操作系统(三):父子进程(下)
一、杂七杂八的知识点
1.struct pid
每个进程控制块都有4个有关ID、含义不同的值,内核根据它们组成了4个全局的2维的HASH表,每个进程都要链接到这四个不同含义的Hash表当中。
/* 4种类型的值*/
enum pid_type
{
PIDTYPE_PID, 进程的PID
PIDTYPE_TGID, 线程组ID
PIDTYPE_PGID, 进程组ID
PIDTYPE_SID, 会话ID
PIDTYPE_MAX
};
struct task_struct {
…
/* PID/PID hash table linkage. */
struct pid pids[PIDTYPE_MAX];
…
}
2.find_vpid()
struct pid *find_vpid(int nr) 用于根据nr也就是namespace下的局部pid找到对应的struct pid结构体
参考链接:https://blog.csdn.net/tiantao2012/article/details/78641893
3.pid_task( )
task->comm //这个进程的指令信息,比如如果是bash中的进程,则comm内容 为bash
task->pid //显示任务的进程号
task->state //显示任务当前所处的状态,0:可运行状态;-1:不可运行状态;>0:停止运行状态
参考链接:https://blog.csdn.net/cnbird2008/article/details/11560109
4.sscanf()
比如
char weekday[20], month[20], dtm[100];
int day, year;
strcpy( dtm, "Saturday March 25 1989" );
sscanf( dtm, "%s %s %d %d", weekday, month, &day, &year );
# 把dtm数组中的元素存入后面的参数。
4.copy_to_user()和copy_from_user()
(1)Copy_to_user( to, &from, sizeof(from))
To:用户空间函数 (可以是数组)
From:内核空间函数(可以是数组)
sizeof(from):内核空间要传递的数组的长度
(2)Copy_from_user(&from , to , sizeof(to) )
To:用户空间函数 (可以是数组)
From:内核空间函数(可以是数组)
sizeof(from):内核空间要传递的数组的长度
成功返回0,
失败返回失败数目。
二、作业1
(一)题目
Project 2 —Linux Kernel Module for Task Information
In this project, you will write a Linux kernel module that uses the /proc file system for displaying a task’s information based on its process identifier value pid. Before beginning this project, be sure you have completed the Linux kernel module programming project in Chapter 2, which involves creating an entry in the /proc file system. This project will involvewriting a process identifier to the file /proc/pid. Once a pid has been written to the /proc file, subsequent reads from /proc/pid will report (1) the command the task is running, (2) the value of the task’s pid, and (3) the current state of the task. An example of how your kernel module will be accessed once loaded into the system is as follows:
echo “1395” > /proc/pid
cat /proc/pid
command = [bash] pid = [1395] state = [1]
The echo command writes the characters “1395” to the /proc/pid file. Your kernel module will read this value and store its integer equivalent as it represents a process identifier. The cat command reads from /proc/pid, where your kernel module will retrieve the three fields from the task struct associated with the task whose pid value is 1395.
大致翻译:你需要写一个内核模块,该内核模块用于在/proc文件中创建一个pid文件,当你往该pid文件写入的时候触发proc_write,将该数字表示的PID对应的进程的信息放到内核内存中,当使用cat触发proc_read函数的时候,读取该进程的信息。
知识点:/proc文件,proc_write()函数的设计,kmalloc/kfree的调用,pid_task和find_vpid等与PID有关的库函数。数据结构task_struct的成员读取等。
(二)开始做题~
思路:向/proc文件里写入数据。即多加了 proc_write() 的实现,proc_read() 的实现和上次相似,只是要增加对pid的处理模块而已。
(1)proc_w.c(注:这个是程序名称,而进程proc的名称为pid)
/**
* Kernel module that communicates with /proc file system.
*
* This provides the base logic for Project 2 - displaying task information
*/
#include <linux/init.h>
#include <linux/slab.h>
#include <linux/init.h>
#include <linux/sched.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/proc_fs.h>
#include <linux/vmalloc.h>
#include <asm/uaccess.h>
#define BUFFER_SIZE 128
#define PROC_NAME "pid" //进程名称为pid
/* the current pid */
static long l_pid;
/**
* Function prototypes
*/
static ssize_t proc_read(struct file *file, char *buf, size_t count, loff_t *pos);
static ssize_t proc_write(struct file *file, const char __user *usr_buf, size_t count, loff_t *pos);
static struct file_operations proc_ops = {
.owner = THIS_MODULE,
.read = proc_read,
.write = proc_write, //增加一个.write属性,告诉系统我们是能接受数据写入的
};
/*要记得proc_init始终返回0,proc_exit没有返回值。*/
/*Begin call this function when the module loaded*/
int proc_init(void)
{
proc_create(PROC_NAME,0666,NULL,&proc_ops); /*创建一个proc*/
printk(KERN_INFO "The /proc/pid loaded!n");
return 0;
}
void proc_exit(void)
{
remove_proc_entry(PROC_NAME,NULL); /*删除该proc*/
printk(KERN_INFO "The /proc/pid unloaded!n");
}
/**
* This function is called each time the /proc/pid is read.
*
* This function is called repeatedly until it returns 0, so
* there must be logic that ensures it ultimately returns 0
* once it has collected the data that is to go into the
* corresponding /proc file.
*/
static ssize_t proc_read(struct file *file, char __user *usr_buf, size_t count, loff_t *pos)
{
int rv = 0;
char buffer[BUFFER_SIZE];
static int completed = 0;
struct task_struct *tsk = NULL;
if (completed) {
completed = 0;
return 0;
}
/*在proc_read中对写入到l_pid的pid信息进行读取,分析,并最终传回到usr_buf中*/
tsk = pid_task(find_vpid(l_pid), PIDTYPE_PID);
rv = sprintf(buffer,"command = [%s], pid = [%ld], state = [%ld]n",tsk->comm,l_pid,tsk->state);
completed = 1;
// copies the contents of kernel buffer to userspace usr_buf
if (copy_to_user(usr_buf, buffer, rv)) { //传回到usr_buf中
rv = -1;
}
return rv;
}
/**
* This function is called each time we write to the /proc file system.
*/
static ssize_t proc_write(struct file *file, const char __user *usr_buf, size_t count, loff_t *pos)
{
char *k_mem;
/*使用kmalloc从内核中申请一块内存,并把从文件中读到usr_buf的内容拷贝到内核内存中*/
// allocate kernel memory,
k_mem = kmalloc(count, GFP_KERNEL);
/* copies user space usr_buf to kernel buffer */
if (copy_from_user(k_mem, usr_buf, count)) {
printk( KERN_INFO "Error copying from usern");
return -1;
}
/**
* kstrol() will not work because the strings are not guaranteed
* to be null-terminated.
*
* sscanf() must be used instead.
*/
//在这里kstrtol如果直接使用是不起效果的,因为这个字符串不保证以NULL结尾。
//这个时候书上的代码提示我们可以用sscanf来加上这个NULL
char buffer[BUFFER_SIZE];
sscanf(k_mem,"%s",buffer); //把k_mem中的字符传入buffer
//kstrtol:将字符串变为long类型的整数,把buffer中的字符串转化为10进制的长整型数并存入l_pid
kstrtol(buffer,10,&l_pid);
kfree(k_mem); //记得要kfree释放内核内存慎防内存泄漏
return count;
}
module_init(proc_init);
module_exit(proc_exit);
MODULE_LICENSE("GPL"); /*许可*/
MODULE_DESCRIPTION("pid"); /*模型描述*/
MODULE_AUTHOR("Lily"); /*作者*/
(2)传入虚拟机的指定文件夹,并且在该文件夹下新建Makefile(方法见操作系统(一))
(3)开始试验啦~
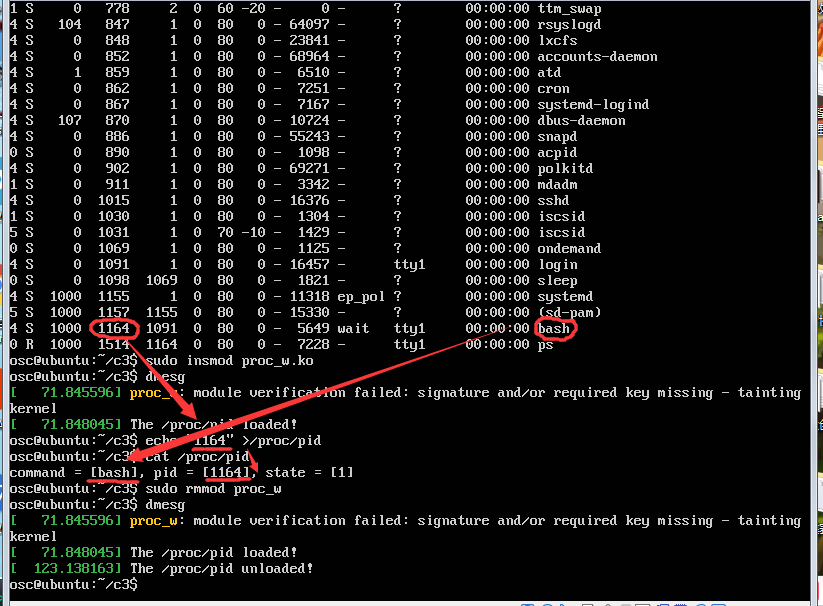
sudo dmesg -c #定期清除缓存区
make #编译
ps -el #找到bash的pid (第五列) //bash 是一个为GNU项目编写的Unix shell,也就是linux用的shell
sudo insmod proc_w.ko #加载jiffies内核模块
dmesg #显示proc_init函数中要打印的东西,即The /proc/pid loaded!
echo "1144" >/proc/pid #把bash的pid传入/proc/pid中得到信息
cat /proc/pid #显示proc_read函数中要打印的东西,此处为command、pid、state值
sudo rmmod proc_w #删除proc_w内核模块
dmesg #显示proc_exit函数中要打印的东西,检测是否正常删除
试验效果如下:
想要ps -el时不要一下子跳到底,则用:
ps -el|more
得出如下,看第一行就能知道每一列都是啥意思啦

二、作业2
(一)题目1
Project 3—Linux Kernel Module for Listing Tasks
Assignment 1
Design a kernel module that iterates through all tasks in the system using the for_each_process() macro. In particular, output the task command, state, and process id of each task. (You will probably have to read through the task struct structure in <linux/sched.h> to obtain the names of these fields.)Write this code in the module entry point so that its contents will appear in the kernel log buffer, which can be viewed using the dmesg command. To verify that your code is working correctly, compare the contents of the kernel log buffer with the output of the following command, which lists all tasks in the system:
ps -el
大致翻译:设计一个内核模块,使用for_each_process宏来遍历你在系统内的所有任务。并使用dmesg输出所有进程的进程名、状态和PID,为了验证你的结果是否准确,你的输出结果应与以下命令输出的结果相似:
ps -el
知识点:for_each_process宏的运用,init_task在linux编程中的作用。
(二)做题1~
这道题考察的是for_each_process宏的运用,具体的还是写一个module,然后在simple_init中通过for_each_process输出init_task及其引出的所有子进程。
·init_task
简单的说idle是一个进程,其pid号为 0。其前身是系统创建的第一个进程,也是唯一一个没有通过fork()产生的进程。在smp系统中,每个处理器单元有独立的一个运行队列,而每个运行队列上又有一个idle进程,即有多少处理器单元,就有多少idle进程。系统的空闲时间,其实就是指idle进程的"运行时间"。idle进程 pid = 0 ,也就是init_task.
所以,我们有:
#include <linux/sched.h> /*For task_struct*/
#include <linux/init_task.h> /*For init_task*/
static int simple_init(void){ //放在初始化函数中
struct task_struct *p;
p = NULL;
p = &init_task;
printk(KERN_INFO "ListTask module loadedn");
/* 进程号 状态 优先级 进程名称 */
printk(KERN_INFO "PIDtStatustPrioritytNamen");
for_each_process(p){
printk(KERN_INFO "%dt%ldt%dt%sn",p->pid,p->state,p->normal_prio,p->comm);
}
return 0;
}
完整代码如下:
#include <linux/sched.h> /*For task_struct*/
#include <linux/init_task.h> /*For init_task*/
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/proc_fs.h>
#include <linux/jiffies.h>
#include <asm/uaccess.h>
#define PROC_NAME "ListTask"
static struct file_operations proc_ops ={
.owner = THIS_MODULE, /*proc所有者*/
};
/*要记得proc_init始终返回0,proc_exit没有返回值。*/
/*Begin call this function when the module loaded*/
int proc_init(void)
{
struct task_struct *p;
proc_create(PROC_NAME,0666,NULL,&proc_ops); /*创建一个proc*/
p = NULL;
p = &init_task;
printk(KERN_INFO "The /proc/ListTask loaded!n");
printk(KERN_INFO "PIDtStatustPrioritytNamen");
for_each_process(p){
printk(KERN_INFO "%dt%ldt%dt%sn",p->pid,p->state,p->normal_prio,p->comm);
}
return 0;
}
void proc_exit(void)
{
remove_proc_entry(PROC_NAME,NULL); /*删除该proc*/
printk(KERN_INFO "The /proc/ListTask unloaded!n");
}
module_init(proc_init);
module_exit(proc_exit);
MODULE_LICENSE("GPL"); /*许可*/
MODULE_DESCRIPTION("output all pids"); /*模型描述*/
MODULE_AUTHOR("Lily"); /*作者*/
三、作业3
(1)题目2
Assignment 2
Beginning from init_task task, design a kernel module that iterates over all tasks in the system using a DFS tree. Just as in the first part of this project, output the name, state, and pid of each task. Perform this iteration in the kernel entry module so that its output appears in the kernel log buffer.
If you output all tasks in the system, you may see many more tasks than appear with the ps -ael command. This is because some threads appear as children but do not show up as ordinary processes. Therefore, to check the output of the DFS tree, use the command
ps -eLf
大致翻译:从init_task任务开始,设计一个内核模块,通过DFS搜索树遍历系统中的所有任务,输出每个任务的名字、状态和PID,如果你输出了系统中所有的任务,你应该会看到比ps -ael命令更多的任务,因为有些线程属于子进程,因此不会被单独列为一个进程。当你要输出DFS进程搜索树的时候,输入命令ps -eLf
知识点:init_task的使用,list_for_each宏在DFS递归树上的运用,list_entry函数的调用。
(1)做题2~
参考链接:https://zhuanlan.zhihu.com/p/81043545

-
list_head
参考资料:https://blog.csdn.net/prike/article/details/79352208
其实list_head不是拿来单独用的,它一般被嵌到其它结构中,如:struct file_node{ char c; struct list_head node; };
此时list_head就作为它的父结构中的一个成员了,当我们知道list_head的地址(指针)时,我们可以通过list.c提供的宏 list_entry 来获得它的父结构的地址。
struct list_head {
struct list_head *next, *prev;
};
//需要注意的一点是,头结点head是不使用的。
//例如
struct list_head *list;
*list 包括了 信息头+信息块(pcb)
如下图:
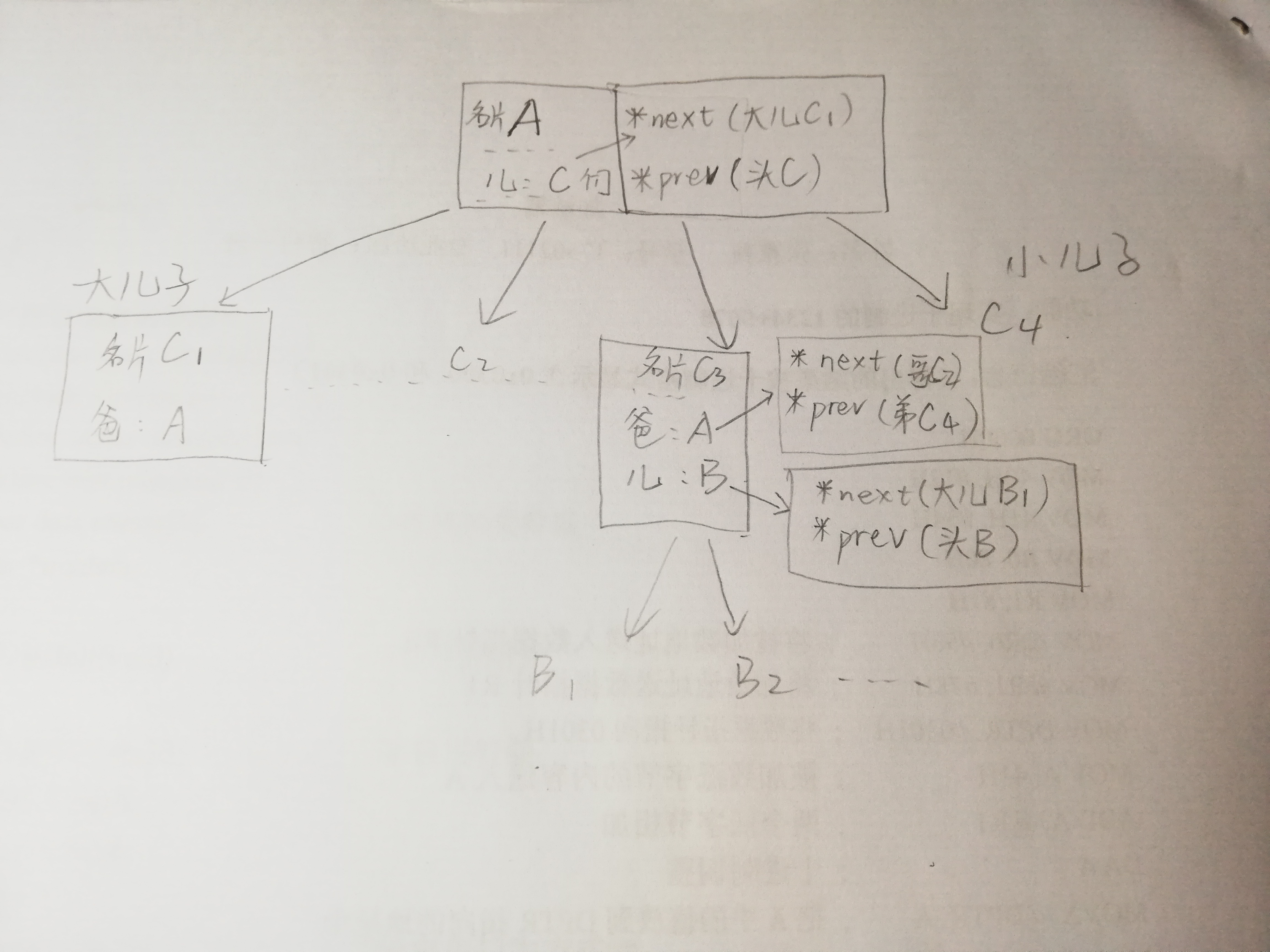
-
list_entry
list_entry(ptr,type,member)宏的功能就是,由结构体成员地址求结构体地址。其中ptr 是所求结构体中list_head成员指针,type是所求结构体类型,member是结构体list_head成员名。//例如 child = list_entry(list, struct task_struct, sibling); //使用list_entry得到该链表节点的父数据结构(也就是A的task_struct) //这个时候child就会指向当前的链表节点所表示的task_struct, 并且一次迭代下来的各个child都是兄弟进程的关系。(即遍历C1 C2 C3 C4) . -
list_for_each(pos, head)
list_for_each(pos, head);
//相当于 for (pos = (head)->next; pos != (head); pos = pos->next){ }
pos:当前节点;head:头结点(就是个信息头,没有任何信息,不使用)
//例如
开始做题啦
这道题考察的是对linux中task_struct的认识,要知道的一点就是list_head这个结构是怎么把进程们连接起来的。
首先在linux中,双向链表的实现在<linux/types.h>里面,其定义如下:
struct list_head {
struct list_head *next, *prev;
};
可以看到,linux的双向链表是没有数据域的,这是因为list_head是用于嵌套在别的数据结构中的,用于任意数据类型的双向链表实现(面向对象的思想)。
也就是说,PCB们是通过list_head的相互连接连接在一块的。
然后list_for_each宏的实现也非常基础,我们来看:
#define list_for_each(pos, head)
for (pos = (head)->next; pos != (head); pos = pos->next)
就是对整个双向链表的遍历,pos是链表的当前节点,head是链表的遍历头。
这个时候pos指向的就是当前(要访问的)节点,然后我们使用list_entry得到该链表节点的父数据结构(也就是task_struct):
p = list_entry(list,struct task_struct, sibling);
这个时候p就会指向当前的链表节点所表示的task_struct,并且一次迭代下来的各个p都是兄弟进程的关系。
首先我们来说明一下进程树的性质:
1.进程树的每一个非根节点都只有一个父节点->每一个进程都只有一个父进程
2.进程树的每一个节点都可以有多个子节点->每一个进程都可以有多个子进程
3.进程树的每一个节点都可以有多个兄弟节点->每一个进程都可以由多个兄弟进程
那其实在这一步就是BFS的思想,BFS(广度优先搜索)就是对于一棵任意的进程树来讲,每次循环都遍历每一层的所有节点。
那么一轮list_for_each之后其实已经就是使用BFS扫描了进程树的一层。但是题目要求的是DFS输出,怎么办呢?
方法一:用栈
这个时候就需要用到栈来对BFS搜到的第一层结果进行维护,达到DFS。
栈的定义:
#define MAXN 256
struct stack{
struct task_struct *data[MAXN];
int head;
}st;
int st_size(void){return st.head;}
bool st_empty(void){return st.head == 0;}
bool st_full(void){return st.head == MAXN;}
struct task_struct *st_pop(void){
if(st_empty())return NULL;
st.head -= 1;
return st.data[st.head];
}
bool st_push(struct task_struct *t){
if(st_full()) return false;
st.data[st.head++]=t;
return true;
}
我们定义了一个最基本的栈,拥有查询基本状态和入栈/出栈的方法。
我们知道,整棵进程树的根节点为init_task,其引用由内核维护,我们取得它的地址压在栈底。
st.head = 0;
st_push(&init_task);
我们知道,栈有着这样的属性:LIFO,也就表明我们可以将第一层的子节点压栈,然后弹出栈顶,通过list_for_each来得到该子节点的所有子节点,将这些得到的节点继续压栈,那么弹栈的就是子节点的子节点,这样我们就实现了DFS。
struct task_struct *tsk,*p;/*tsk is stack-head element, p is current task_struct*/
struct list_head *list,*list2;/*list maintains ascending-order BFS and list2 maintains desending-order BFS*/
while(!st_empty())
{
tsk = st_pop();
if((&tsk->children)->next!=(&tsk->children))/*Have child process*/
printk(KERN_INFO "The child processes of %s (with pid:%d) is:n",tsk->comm,tsk->pid);
list_for_each_prev(list,&tsk->children){ /*ascending-order push*/
p = list_entry(list,struct task_struct, sibling);
st_push(p);
}
list_for_each(list2,&tsk->children){
/*Maintain a list for forward display*/
p = list_entry(list2,struct task_struct, sibling);
printk(KERN_INFO "name [%s] status [%d] pid [%d]n",p->comm,p->state,p->pid);
}
}
这里用list_for_each_prev的原因是:我们希望PID小的进程先被DFS遍历到。如果你希望PID大的先被遍历到,就可以使用list_for_each。
如果你想输出所有进程的BFS树,可以使用内核提供的kfifo来维护一个队列,输出完该进程之后就退队即可。内核队列的实现文件在<linux/kfifo.h>,其实现供有兴趣的读者留作练习。
如果要让输出结果可以暂停可以使用如下命令
dmesg | more
这样你按任意键,结果才会往下滚一页,方便查看结果。
方法二:用递归
void dfs(struct task_struct *task){
struct task_struct *child;
struct list_head *list;
printk( KERN_INFO "command = [%s] pid = [%d] state = [%ld]",task->comm,task->pid,task->state);
list_for_each(list, &task->children){
child = list_entry(list, struct task_struct, sibling);
dfs(child);
}
}
//main
dfs(&init_task);
最后
以上就是迷你爆米花最近收集整理的关于操作系统(三):父子进程(下)的全部内容,更多相关操作系统(三)内容请搜索靠谱客的其他文章。








发表评论 取消回复