kubernetes kube-scheduler 调度器
tags: 组件

文章目录
- kubernetes kube-scheduler 调度器
- 1. 简介
- 2. kube-scheduler 调度流程
- 3. 调度器工作原理
- 4. 调度器性能调优
- 4.1 设置阈值
- 4.2 节点打分阈值
- 4.3 调节 percentageOfNodesToScore 参数
- 4.4 调度器做调度选择的时候如何覆盖所有的 Node
在 Kubernetes 中,调度 是指将 Pod 放置到合适的 Node 上,然后对应 Node 上的 Kubelet 才能够运行这些 pod。
1. 简介
kube-scheduler 是 Kubernetes 集群的默认调度器,并且是集群 控制面 的一部分。 如果你真的希望或者有这方面的需求,kube-scheduler 在设计上是允许 你自己写一个调度组件并替换原有的 kube-scheduler。
对每一个新创建的 Pod 或者是未被调度的 Pod,kube-scheduler 会选择一个最优的 Node 去运行这个 Pod。然而,Pod 内的每一个容器对资源都有不同的需求,而且 Pod 本身也有不同的资源需求。因此,Pod 在被调度到 Node 上之前, 根据这些特定的资源调度需求,需要对集群中的 Node 进行一次过滤。
在一个集群中,满足一个 Pod 调度请求的所有 Node 称之为 可调度节点。 如果没有任何一个 Node 能满足 Pod 的资源请求,那么这个 Pod 将一直停留在 未调度状态直到调度器能够找到合适的 Node。
调度器先在集群中找到一个 Pod 的所有可调度节点,然后根据一系列函数对这些可调度节点打分, 选出其中得分最高的 Node 来运行 Pod。之后,调度器将这个调度决定通知给 kube-apiserver,这个过程叫做 绑定。
在做调度决定时需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、 亲和以及反亲和要求、数据局域性、负载间的干扰等等
2. kube-scheduler 调度流程
kube-scheduler 给一个 pod 做调度选择包含两个步骤:
- 过滤----
Predicate的调度算法 - 打分----
Priority的调度算法
过滤阶段会将所有满足 Pod 调度需求的 Node 选出来。 例如,PodFitsResources 过滤函数会检查候选 Node 的可用资源能否满足 Pod 的资源请求。 在过滤之后,得出一个 Node 列表,里面包含了所有可调度节点;通常情况下, 这个 Node 列表包含不止一个 Node。如果这个列表是空的,代表这个 Pod 不可调度。
在打分阶段,调度器会为 Pod 从所有可调度节点中选取一个最合适的 Node。 根据当前启用的打分规则,调度器会给每一个可调度节点进行打分。
最后,kube-scheduler 会将 Pod 调度到得分最高的 Node 上。 如果存在多个得分最高的 Node,kube-scheduler 会从中随机选取一个。
支持以下两种方式配置调度器的过滤和打分行为:
- 调度策略 允许你配置过滤的
谓词(Predicates)和打分的 优先级(Priorities)。 - 调度配置 允许你配置实现不同调度阶段的插件, 包括:QueueSort, Filter, Score, Bind, Reserve, Permit 等等。 你也可以配置 kube-scheduler 运行不同的配置文件。
调度器对一个 Pod 调度成功,实际上就是将它的 spec.nodeName 字段填上调度结果的节点名字。
3. 调度器工作原理
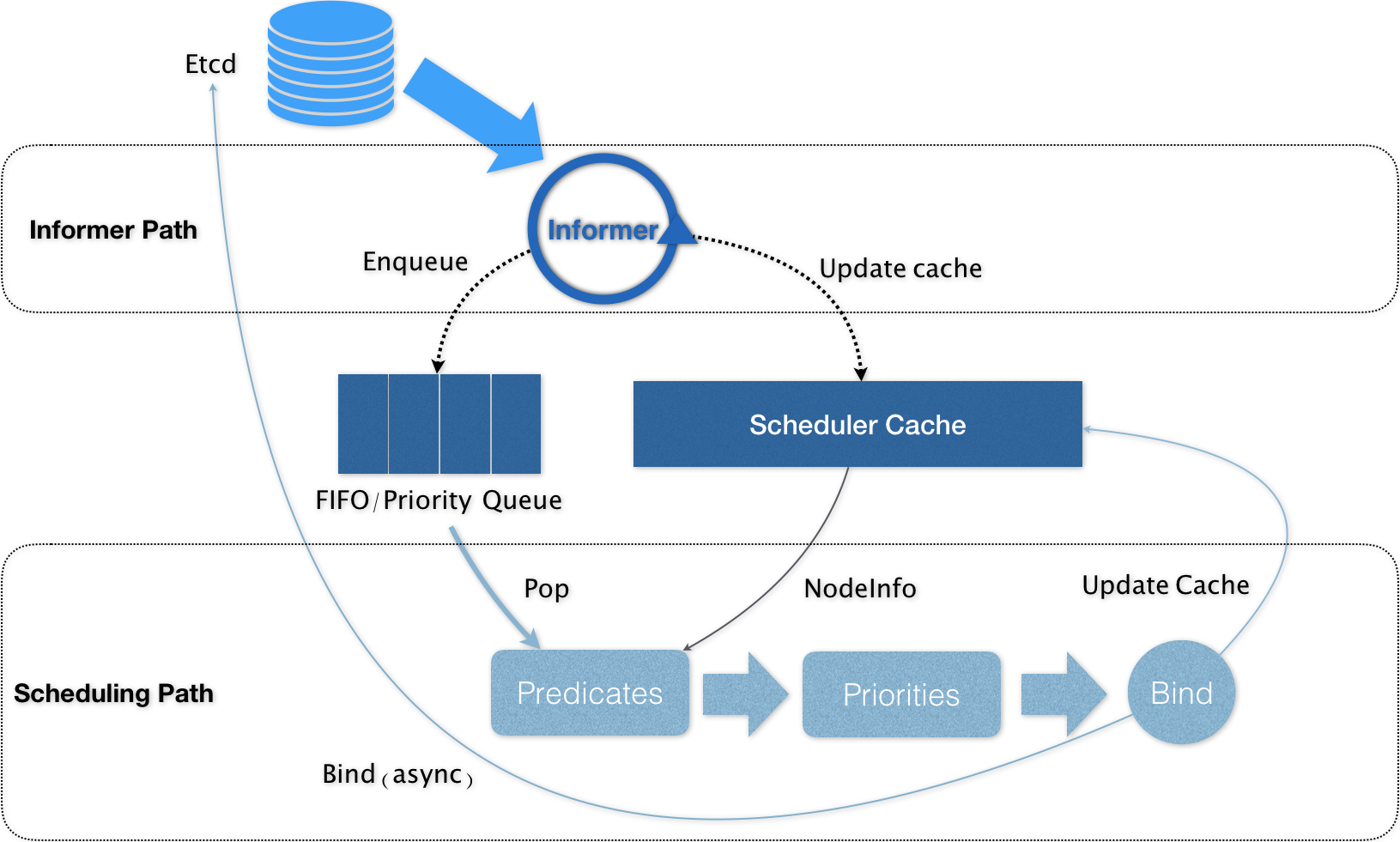
可以看到,Kubernetes 的调度器的核心,实际上就是两个相互独立的控制循环。
其中,第一个控制循环,我们可以称之为 Informer Path。它的主要目的,是启动一系列 Informer,用来监听(Watch)Etcd 中 Pod、Node、Service 等与调度相关的 API 对象的变化。比如,当一个待调度 Pod(即:它的 nodeName 字段是空的)被创建出来之后,调度器就会通过 Pod Informer 的 Handler,将这个待调度 Pod 添加进调度队列。
在默认情况下,Kubernetes 的调度队列是一个 PriorityQueue(优先级队列),并且当某些集群信息发生变化的时候,调度器还会对调度队列里的内容进行一些特殊操作。这里的设计,主要是出于调度优先级和抢占的考虑。
此外,Kubernetes 的默认调度器还要负责对调度器缓存(即:scheduler cache)进行更新。事实上,Kubernetes 调度部分进行性能优化的一个最根本原则,就是尽最大可能将集群信息 Cache 化,以便从根本上提高 Predicate 和 Priority 调度算法的执行效率。
而第二个控制循环,是调度器负责 Pod 调度的主循环,我们可以称之为 Scheduling Path。
Scheduling Path 的主要逻辑,就是不断地从调度队列里出队一个 Pod。然后,调用 Predicates 算法进行“过滤”。这一步“过滤”得到的一组 Node,就是所有可以运行这个 Pod 的宿主机列表。当然,Predicates 算法需要的 Node 信息,都是从 Scheduler Cache 里直接拿到的,这是调度器保证算法执行效率的主要手段之一。
接下来,调度器就会再调用 Priorities 算法为上述列表里的 Node 打分,分数从 0 到 10。得分最高的 Node,就会作为这次调度的结果。
调度算法执行完成后,调度器就需要将 Pod 对象的 nodeName 字段的值,修改为上述 Node 的名字。这个步骤在 Kubernetes 里面被称作 Bind。
但是,为了不在关键调度路径里远程访问 APIServer,Kubernetes 的默认调度器在 Bind 阶段,只会更新 Scheduler Cache 里的 Pod 和 Node 的信息。这种基于“乐观”假设的 API 对象更新方式,在 Kubernetes 里被称作 Assume。
Assume 之后,调度器才会创建一个 Goroutine 来异步地向 APIServer 发起更新 Pod 的请求,来真正完成 Bind 操作。如果这次异步的 Bind 过程失败了,其实也没有太大关系,等 Scheduler Cache 同步之后一切就会恢复正常。
当然,正是由于上述 Kubernetes 调度器的“乐观”绑定的设计,当一个新的 Pod 完成调度需要在某个节点上运行起来之前,该节点上的 kubelet 还会通过一个叫作 Admit 的操作来再次验证该 Pod 是否确实能够运行在该节点上。这一步 Admit 操作,实际上就是把一组叫作 GeneralPredicates 的、最基本的调度算法,比如:“资源是否可用”“端口是否冲突”等再执行一遍,作为 kubelet 端的二次确认。
除了上述的“Cache 化”和“乐观绑定”,Kubernetes 默认调度器还有一个重要的设计,那就是“无锁化”。
在 Scheduling Path 上,调度器会启动多个 Goroutine 以节点为粒度并发执行 Predicates 算法,从而提高这一阶段的执行效率。而与之类似的,Priorities 算法也会以 MapReduce 的方式并行计算然后再进行汇总。而在这些所有需要并发的路径上,调度器会避免设置任何全局的竞争资源,从而免去了使用锁进行同步带来的巨大的性能损耗。
所以,在这种思想的指导下,如果你再去查看一下前面的调度器原理图,你就会发现,Kubernetes 调度器只有对调度队列和 Scheduler Cache 进行操作时,才需要加锁。而这两部分操作,都不在 Scheduling Path 的算法执行路径上。
当然,Kubernetes 调度器的上述设计思想,也是在集群规模不断增长的演进过程中逐步实现的。尤其是 “Cache 化”,这个变化其实是最近几年 Kubernetes 调度器性能得以提升的一个关键演化。
不过,随着 Kubernetes 项目发展到今天,它的默认调度器也已经来到了一个关键的十字路口。事实上,Kubernetes 现今发展的主旋律,是整个开源项目的“民主化”。也就是说,Kubernetes 下一步发展的方向,是组件的轻量化、接口化和插件化。所以,我们才有了 CRI、CNI、CSI、CRD、Aggregated APIServer、Initializer、Device Plugin 等各个层级的可扩展能力。可是,默认调度器,却成了 Kubernetes 项目里最后一个没有对外暴露出良好定义过的、可扩展接口的组件。
Kubernetes 默认调度器的可扩展性设计,可以用如下所示的一幅示意图来描述:
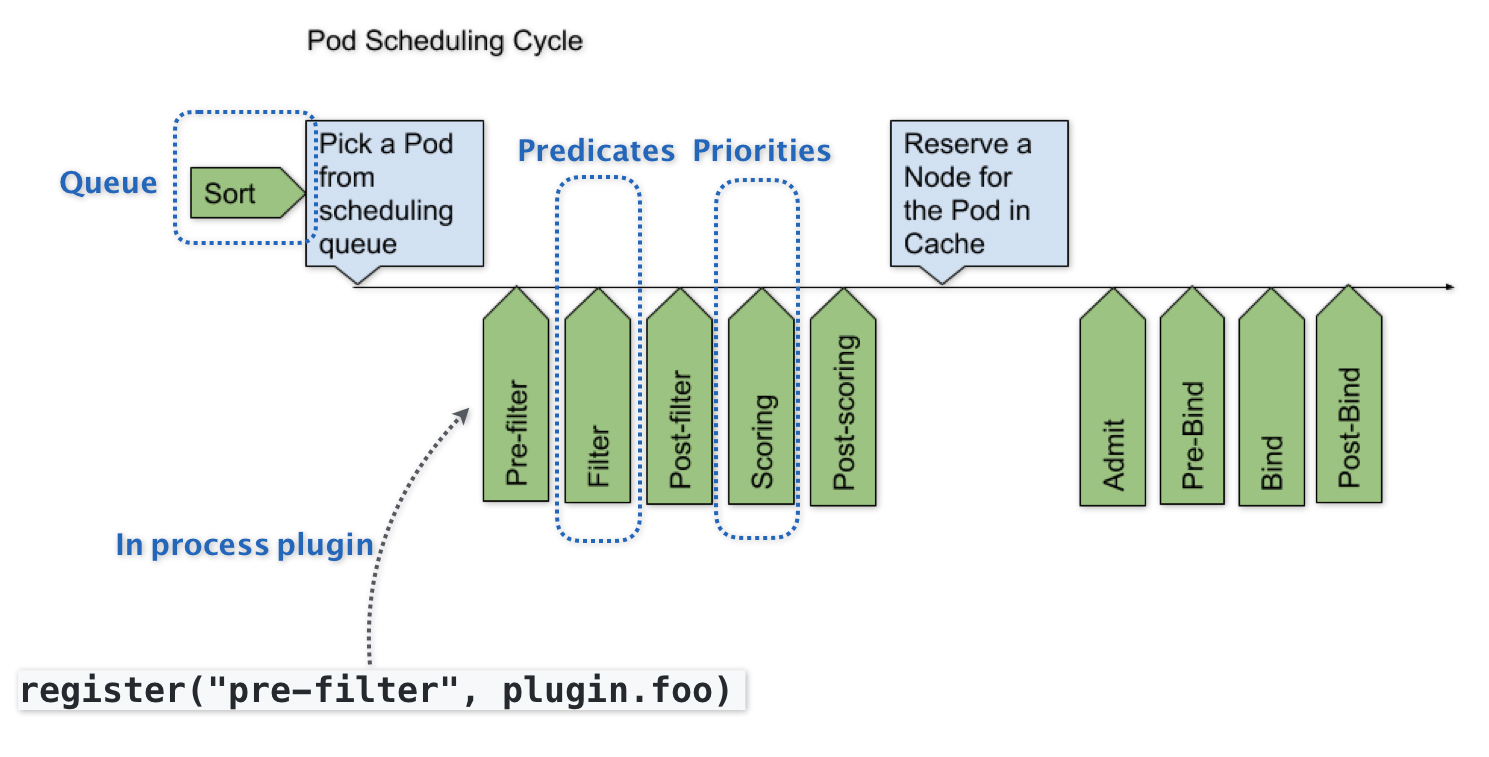
可以看到,默认调度器的可扩展机制,在 Kubernetes 里面叫作 Scheduler Framework。顾名思义,这个设计的主要目的,就是在调度器生命周期的各个关键点上,为用户暴露出可以进行扩展和实现的接口,从而实现由用户自定义调度器的能力。
上图中,每一个绿色的箭头都是一个可以插入自定义逻辑的接口。比如,上面的 Queue 部分,就意味着你可以在这一部分提供一个自己的调度队列的实现,从而控制每个 Pod 开始被调度(出队)的时机。
而 Predicates 部分,则意味着你可以提供自己的过滤算法实现,根据自己的需求,来决定选择哪些机器。
4. 调度器性能调优
在大规模集群中,你可以调节调度器的表现来平衡调度的延迟(新 Pod 快速就位) 和精度(调度器很少做出糟糕的放置决策)。
你可以通过设置 kube-scheduler 的 percentageOfNodesToScore 来配置这个调优设置。 这个 KubeSchedulerConfiguration 设置决定了调度集群中节点的阈值。
4.1 设置阈值
percentageOfNodesToScore 选项接受从 0 到 100 之间的整数值。 0 值比较特殊,表示 kube-scheduler 应该使用其编译后的默认值。 如果你设置 percentageOfNodesToScore 的值超过了 100, kube-scheduler 的表现等价于设置值为 100。
要修改这个值,编辑 kube-scheduler 的配置文件 (通常是 /etc/kubernetes/config/kube-scheduler.yaml), 然后重启调度器。
修改完成后,你可以执行
kubectl get pods -n kube-system | grep kube-scheduler
来检查该 kube-scheduler 组件是否健康。
4.2 节点打分阈值
要提升调度性能,kube-scheduler 可以在找到足够的可调度节点之后停止查找。 在大规模集群中,比起考虑每个节点的简单方法相比可以节省时间。
你可以使用整个集群节点总数的百分比作为阈值来指定需要多少节点就足够。 kube-scheduler 会将它转换为节点数的整数值。在调度期间,如果 kube-scheduler 已确认的可调度节点数足以超过了配置的百分比数量, kube-scheduler 将停止继续查找可调度节点并继续进行 打分阶段。
默认阈值
如果你不指定阈值,Kubernetes 使用线性公式计算出一个比例,在 100-节点集群 下取 50%,在 5000-节点的集群下取 10%。这个自动设置的参数的最低值是 5%。
这意味着,调度器至少会对集群中 5% 的节点进行打分,除非用户将该参数设置的低于 5。
如果你想让调度器对集群内所有节点进行打分,则将 percentageOfNodesToScore 设置为 100。
示例
下面就是一个将 percentageOfNodesToScore 参数设置为 50% 的例子。
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
algorithmSource:
provider: DefaultProvider
...
percentageOfNodesToScore: 50
4.3 调节 percentageOfNodesToScore 参数
percentageOfNodesToScore 的值必须在 1 到 100 之间,而且其默认值是通过集群的规模计算得来的。 另外,还有一个 50 个 Node 的最小值是硬编码在程序中。
说明: 当集群中的可调度节点少于 50 个时,调度器仍然会去检查所有的 Node, 因为可调度节点太少,不足以停止调度器最初的过滤选择。
同理,在小规模集群中,如果你将 percentageOfNodesToScore 设置为 一个较低的值,则没有或者只有很小的效果。
如果集群只有几百个节点或者更少,请保持这个配置的默认值。 改变基本不会对调度器的性能有明显的提升。
值得注意的是,该参数设置后可能会导致只有集群中少数节点被选为可调度节点, 很多节点都没有进入到打分阶段。这样就会造成一种后果, 一个本来可以在打分阶段得分很高的节点甚至都不能进入打分阶段。
由于这个原因,这个参数不应该被设置成一个很低的值。 通常的做法是不会将这个参数的值设置的低于 10。 很低的参数值一般在调度器的吞吐量很高且对节点的打分不重要的情况下才使用。 换句话说,只有当你更倾向于在可调度节点中任意选择一个节点来运行这个 Pod 时, 才使用很低的参数设置。
4.4 调度器做调度选择的时候如何覆盖所有的 Node
在将 Pod 调度到节点上时,为了让集群中所有节点都有公平的机会去运行这些 Pod, 调度器将会以轮询的方式覆盖全部的 Node。 你可以将 Node 列表想象成一个数组。调度器从数组的头部开始筛选可调度节点, 依次向后直到可调度节点的数量达到 percentageOfNodesToScore 参数的要求。 在对下一个 Pod 进行调度的时候,前一个 Pod 调度筛选停止的 Node 列表的位置, 将会来作为这次调度筛选 Node 开始的位置。
如果集群中的 Node 在多个区域,那么调度器将从不同的区域中轮询 Node, 来确保不同区域的 Node 接受可调度性检查。如下例,考虑两个区域中的六个节点:
Zone 1: Node 1, Node 2, Node 3, Node 4
Zone 2: Node 5, Node 6
调度器将会按照如下的顺序去评估 Node 的可调度性:
Node 1, Node 5, Node 2, Node 6, Node 3, Node 4
在评估完所有 Node 后,将会返回到 Node 1,从头开始。
最后
以上就是细心绿茶最近收集整理的关于kubernetes kube-scheduler 调度器kubernetes kube-scheduler 调度器的全部内容,更多相关kubernetes内容请搜索靠谱客的其他文章。








发表评论 取消回复