目录
- 前言
- payloadType
- sample rate
- gain
- bitwidth
- AEC(Auto echo cancellation)
- AGC(Automatic Gain Control)
- NS(Noise suppression)
- HPF(High Pass Filter)
- BSS(Blind Source Separation)
- BF(Beamforming)
- DOA(Direction of arrival)SD(sound localization)
- DER(Dereverberation)
前言
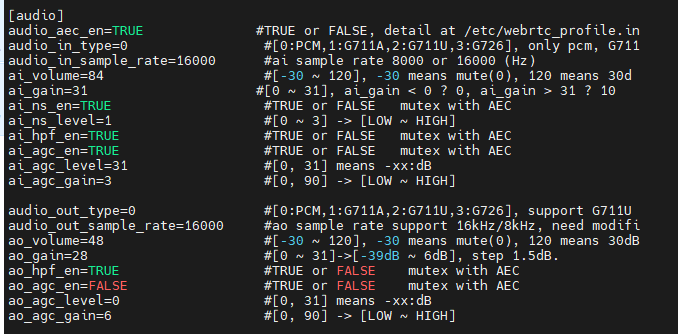
做项目的时候看到很多音频相关的算法简称,所以特地来做一个名词解释合集,以免以后大家再花时间搜索
payloadType
载荷类型,音频最常用的是PCM,其他还有如G711U、G711A
sample rate
采样率(也称为采样速度或者采样频率)定义了每秒从连续信号中提取并组成离散信号的采样个数,单位用赫兹(Hz)来表示。
采样频率的倒数是采样周期(也称为采样时间),它表示采样之间的时间间隔。这里要注意不要将采样率与位速相混淆。
gain
输入或输出信号增益
bitwidth
采样位深
我们常见的16Bit(16比特),可以记录大概96分贝的动态范围。那么,您可以大概知道,每一个比特大约可以记录6分贝的声音。同理,20Bit可记录的动态范围大概就是120dB;24Bit就大概是144dB。假如,我们定义0dB为峰值,那么声音振幅以向下延伸计算,那么,CD音频可的动态范围就是“-96dB~0dB。”,依次类推,24Bit的HD-Audio高清音频的的动态范围就是“-144dB~0dB。”。由此可见,位深度较高时,有更大的动态范围可利用,可以记录更低电平的细节。
AEC(Auto echo cancellation)
自适应回声消除
AEC算法早期用在Voip,电话这些场景中,自从智能设备诞生后,智能语音设备也要消除自身的音源,这些音源包括音乐或者TTS机器合成声音。回声消除的基本原理是使用一个自适应滤波器对未知的回声信道:ω omegaω 进行参数辨识,根据扬声器信号与产生的多路回声的相关性为基础,建立远端信号模型,模拟回声路径,通过自适应算法调整,使其冲击响应和真实回声路径相逼近。然后将麦克风接收到的信号减去估计值,即可实现回声消除功能
AGC(Automatic Gain Control)
自动增益控制
当有对语音的响度进行调整的需要时,就要做语音自动增益(AGC)算法处理,当你在跟远方的朋友进行语音交流时,背后都有这个算法在默默的工作,如大名鼎鼎的QQ聊天软件、做语音起家的YY等,语音聊天时都会用到这个算法。
最简单的硬性增益处理是对所有音频采样乘上一个增益因子,它也等同于在频域每个频率都同时乘上这个增益因子,但由于人的听觉对所有频率的感知不是线性的,是遵循等响度曲线的,导致这样处理后,听起来感觉有的频率加强了,有的频率削弱了,导致语言失真的放大。
要让整个频段的频率听起来响度增益都是“相同”的,就必须在响度这个尺度下做增益,而不是在频率域,即按照等响度曲线对语音的频率进行加权,不能采用一个固定的增益因子进行加权。
由些可见,语音的自动增益处理可以大致分为两个部分:(1)响度增益因子的确定。(2)把响度增益因子映射到等响度曲线上,确定最终各频率的增益权重。
最后要做的就是把各频率乘上最终的增益权重,我们就可以得到最终增益后的语音了!这里再说下如何获取等响度曲线的值,总体思路是可以利用数值分析中的逼近理论做插值和拟合
NS(Noise suppression)
噪声抑制(降噪)
各种滤波操作
有很多开源的NS可供使用,如webrtc
HPF(High Pass Filter)
高通滤波
音响系统中,有时会有一些极低频的次声波(infrasonic)信号夹杂在全音频信号当中,这些次声波信号人耳听不见,但是这种信号进入音箱,就会导致低音喇叭产生自激,并导致喇叭损坏
所有,有些功放内部装有次声波消除滤波器,有些是在后面板设置开关,可以在需要的时候切除无必要的30赫兹或40赫兹以下的频率,保护喇叭的安全。
BSS(Blind Source Separation)
盲源分离
又称为盲信号分离,是指在信号的理论模型和源信号无法精确获知的情况下,如何从混迭信号(观测信号)中分离出各源信号的过程。盲源分离和盲辨识是盲信号处理的两大类型。盲源分离的目的是求得源信号的最佳估计,盲辨识的目的是求得传输通道的混合矩阵。盲源信号分离是一种功能强大的信号处理方法,在生物医学信号处理,阵列信号处理,语音信号识别,图像处理及移动通信等领域得到了广泛的应用。
BF(Beamforming)
波束形成
波束成形是天线技术与数字信号处理技术的结合,目的用于定向信号传输或接收。 波束成形,并非新名词,其实它是一项经典的传统天线技术。早在上世纪60年代就有采用天线分集接收的阵列信号处理技术,在电子对抗、相控阵雷达、声纳等通信设备中得到了高度重视。基于数字波束形成(DBF)的自适应阵列干扰置零技术,能够提高雷达系统的抗干扰能力,是新一代军用雷达必用的关键技术。定位通信系统通过传声器阵列获取声场信息,使用波束成形和功率谱估计原理,对信号进行处理,确定信号来波方向,从而可对信源进行精确定向。只不过,由于早年半导体技术还处在微米级,所以它没有在民用通信中发挥到理想的状态。
DOA(Direction of arrival)SD(sound localization)
声源定位
现在常见的麦克风声源定位算法多见于TDOA算法,其基本原理是根据信号到达两个不同位置的麦克风的时间差,估计出信号到达两个不同位置麦克风的距离差,可以列出一个双曲线方程,同时使用另外两个不同的麦克风同时检测信号可以得到另外一个双曲线方程,两个双曲线方程的交点就是声源的位置坐标。使用这种方法进行声源定位时,至少要使用三个麦克风,使用两次TDOA算法进行运算,才能完成一次定位操作。为了实现更精确的声源定位,也常采用阵列技术,将多个麦克风组成线阵,或方阵采集信号进行声源定位。但这种定位技术的算法更为复杂。
DER(Dereverberation)
去混响
通常在声音信号采集或录制的情况下, 传声器除了接收到所需要的声源发射声波直接到达的部分外,还会接收声源发出的、经过其它途径传递而到达的声波, 以及所在环境其它声源产生的不需要的声波(即背景噪声)。在声学上, 延迟时间达到约 50 ms 以上的反射波称为回声, 其余的反射波产生的效应称为混响。混响现象将对期望声信号的接收效果产生影响。一些建筑, 如音乐厅和教堂, 需要适度的混响作用而使音乐更加动听。但在许多场合, 混响往往会带来干扰, 导致声学接收系统性能变差。例如, 混响会导致语音识别系统性能显著下降; 在远程会议、免提电话、助听器和移动通信中, 混响作用主要带来负面影响。当混响严重时,这些系统甚至无法正常发挥功能, 因此, 如何减少混响对声音接收系统的影响, 即去混响(dereverberation),是一个非常重要的课题。
最后
以上就是傻傻火最近收集整理的关于音频处理——常用音频算法名词简称解释(AEC、AGC、NS、HPF、BSS、BF、DOA、DER)前言payloadTypesample rategainbitwidthAEC(Auto echo cancellation)AGC(Automatic Gain Control)NS(Noise suppression)HPF(High Pass Filter)BSS(Blind Source Separation)BF(Beamforming)DOA(Direction of arrival)\的全部内容,更多相关音频处理——常用音频算法名词简称解释(AEC、AGC、NS、HPF、BSS、BF、DOA、DER)前言payloadTypesample内容请搜索靠谱客的其他文章。








发表评论 取消回复