;
- 数据迁移;
- 复杂SQL解析支持,如子查询、存储过程等;
- Oracle, SQLServer支持;
- 配置中心;
开源理念
目前国内很多开源产品都在公司内部经受过时间的考验,然后剥离业务逻辑和敏感代码,再开源贡献给社区。这样做的优点是开源的产品相对成熟。但缺点也不可避免,主要有:
- 后续支持匮乏。产品已经满足了该公司的业务场景需求,缺乏后续提升的动力。文档、支持也会相对较少,甚至出现文档和代码不同步的状况。
- 与该公司业务场景耦合较为严重。大部分框架产品都是为了解决特定的问题。比如:有的公司可能并不需要分表;有的公司只需支持几种分片策略就好。
- 开源不完整。和公司业务耦合紧密的部分不会开源。
- 缺乏粘度。较为成型的项目由于功能繁多、代码结构复杂,社区志愿者难于扩展或修改核心逻辑。如果测试覆盖率不够,难以保证修改后的代码质量。以上一系列问题会导致项目对社区的粘度不高,难于找寻可合作开发的志愿者。
- 分支众多难于维护。由于开源之后公司缺乏持续提升的动力,和本公司关系不大的需求功能得不到重视,导致各公司都开发自己的分支。开源项目虽然一开始给社区注入了新鲜思想,但最终并没有吸取社区精华。如:Dubbo一出现即引起了相当多的关注,而各公司都有自己的版本,如当当的DubboX,但最终Dubbo并未能持续发展。
我们考虑全新的开源策略,在Sharding-JDBC刚完成初版的时候,即向社区和当当内部同时推广。这样做的好处有:
- 后续支持完善。Sharding-JDBC与当当内部落地绑定,将会在当当内部和社区同时提供支持。虽然无法提供社区需求的优先级高于当当内部的承诺,但我们会综合考虑社区与内部的需求,以更高的视角,尽量整合与优化升级路线。
- 完整开源。代码的snapshot版本都会首先出现在GitHub上。
- 共同发展。Sharding-JDBC目前代码较为简单。使社区开源爱好者能更加轻松地理解代码核心,为以后的持续发展奠定基础。并且Sharding-JDBC也会吸纳社区精华,让更多地爱好者参与代码贡献。
最后需要澄清,未经时间考证的Sharding-JDBC并非Bug成堆,完全不可用的项目。目前测试覆盖率超过90%,详细功能以及不支持项都明确地罗列在GitHub的文档中,希望让使用者心中有数。
最后
以上就是优秀小甜瓜最近收集整理的关于分表分库中间件 sharding-jdbc的全部内容,更多相关分表分库中间件内容请搜索靠谱客的其他文章。








发表评论 取消回复