深度学习之循环神经网络(1)序列表示方法
- 序列表示方法
- Embedding层
- 2. 预训练的词向量
前面的卷积神经网络利用数据的局部相关性和权值共享的思想大大减少了网络的参数量,非常适合于图片这种具有 空间(Spatial)局部相关性的数据,已经被成功地应用到计算机视觉领域的一系列任务上。自然界的信号除了具有空间维度外,还有一个 时间(Temporal)维度。具有时间维度的信号非常常见,比如我们正在阅读的文本、说话时发出的语音信号、随着时间变化的股市参数等。这类数据并不一定具有局部相关性,同时数据在时间维度上的长度也是可变的,卷积神经网络并不擅长处理此类数据。
那么如何解决这一类信号的分析、识别等问题是将人工智能推向通用人工智能路上必须解决的一项任务。本章将要介绍的循环神经网络可以较好地解决此类问题。在介绍循环神经网络之前,首先我们来介绍对于具有时间先后顺序的数据的表示方法。
序列表示方法
具有先后顺序的数据一般叫做序列(Sequence),比如随时间而变化的商品价格数据就是非常典型的序列。考虑某件商品A在1月到6月之间的价格变化趋势,我们记为一维向量:
[
x
1
,
x
2
,
x
3
,
x
4
,
x
5
,
x
6
]
[x_1,x_2,x_3,x_4,x_5,x_6]
[x1,x2,x3,x4,x5,x6],它的shape为
[
6
]
[6]
[6]。如果要表示b件商品在1月到6月之间的价格变化趋势,科技委2维张量:
[
[
x
1
(
1
)
,
x
2
(
1
)
,
…
,
x
6
(
1
)
]
,
[
x
1
(
2
)
,
x
2
(
2
)
,
…
,
x
6
(
2
)
]
,
…
,
[
x
1
(
b
)
,
x
2
(
b
)
,
…
,
x
6
(
b
)
]
]
[[x_1^{(1)},x_2^{(1)},…,x_6^{(1)} ],[x_1^{(2)},x_2^{(2)},…,x_6^{(2)} ],…,[x_1^{(b)},x_2^{(b)},…,x_6^{(b)} ]]
[[x1(1),x2(1),…,x6(1)],[x1(2),x2(2),…,x6(2)],…,[x1(b),x2(b),…,x6(b)]]
其中
b
b
b表示商品的数量,张量shape为
[
b
,
6
]
[b,6]
[b,6]。
这么看来,序列信号表示起来并不很麻烦,只需要一个shape为
[
b
,
s
]
[b,s]
[b,s]的张量即可,其中
b
b
b为序列数量,
s
s
s为序列长度。但是对于很多信号并不能直接使用一个标量数值表示,比如每个时间戳产生长度为
n
n
n的特征向量,则shape为
[
b
,
s
,
n
]
[b,s,n]
[b,s,n]的张量才能表示。考虑更复杂的文本数据: 句子。它在每个时间戳上面产生的单词是一个字符,并不是数值,不能直接运用某个标量表示。我们已经知道神经网络本质上是一系列的矩阵相乘、相加等数学运算,它并不能够直接处理字符串类型的数据。如果希望神经网络能够用于自然语言处理任务,那么怎么把单词或字符转化为数值就变得尤为关键。接下来我们主要探讨文本序列的表示方法,其他非数值类型的信号可以参考文本序列的表示方法。
对于一个含有
n
n
n个单词的句子,单词的一种简单表示方法就是前面我们介绍的One-hot编码。以英文句子为例,假设我们只考虑最常用的10000个单词,那么每个单词就可以表示为某位为1,其它位置为0且长度为10000的稀疏One-hot向量; 对于中文句子,如果也只考虑最常用的5000个汉字,同样的方法,一个汉字可以用长度为5000的One-hot向量表示。如下图所示,如果只考虑n个地名单词,可以将每个地名编码为长度为n的One-hot向量。
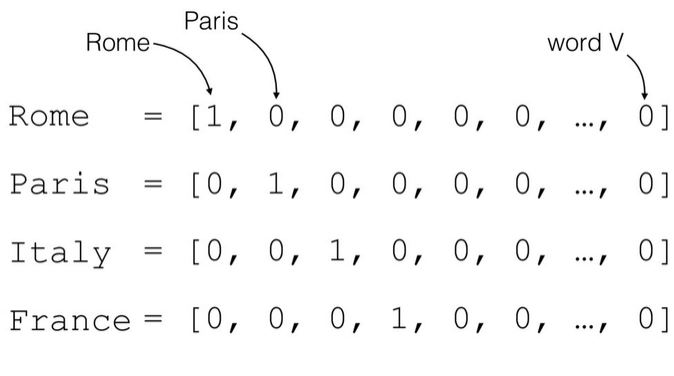
我们把文字编码为Word Embedding。One-hot编码方式实现Word Embedding简单直观,编码过程不需要学习和训练。但是One-hot编码的向量是高纬度而且及其稀疏的,大量的位置为0,计算效率较低,同时也不利于神经网络的训练。从语义角度来讲,One-hot编码还有一个严重的问题,它忽略了单词先天具有的语义相关性。举个例子,对于单词“like”、“dislike”、“Rome”、“Paris”来说,“like”和“dislike”在语义角度就强相关,它们都表示喜欢的程度; “Rome”和“Paris”同样也是强相关,它们都表示欧洲的两个地点。对于一组这样的单词来说,如果采用One-hot编码,得到的向量之间没有相关性,不能很好地体现原有文字的语义相关度,因此One-hot编码具有明显的缺陷。
在自然语言处理领域,有专门的一个研究方向在探索如何学习到单词的表示向量(Word Vector),使得语义层面的相关性能够很好地通过Word Vector体现出来。一个衡量词向量之间相关度的方法就是余弦相关度(Cosine similarity):
similarity
(
a
,
b
)
≜
cos
(
θ
)
=
a
⋅
b
∣
a
∣
⋅
∣
b
∣
text{similarity}(boldsymbol a,boldsymbol b)≜text{cos}(θ)=frac{boldsymbol acdot boldsymbol b}{|boldsymbol a|cdot|boldsymbol b|}
similarity(a,b)≜cos(θ)=∣a∣⋅∣b∣a⋅b
其中
a
boldsymbol a
a和
b
boldsymbol b
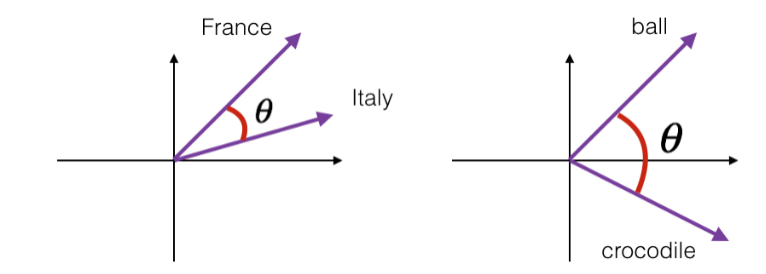
b代表了两个词向量。下图演示了单词“France”和“Italy”的相似度,以及单词“ball”和“crocodile”的相似度,
θ
θ
θ为两个词向量之间的夹角。可以看到
cos
(
θ
)
text{cos}(θ)
cos(θ)较好地反映了语义相关性。
Embedding层
在神经网络中,单词的表示向量可以直接通过训练的方式得到,我们把单词的表示层叫做Embedding层。Embedding层负责把单词编码为某个词向量
v
boldsymbol v
v,它接受的是采用数字编码的单词符号
i
i
i,如2表示“I”,3表示“me”等,系统总单词数量记为
N
vocab
N_text{vocab}
Nvocab,输入长度为
n
n
n的向量
v
boldsymbol v
v:
v
=
f
θ
(
i
∣
N
vocab
,
n
)
v=f_θ (i|N_text{vocab},n)
v=fθ(i∣Nvocab,n)
Embedding层实现起来非常简单,构建一个shape为
[
N
vocab
,
n
]
[N_text{vocab},n]
[Nvocab,n]的查询表对象table,对于任意的单词编号
i
i
i,只需要查询到对应位置上的向量并返回即可:
v
=
t
a
b
l
e
[
i
]
boldsymbol v=table[i]
v=table[i]
Embedding层是可训练的,它可放置在神经网络之前,完成单词到向量的转换,得到的表示向量可以继续通过神经网络完成后续任务,并计算误差
L
mathcal L
L,采用梯度下降算法来实现端到端(end-to-end)的训练。
在TensorFlow中,可以通过layers.Embedding(
N
vocab
N_text{vocab}
Nvocab,
n
n
n)来定义一个Word Embedding层,其中
N
vocab
N_text{vocab}
Nvocab参数指定词汇数量,
n
n
n指定单词向量的长度。例如:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
x = tf.range(10) # 生成10个单词的数字编码
x = tf.random.shuffle(x) # 打散
# 创建共10个单词,每个单词用长度为4的向量表示的层
net = layers.Embedding(10, 4)
out = net(x) # 获取词向量
print(out)
运行结果如下图所示:

上述代码创建了10个单词的Embedding层,每个单词用长度为4的向量表示,可以传入数字编码为0~9的输入,得到这4个单词的词向量,这些词向量随机初始化的,尚未经过网络训练。
我们还可以直接查看Embedding层内部的查询表table:
# 查看Embedding层内部的查询表table
print(net.embeddings)
运行结果如下图所示:

并查看net.embeddings张量的可优化属性为True,即可以通过梯度下降算法优化。
# 查看net.embeddings张量的可优化属性为True,即可以通过梯度下降算法优化
print(net.embeddings.trainable)
运行结果如下图所示:

2. 预训练的词向量
Embedding层的查询表是随机初始化的,需要从零开始训练。实际上,我们可以使用预训练的Word Embedding模型来得到单词的表示方法,基于预训练模型的词向量相当于迁移了整个语义空间的知识,往往能得到更好的性能。
目前应用的比较广泛的预训练模型由Word2Vec和GloVe等。它们已经在海量语料库训练得到了较好的词向量表示方法,并可以直接导出学习到的词向量表,方便迁移到其它任务。比如GloVe模型GloVe.6B.50d,词汇量为40万,每个单词使用长度为50的向量表示,用户只需要下载对应的模型文件即可,“glove6b50dtxt.zip”模型文件约69MB。
那么如何使用这些预训练的词向量模型来帮助提升NLP任务的性能呢?非常简单,对应Embedding层,不再采用随机初始化的方式,而是利用我们已经预训练好的模型参数去初始化Embedding层的查询表。例如:
# 从预训练模型中加载词向量表
embed_glove = load_embed('glove.6B.50d.txt')
# 直接利用预训练的词向量表初始化Embedding层
net.set_weights([embed_glove])
经过预训练的词向量模型初始化的Embedding层可以设置为不参与训练: net.trainable=False,那么预训练的词向量就直接应用到此特定任务上; 如果希望能够学到区别于预训练词向量模型不同的表示方法,那么就可以把Embedding层包含进反向传播算法中去,利用梯度下降来微调单词表示方法。
最后
以上就是体贴枕头最近收集整理的关于深度学习之循环神经网络(1)序列表示方法序列表示方法2. 预训练的词向量的全部内容,更多相关深度学习之循环神经网络(1)序列表示方法序列表示方法2.内容请搜索靠谱客的其他文章。








发表评论 取消回复