Python文本分类
**
首先下载安装,用到的库有pandas和jieba库
这个文本分类很简单,并不涉及算法
**
- 源数据是二个excel文件,大约7000条数据,首先把二个文件进行合并成一个DF,这里我用的是pandas,就是把二个文件合并成一个文件,方便后面输入读入。
- 再把文章标题和文章内容合并到一个新列中,我命名为text的列,
- 然后再读取text列数据,按照每行读取一篇文章进行分词,并且统计词语的频率数。然后再根据排序获得词频最高的8个词语,然后把他们存到列表元组中,后面会用到。
- 得到每一篇文章的索引和词频数据后,就可以使用for循换判断这8个词频是和关键字匹配,如果匹配就代表这篇文章有相关性,否则就是不相关,
- 最后把文章索引ID和文章关联结果存到一个新的csv文件中。
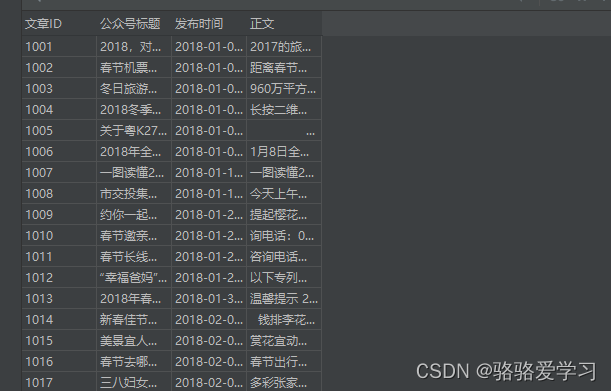
下面是源文章数据结构,正文内容很长
下面是文章关键词,用于判断文章相关性
key_words = ["旅游", "亲子游", "旅游", "活动", "节庆", "特产", "交通", "酒店",
"景区", "景点", "文创", "文化", "乡村旅游", "民宿", "假日", "假期", "游客","采摘", "赏花",
"春游", "踏青", "康养", "公园", "滨海游", "度假",
"农家乐", "剧本杀", "旅行", "徒步", "工业旅游", "线路", "自驾游",
"团队游", "攻略", "游记", "包车", "玻璃栈道", "游艇", "高尔夫", "温泉", "游客", "门票"]
下面是文章全部代码
#需要用到的库有pandas和jieba库
#使用代码之前需要先安装上面的二个库
# encoding=utf-8
import jieba
import pandas as pd
key_words = ["旅游", "亲子游", "旅游", "活动", "节庆", "特产", "交通", "酒店", "景区", "景点", "文创", "文化", "乡村旅游", "民宿", "假日", "假期", "游客",
"采摘", "赏花", "春游", "踏青",
"康养", "公园", "滨海游", "度假", "农家乐", "剧本杀", "旅行", "徒步", "工业旅游", "线路", "自驾游",
"团队游", "攻略", "游记", "包车", "玻璃栈道", "游艇", "高尔夫", "温泉", "游客", "门票"]
df_1 = pd.read_excel("data/data/2018-2019.xlsx", sheet_name="微信公众号新闻", index_col=0, usecols=[0, 1, 3])
df_2 = pd.read_excel("data/data/2020-2021.xlsx", sheet_name="微信公众号新闻", index_col=0, usecols=[0, 1, 3])
Raw_Data = pd.concat([df_1, df_2], join="outer", sort=True)
Raw_Data['text'] = Raw_Data['公众号标题'] + 'n' + Raw_Data['正文']
train_data = []
for index, data in Raw_Data.iterrows():
data = str(data).strip("")
if len(data) < 100:
data_text = "据悉,茂名六韬珠宝于2017年9月成功获得“广东省省级文化产业示范园区”创建资格。如今,创建期满。经过省文旅厅、各级政府和企业的共同努力,"
"示范园区的创建工作按工作规划和步骤扎实开展,方方面面的建设有了较大的推进,不论是本园区的发展壮大还是对本地经济的引领带动都富有成效。"
"六韬珠宝自创建省级文化产业示范园区以来,建设目标明确,通过土地集约、合理配置资源、科学规划生产链,以承接珠三角加工贸易企业转移为目标,"
"打造以特色轻工产业及文创产业为主的产业聚集地,带动连带产业发展为主要抓手推动园区建设。园区已成功引进美国、英国、香港、台湾以及珠三角等地区的130多家企业入园。"
"先后接待了来自境内外的企业家5000人次到园区洽谈交流,逐步培育成具有国际视野和发展思路的产业园区。" * 2
words = jieba.lcut(data_text)
else:
words = jieba.lcut(data)
# words = jieba.lcut(data_pius)
counts = {} # 通过键值对的形式存储词语及其出现的次数
counts_2 = {}
dicts = {}
list_index = []
suo_yin = []
for word in words:
if len(word) == 1: # 单个词语不计算在内
continue
else:
counts[word] = counts.get(word, 0) + 1 # 遍历所有词语,每出现一次其对应的值加 1
suo_yin = index
items = list(counts.items()) # 将键值对转换成列表
items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序
for i in range(10):
word, count = items[i]
counts_2[word] = counts.get(word, count)
list_index = list(counts_2)
list_index.insert(0, index)
train_data.append(list_index)
df = pd.DataFrame(train_data)
df.set_index(0, inplace=True)
d_f = []
for index, col in df.iterrows():
data = list(col)
# print(index, a)
for x in data:
for word in key_words:
if word == x:
y = (index, "相关")
d_f.append(y)
break
else:
n = (index, "不相关")
d_f.append(n)
data_text_end = pd.DataFrame(d_f)
data_text_end = data_text_end.drop_duplicates([0, 1])
v = data_text_end[data_text_end.duplicated(0, keep=False)]
group_1 = v.groupby(by=0)
data_group = pd.DataFrame(list(group_1))
data_group.set_index(0, inplace=True)
data_group.to_csv("2.csv")
data_group[1] = "相关"
data_text_end.drop_duplicates(0, inplace=True, keep=False)
#
data_text_end.set_index(0, inplace=True)
Data = pd.concat([data_text_end, data_group], join="outer", sort=True, names=["ID", "相关性"])
Data_end = Data.sort_index()
Data_end = Data_end.reset_index()
Data_end.rename(columns={0: "文章ID", 1: "相关性"}, inplace=True)
Data_end.set_index("文章ID", inplace=True)
Data_end.to_csv("data.csv")
print(Data_end)
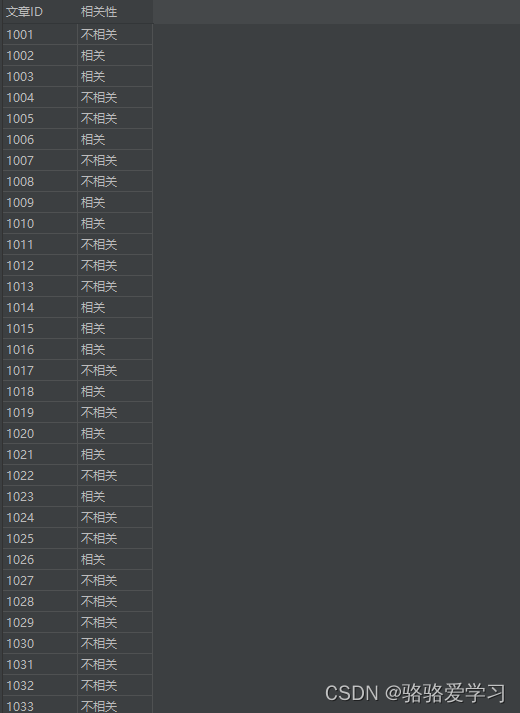
最后把结果数据存在data.csv中,数据结构是一下面这样,这个结果会有误差,但我实际查看,误差不会太大,如果需要更高的准确率,那就需要算法了
本博客更新与2022.4.30日18.40分
最后
以上就是缓慢玉米最近收集整理的关于Python文本分类(不涉及算法)的全部内容,更多相关Python文本分类(不涉及算法)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复