目录
1、声学背景知识
2、音频技术背景
2.1、音频基础概念
2.2、音频SDK架构
3、音频采集
4、音频处理
4.1、自动增益(AGC)
4.2、编解码
4.2.1、5W+1H
4.2.2、speex
4.2.3、opus
5、TRTC的音频能力探索
5.1、TRTC的音频处理能力
5.2、TRTC无声音问题踩坑
1、声学背景知识
声音作为机械波的一种,频率和振幅是描述波的重要属性,频率的大小与我们通常所说的音高对应,而振幅影响声音的大小(音量)。声音可以被分解为不同频率不同强度正弦波的叠加,这个变换的过程就是傅立叶变换。声音总是包含一定的频率范围,人耳可以听到的声音的频率范围在20到2万赫兹之间。高于这个范围的波动是超声波,而低于这一范围的是次声波。
声波在遇到障碍物时,一部分声波会穿过障碍物,而另一部分声波会反射回来形成回声。回声相比那些直接传播的声音所经过的路程更长,所以会比直接传播的声音晚被听到。如果两列声波的时间间隔小于0.1秒,人耳边无法分辨,只能听到被延长的声音。因为室温(20℃)时空气中的声速是343米每秒,所以站在声源处的人要听到回声需要障碍物到声源的距离至少17米。
2、音频技术背景
2.1、音频基础概念
采样:
声波是无限光滑的,弦线其实由无数点组成,由于存储空间是相对有限的,数字编码过程中,必须对弦线的点进行采样,采样的过程就是抽取某点的频率值,光有频率信息是不够的,我们还必须获得该频率的能量值并量化,用于表示信号强度,总体音量得到明显的提升。
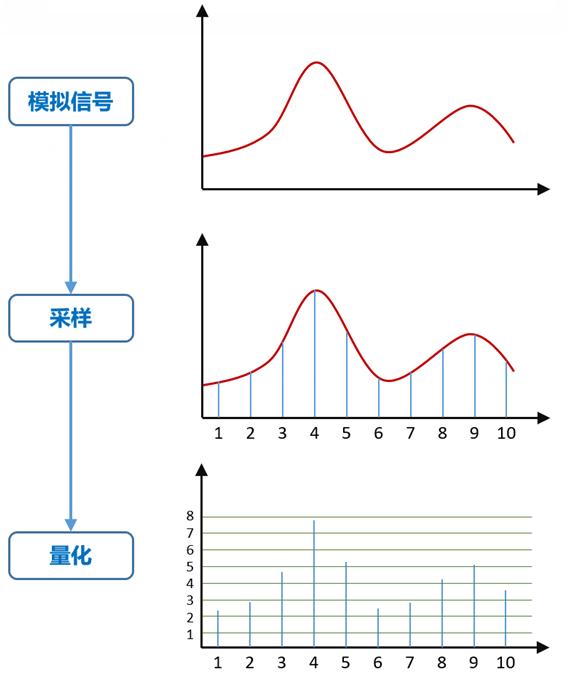
采样频率:
单位时间内对模拟信号的采样次数。奈奎斯特采样定理,要从抽样信号中无失真地恢复原信号,抽样频率应大于2倍信号最高频率。 抽样频率小于2倍频谱最高频率时,信号的频谱有混叠。 抽样频率大于2倍频谱最高频率时,信号的频谱无混叠。人耳能够感觉到的最高频率为20kHz,因此要满足人耳的听觉要求,则需要至少每秒进行40k次采样,用40kHz表达,这个40kHz就是采样率。我们常见的CD,采样率为44.1kHz。
采样位数:
每个采样点能够表示的数据范围。采样位数可以理解为采集卡处理声音的解析度。这个数值越大,解析度就越高,录制和回放的声音就越真实。录音的本质就是把模拟声音信号转换成数字信号;反之,在播放时则是把数字信号还原成模拟声音信号输出。采集卡的位是指采集卡在采集和 播放声音文件时所使用数字声音信号的二进制位数。采集卡的位客观地反映了数字声音信号对输入声音信号描述的准确程度。8位代表2的8次方--256,16 位则代表2的16次方--64K。一段相同的音频,16位声卡能把它分为64K个精度单位进行处理,而8位声卡只能处理256个精度单位, 有一定程度的信号损失。
声道:
声道(Sound Channel) 是指声音在录制或播放时在不同空间位置采集或回放的相互独立的音频信号,所以声道数也就是声音录制时的音源数量或回放时相应的扬声器数量。单声道,声音的采集/播放只有一路信号(可以理解为只有一个麦克风/扬声器)。双声道(立体声),声音在录制过程中被分配到两个独立的声道,从而达到了很好的声音定位效果。单声道缺乏对声音的位置定位,而立体声技术则彻底改变了这一状况。四声道环绕,有前左、前右,后左、后右,听众则被包围在这中间,同时还建议增加一个低音音箱,以加强对低频信号的回放处理,四声道系统可以带来来自多个不同方向的声音环绕。5.1声道,5.1声音系统来源于4.1环绕,不同之处在于它增加了一个中置单元,这个中置单元是一个专门设计的超低音声道,这一声道可以产生频响范围20~120Hz的超低音,把对话集中在整个声场的中部。7.1声道,7.1系统在5.1的基础上又增加了中左和中右两个发音点,建立起一套前后声场相对平衡的声场。
编码:
采样和量化后的信号还不是数字信号,需要将它转化为数字编码脉冲,这一过程称为编码。模拟音频进采样、量化和编码后形成的二进制序列就是数字音频信号。
音频帧:
音频数据是流式的,本身没有明确的一帧帧的概念,在实际的应用中为了处理方便,一般约定俗成取2.5ms~60ms为单位的数据量为一帧音频,长度没有特别的标准,它是根据编解码器和具体应用的需求决定。
音频码率:
一个音频流中每秒钟能通过的数据量。如128kbps,其中ps(per second)为每秒,kb为千位,那么128kbps表示一秒钟能传输的数据量是128千位。对于格式相同的文件来说,码率越大的话,音质越好。但是对于不同格式的音频文件来说,相同码率并不代表其音质一样。音频的码率=采样率*位深度*通道数。
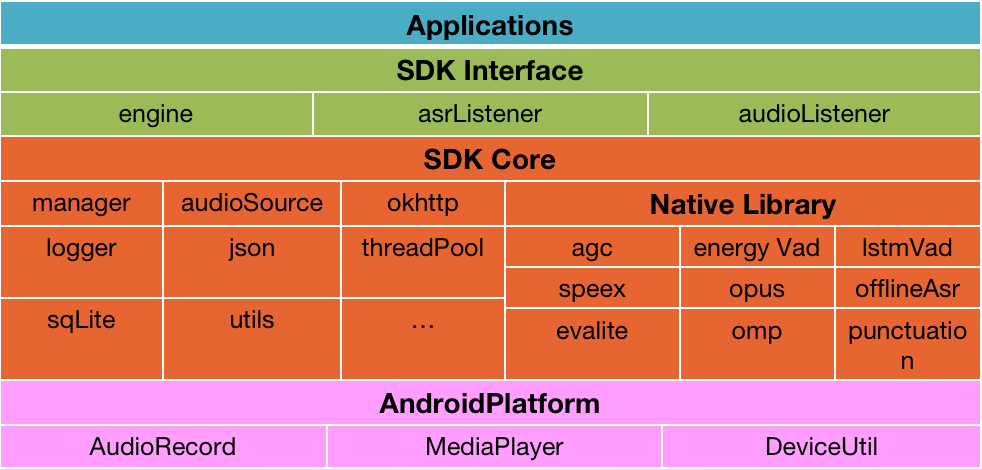
2.2、音频SDK架构
主流的音频SDK通常包括音频采集、音频处理(AGC、AEC、VAD、ANS)、编解码、缓存、网络传输、音频播放等部分,其中音频处理部分涉及到矩阵运算,某些厂商还会用到openMP做算法加速。
3、音频采集
音频采集以及麦克占用检测方案参见:Android麦克风探测器_喜六六的博客-CSDN博客
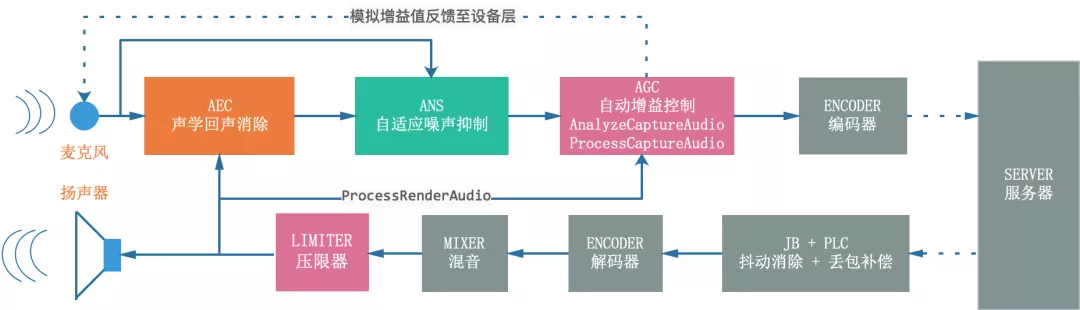
4、音频处理
音频处理链路包括AEC回声消除、AGC音量的自动增益控制、VAD音频的活性检测、编码/解码(speex、opus)、ANS降噪,具体处理流程如下所示:
4.1、自动增益(AGC)
作用:
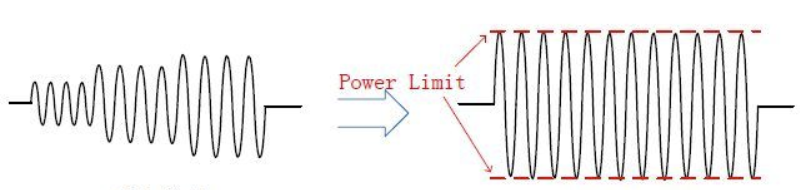
在音视频通话的现实场景中,不同的参会人说话音量各有不同,参会用户需要频繁的调整播放音量来满足听感的需要,戴耳机的用户随时承受着大音量对耳朵的 “暴击”。自动增益控制算法能够统一音频音量大小,极大地缓解了由设备采集差异、说话人音量大小、距离远近等因素导致的音量的差异。
因此,自动增益控制的主要作用是,当功放的输入信号幅度变化很大的情况下,使输出信号幅度保持恒定。当输入信号达到一定强度时,启动压缩功能,减小放大增益,使得输出幅度降低;当输入信号降低到一定程度时,再逐渐恢复默认的放大增益。AGC能够保证输入信号的幅度在不断变化,但是输出信号的幅度是固定的,也就是说输出功率是固定的。
AGC的核心参数包括:
public class AgcParam {
public int targetLevelDbfs;//目标音量
public int compressionGaindB;//增益能力
public int limiterEnable;//压限器
}目标音量(targetLevelDbfs) :表示音量均衡结果的目标值
增益能力(compressionGaindB):表示音频最大的增益能力,如设置为 80dB,最大可以被提升到80dB;
压限器(limiterEnable):与目标音量配合使用,增益能力是调节小音量的增益范围,压限器则是对超过目标音量的部分进行限制,避免数据爆音。
经常使用的三种AGC增益模式包括:
public enum AgcMode {
kAgcModeAdaptiveAnalog, // 自适应模拟模式
kAgcModeAdaptiveDigital, // 自适应数字增益模式
kAgcModeFixedDigital // 固定数字增益模式
}固定数字增益模式(FixedDigital):主要是对信号进行固定增益的放大,最大增益不超过设置的增益能力 compressionGaindB,结合 limiter 使用的时候上限不超过设置的目标音量 targetLevelDbfs
固定数字增益由于没有信号反馈机制,会存在如下问题:
1、采集音量较小时,均衡后改善不明显
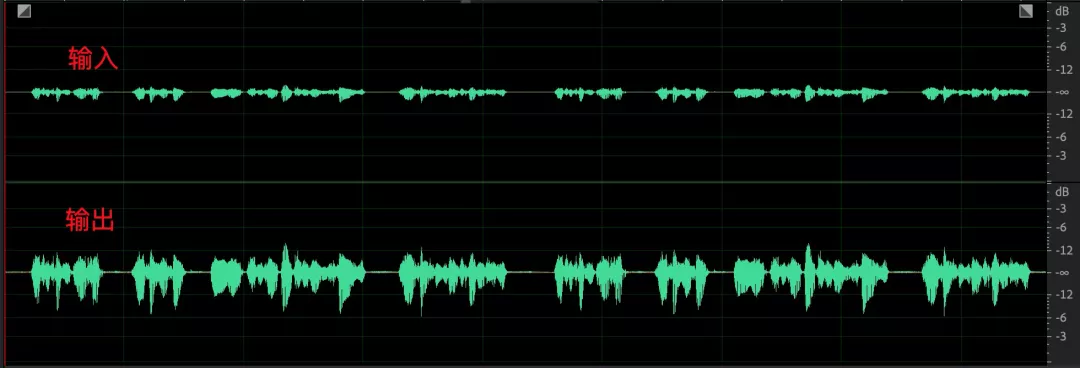
2、采集音量较大,底噪明显增强
采集音量较大时如果环境噪声较大,且降噪能力一般的话,一旦 compressionGaindB 设置较大,那么语音部分会被限制在 targetLevelDbfs,在没有对话的语音段底噪会得到全量的提升,增益后可以听到明显的噪声。
自适应模拟增益(AdaptiveAnalog):在固定数字增益的基础上新增了模拟增益更新模块,该模块会根据当前模拟增益值 inMicLevel(WebRTC 中将尺度映射到 0~255)参数,计算下一次需要调节的模拟增益值 outMicLevel,并反馈给设备层,通过反馈机制来调节原始采集音量。
出现背景:
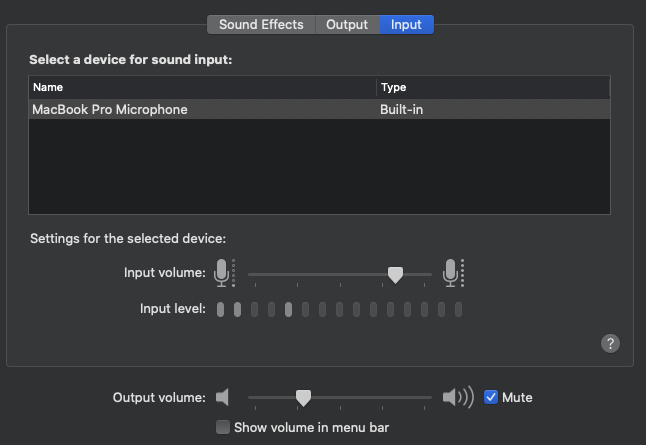
1、绝大部分的PC端支持调节采集音量,调节范围WebRTC 客户端代码内部映射到了 0~255,如下是Mac中调节采集音量:
2、绝大多数 windows 笔记本设备内置了麦克风阵列,并提供麦克风阵列增强算法,降噪的同时还会额外提供 0~10dB 的增益。
3、绝大多数用户在察觉到声音异常后并不知道 PC 设备还具备手动调节采集增益的功能,依赖于线上用户自己去调节模拟增益值几乎不可能。自适应模拟增益模式,通过反馈机制来调节原始采集音量,目标就是与数字增益模块相互配合,找到最合适的麦克风增益值并反馈给设备层,使得近端数据再经过数字增益之后达到目标增益。
存在的问题:
1、频繁调整操作系统 API,带来不必要的性能消耗
2、爆音检测不是很敏感,不能及时下调模拟增益
自适应数字增益(AdaptiveDigital):为移动端设备设计,移动设备并不具备PC机的音量输入调节能力,声源与设备的距离,声源音量以及硬件采集能力等因素都会影响采集音量,单纯依赖固定数字增益效果十分有限。该算法仿照 PC 端模拟增益调节的能力,设计了增益曲线 - kGainTableVirtualMic 和抑制曲线 - kSuppressionTableVirtualMic来模拟 PC 端模拟增益,增益曲线提供 1.0~3.0 倍的增益能力,抑制曲线提供 1.0~0.1 的抑制能力。
存在的问题:
数字增益自适应调节灵敏度不高,当输入音量起伏时容易出现音频帧拉升或压缩,比如遇到大音量时需要调用压缩曲线,如果后面紧跟较小音量,会导致小音量进一步压缩,接着会调大增益,此时小音量后续如果接着跟大音量,会导致大音量爆音。
4.2、编解码
speex和opus编码demo:
https://github.com/xiyy/androidSpeechEncode
opus编码Android插件:
https://github.com/xiyy/androidOpusEncode
4.2.1、5W+1H
编解码是什么意思?
原始音频脉冲数据(pcm)是无损的音频数据,最接近于原声,asr时如果声学模型以及语言模型训练数据足够充分的话,理论上asr准确率可以达到100%。但工程应用背景下考虑到带宽负担以及存储成本,必须将原始音频编码压缩后才能用于网络传输。并且pcm传输的话延迟会非常大,试想采样率为44.1khz,采样精度为16bit,双声道采样的话传输码率为v =44.1K * 16 *2 = 1411.2 Kbps = 176.4KBps,即每秒传输速率大概176.4KB,只要稍微信号不好,就会导致丢包率特别高,而且延时十分大,根本无法满足通信的需要。音频压缩后再传输同样的码率可以传输更多的音频数据,实时性会大大提高。压缩后的音频数据必须解码后才能进行播放或进行计算,解码后得到的音频肯定会有损失,我们应该做的就是保证满足带宽要求的情况下尽可能的将音频失真度降到最低。
音频为什么要编码?
音频编码主要是为了降低流量消耗,降低带宽负担,同时音视频场景可以为视频腾出更多带宽空间。
音频如何编码?
语音经典的编码模型依赖心理声学模型进行编码,其中的重要原理包括:
人耳的遮蔽效应 - The Masking effect
遮蔽效应表现在强信号会遮蔽邻近频率的弱信号。用生活经验来说,在安静的房间中,一根针掉到地上都能听见,可到了大街上,就算手机音量调到最大,来电时也未必能听见,而手机的声音确确实实是存在的,原因就是被周围更大的声音遮蔽了。有了对遮蔽效应的研究成果,编码器就能根据已建立的数学模型,计算强信号对附近弱信号的遮蔽,把能引起人们注意的声音才保留。人耳还有前遮蔽效应和后遮蔽效应:因为人需要一定的时间来处理声音信号,在强信号之前或之后的弱信号,会被遮蔽掉。前遮蔽效应的时间约只有2-5ms,而后遮蔽的时间比较长,大约有100ms,利用这一原理我们能减小强信号之前和之后的分辨率。
最小听觉门槛判定 - The minimal audition threshold
人耳的听力范围是20Hz-20kHz的频率范围,但是人耳对不同的频率声音的灵敏度是不同的,不同频率的声音要达到能被人耳听到的水平所需要的强度是不一样。人耳对音频的某个频率的灵敏度不同,二者关系是非线性的,通常我们将人耳主要听到的整个频率也就是从20Hz到16KHz分为24个频带,可在其中进行时域或频域类的掩蔽,将一些冗余信息从编码中去除从而有效提升压缩率。
动态比特率编码&固定比特率编码 - VBR&CBR
一般来说,声音片段的音调越高,就需要更多的空间去存储,比特率就越高。传统的mp3文件是CBR编码的,也就是每一帧的比特率都是相同的,这样就带来了一个问题:如果每一帧的比特率是相同的,那么每一帧的数据大小都是一样的,无论这一帧的音调是高还是低,都是使用整段音频中音调比较高的音频帧的存储空间的大小来存储这一帧,但是对于音调低的音频帧,其实并不需要这么大的存储空间。这样就会造成存储空间的浪费,无形中增大了mp3文件的大小。
VBR编码技术的出现,就是为了解决这个空间浪费的问题。VBR技术对每个音频帧选择最适合这一帧的比特率,对于音调比较低的音频帧,比特率会比较低,数据大小就比较小,音调比较高的则比特率就会比较高,数据大小就比较大。这样就能在不损失音频质量的前提下,节省音频数据的存储空间,进一步压缩mp3的文件大小。
4.2.2、speex
Speex可以压缩码率在2-44kb/s的原始语音数据,speex拥有如下特性:
1、具备语音活性检测能力(vad)
2、具备回声消除能力
3、比特率2kbps到44kpbs
4、只支持窄带(8kHz)、宽带(16kHz)和超宽带(32kHz)三种采样率
speex编码解码jni接口如下:
extern "C"
JNIEXPORT jint JNICALL Java_com_speex_util_SpeexUtil_open
(JNIEnv *env, jobject obj, jint compression) {
int tmp;
if (codec_open++ != 0)
return (jint)0;
speex_bits_init(&ebits);
speex_bits_init(&dbits);
enc_state = speex_encoder_init(&speex_nb_mode);
dec_state = speex_decoder_init(&speex_nb_mode);
tmp = compression;
speex_encoder_ctl(enc_state, SPEEX_SET_QUALITY, &tmp);
speex_encoder_ctl(enc_state, SPEEX_GET_FRAME_SIZE, &enc_frame_size);
speex_decoder_ctl(dec_state, SPEEX_GET_FRAME_SIZE, &dec_frame_size);
return (jint)0;
}
extern "C"
JNIEXPORT jint JNICALL Java_com_speex_util_SpeexUtil_encode
(JNIEnv *env, jobject obj, jshortArray lin, jint offset, jbyteArray encoded, jint size) {
jshort buffer[enc_frame_size];
jbyte output_buffer[enc_frame_size];
int nsamples = (size-1)/enc_frame_size + 1;
int i, tot_bytes = 0;
if (!codec_open)
return 0;
speex_bits_reset(&ebits);
for (i = 0; i < nsamples; i++) {
env->GetShortArrayRegion(lin, offset + i*enc_frame_size, enc_frame_size, buffer);
speex_encode_int(enc_state, buffer, &ebits);
}
tot_bytes = speex_bits_write(&ebits, (char *)output_buffer,
enc_frame_size);
env->SetByteArrayRegion(encoded, 0, tot_bytes,
output_buffer);
return (jint)tot_bytes;
}
extern "C"
JNIEXPORT jint JNICALL Java_com_speex_util_SpeexUtil_decode
(JNIEnv *env, jobject obj, jbyteArray encoded, jshortArray lin, jint size) {
jbyte buffer[dec_frame_size];
jshort output_buffer[dec_frame_size];
jsize encoded_length = size;
if (!codec_open)
return 0;
env->GetByteArrayRegion(encoded, 0, encoded_length, buffer);
speex_bits_read_from(&dbits, (char *)buffer, encoded_length);
speex_decode_int(dec_state, &dbits, output_buffer);
env->SetShortArrayRegion(lin, 0, dec_frame_size,
output_buffer);
return (jint)dec_frame_size;
}
extern "C"
JNIEXPORT jint JNICALL Java_com_speex_util_SpeexUtil_getFrameSize
(JNIEnv *env, jobject obj) {
if (!codec_open)
return 0;
return (jint)enc_frame_size;
}
extern "C"
JNIEXPORT void JNICALL Java_com_speex_util_SpeexUtil_close
(JNIEnv *env, jobject obj) {
if (--codec_open != 0)
return;
speex_bits_destroy(&ebits);
speex_bits_destroy(&dbits);
speex_decoder_destroy(dec_state);
speex_encoder_destroy(enc_state);
}采样率8khz,采样位数16bit,声道为单声道时,码率 V = 8K * 16 * 1 = 128Kbps = 16KBps,即每秒传输速率大概16KB,若音频帧时间为20ms,每帧音频数据大小为 size = 16KB * 0.02s = 320Byte。设置压缩质量为4,每帧音频数据压缩完后只有20Byte,压缩比为 320:20,即 16:1,每秒发送1/0.02=50个数据包,音频数据占用的带宽仅为 1 KB/s。
4.2.3、opus
Opus可以压缩码率在6 kb /s到510 kb / s的原始语音数据,并且Opus编码方案相较于speex编码在以下方面有了提升:
1、码率范围6kbps到510kbps,较speex的码率2-44kb/s有提升。
2、支持的音频的采样率从8 kHz (narrowband) 到 48 kHz (fullband),覆盖了低频段到高频段的全带音频,相较于speex只支持窄带(8kHz)、宽带(16kHz)和超宽带(32kHz)三种采样率,适用的音频采样率范围更广。
3、支持的音频帧范围从2.5ms到60ms,音频帧越小实时性越高,延迟就越低,Opus最低帧规格2.5ms,speex最小音频帧为20ms,因此从最新音频帧方面考虑,opus更适合实时音视频场景。
4、支持动态码率(VBR)和恒定码率(CBR)两种编码格式
5、opus可动态调整码率、音频带宽、以及音频帧大小。
编码器性能如下图所示:
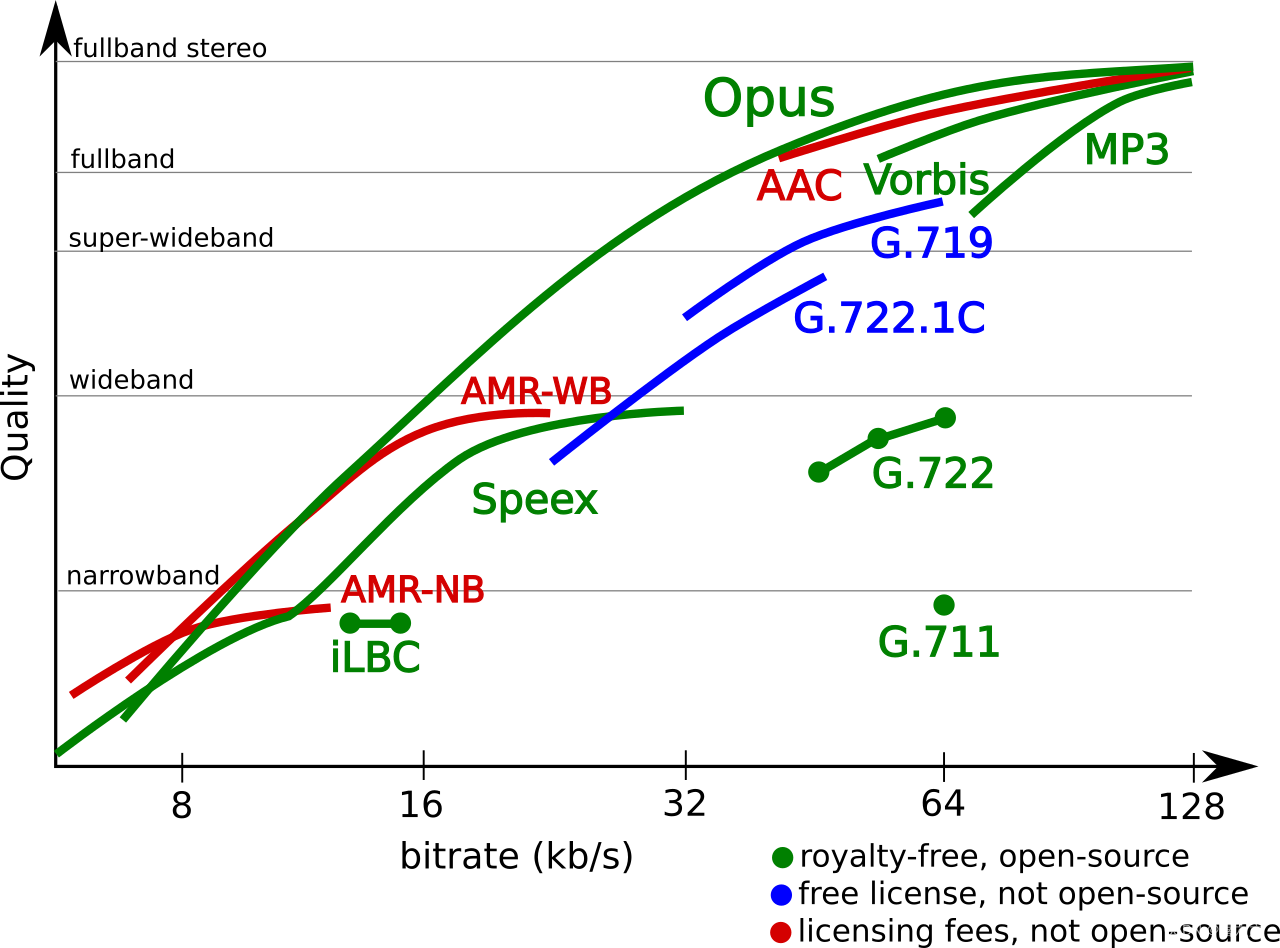
编码质量测试-Google测试:
Google测试1:
测试形式:训练和未训练的17名测试者,主观打分;MUSHRA-type tests(MUltiple Stimuli with Hidden Reference and Anchor)
测试结果:http://www.opus-codec.org/comparison/GoogleTest1.pdf
测试结论总结:
窄带单声道语音:Opus(11kbps)比iLBC(15kbps)和Speex(11kbps)好
宽带单声道语音:Opus(20kbps)好于G.722.1(24kbps)、Speex WB(24kbps)
全带单声道语音:Opus(32kbps)好于G.719(32kbps)
Google测试2:
测试结果:http://www.opus-codec.org/comparison/GoogleTest2.pdf
测试结论总结:
窄带单声道语音:Opus(11kbps)可以和iLBC(15kbps)相比,比Speex(11kbps)好
宽带单声道语音:Opus(20kbps)好于G.722.1(24kbps)、Speex WB(24kbps)
全带单声道语音:Opus(32kbps)好于G.719(32kbps)
opus编解码jni接口如下:
JNIEXPORT jlong JNICALL Java_com_speech_opus_OpusUtil_createEncoder
(JNIEnv *env, jobject thiz, jint sampleRateInHz, jint channelConfig, jint complexity) {
int error;
OpusEncoder *pOpusEnc = opus_encoder_create(sampleRateInHz, channelConfig,
OPUS_APPLICATION_VOIP,
&error);
if (pOpusEnc) {
opus_encoder_ctl(pOpusEnc, OPUS_SET_BITRATE(25000));
//opus_encoder_ctl(pOpusEnc, OPUS_SET_VBR_CONSTRAINT(true));
opus_encoder_ctl(pOpusEnc, OPUS_SET_SIGNAL(OPUS_SIGNAL_VOICE));
opus_encoder_ctl(pOpusEnc, OPUS_SET_VBR(1));//0:CBR, 1:VBR
opus_encoder_ctl(pOpusEnc, OPUS_SET_COMPLEXITY(complexity));//6 0~10
//opus_encoder_ctl(pOpusEnc, OPUS_SET_LSB_DEPTH(16));
//opus_encoder_ctl(pOpusEnc, OPUS_SET_DTX(0));
//opus_encoder_ctl(pOpusEnc, OPUS_SET_INBAND_FEC(0));
//opus_encoder_ctl(pOpusEnc, OPUS_SET_PACKET_LOSS_PERC(0));
}
return (jlong) pOpusEnc;
}
JNIEXPORT jlong JNICALL Java_com_speech_opus_OpusUtil_createDecoder
(JNIEnv *env, jobject thiz, jint sampleRateInHz, jint channelConfig) {
int error;
OpusDecoder *pOpusDec = opus_decoder_create(sampleRateInHz, channelConfig, &error);
return (jlong) pOpusDec;
}
JNIEXPORT jint JNICALL Java_com_speech_opus_OpusUtil_encode
(JNIEnv *env, jobject thiz, jlong pOpusEnc, jshortArray samples, jint offset,
jbyteArray bytes) {
OpusEncoder *pEnc = (OpusEncoder *) pOpusEnc;
if (!pEnc || !samples || !bytes)
return 0;
jshort *pSamples = env->GetShortArrayElements(samples, 0);
jsize nSampleSize = env->GetArrayLength(samples);
jbyte *pBytes = env->GetByteArrayElements(bytes, 0);
jsize nByteSize = env->GetArrayLength(bytes);
if (nSampleSize - offset < 320 || nByteSize <= 0)
return 0;
int nRet = opus_encode(pEnc, pSamples + offset, nSampleSize, (unsigned char *) pBytes,
nByteSize);
env->ReleaseShortArrayElements(samples, pSamples, 0);
env->ReleaseByteArrayElements(bytes, pBytes, 0);
return nRet;
}
JNIEXPORT jint JNICALL Java_com_speech_opus_OpusUtil_decode
(JNIEnv *env, jobject thiz, jlong pOpusDec, jbyteArray bytes,
jshortArray samples) {
OpusDecoder *pDec = (OpusDecoder *) pOpusDec;
if (!pDec || !samples || !bytes)
return 0;
jshort *pSamples = env->GetShortArrayElements(samples, 0);
jbyte *pBytes = env->GetByteArrayElements(bytes, 0);
jsize nByteSize = env->GetArrayLength(bytes);
jsize nShortSize = env->GetArrayLength(samples);
if (nByteSize <= 0 || nShortSize <= 0) {
return -1;
}
int nRet = opus_decode(pDec, (unsigned char *) pBytes, nByteSize, pSamples, nShortSize, 0);
env->ReleaseShortArrayElements(samples, pSamples, 0);
env->ReleaseByteArrayElements(bytes, pBytes, 0);
return nRet;
}
JNIEXPORT void JNICALL Java_com_speech_opus_OpusUtil_destroyEncoder
(JNIEnv *env, jobject thiz, jlong pOpusEnc) {
OpusEncoder *pEnc = (OpusEncoder *) pOpusEnc;
if (!pEnc)
return;
opus_encoder_destroy(pEnc);
}
JNIEXPORT void JNICALL Java_com_speech_opus_OpusUtil_destroyDecoder
(JNIEnv *env, jobject thiz, jlong pOpusDec) {
OpusDecoder *pDec = (OpusDecoder *) pOpusDec;
if (!pDec)
return;
opus_decoder_destroy(pDec);
}5、TRTC的音频能力探索
5.1、TRTC的音频处理能力
TRTC提供了AGC、AEC、ANS能力。上述能力在TRTC中一直是“实验版”特性,通过JSON配置项即可开启,比如AGC开启如下:
public static String generateAGC(boolean enable) {
JSONObject jsonObject = new JSONObject();
try {
jsonObject.put("api", "enableAudioAGC");
JSONObject params = new JSONObject();
params.put("enable", enable ? 1 : 0);
jsonObject.put("params", params);
return jsonObject.toString();
} catch (JSONException e) {
e.printStackTrace();
}
return "";
}5.2、TRTC无声音问题踩坑
1、部分主播佩戴蓝牙耳机未采集到有效音频
背景:
通过数据统计及抽检,直播间每日无声率(无声音的时长/直播总时长)在10%以上的直播场次占比约16%,其中一部分原因是主播没有说话,一部分原因是麦克风设备未采集到有效音频导致,另一部分原因是主播误触了“静音”按钮而主播并不知道自己点击了“静音”。
原因:
针对麦克风未采集到有效声音的问题,通过监控仪表盘发现没有上行的音频流,进一步查询埋点数据+日志回捞排查具体case发现TRTC回调回来的音量都是0,相同型号的设备在未佩戴蓝牙耳机时可以正常录音,咨询TRTC方面给到的答复是:“3A模块检测到采集音量过低”,然而根据我们的埋点发现不是过低,而是压根没有采集到有效音频。市面上蓝牙耳机众多,厂商鱼龙混杂,通过蓝牙耳机采集音频存在以下问题:
1、蓝牙耳机内置的麦克风阵列拾音品质没有保障。
2、采集到的音频数据需要通过蓝牙链路sco传输,链路的稳定性受电量、距离影响。
方案:1、反馈给TRTC完善音频蓝牙采集方案。2、通过TRTC回调的音量数据给主播UI上面的提示,引导主播做出相应的动作。包括:1、主播没有说话,提示主播说话 2、主播说话音量小,提示主播大声说话 3、主播静音后还说话(误触“静音”)提示主播打开麦克风 4、主播音量为0说明没有采集到有效音频,提示主播换个耳机。
2、麦克风占用导致采集不到有效音频
原因以及方案:查询埋点数据发现TRTC爆出 warning-1204,原因是麦克被占用,此错误码中台应该回调通知到业务方,业务方给与UI提示。
最后
以上就是任性哈密瓜最近收集整理的关于音频技术总结1、声学背景知识2、音频技术背景3、音频采集4、音频处理5、TRTC的音频能力探索的全部内容,更多相关音频技术总结1、声学背景知识2、音频技术背景3、音频采集4、音频处理5、TRTC内容请搜索靠谱客的其他文章。








发表评论 取消回复