官方网址:http://pytorch.org/docs/nn.html
数据加载
torch.utils.data.DataLoader
train_iter = torch.utils.data.DataLoader(
dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0
)
函数解释
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, num_workers=0,
collate_fn=default_collatem, pin_memory=False, drop_last=False)
数据加载器(数据集,批处理大小=1,随机播放=False,采样器=None,numu workers=0,
collateu fn=defaultu collatem,pinu内存=False,dropu last=False)
数据迭代
for batch_idx,(inputs,labels) in enumerate(train_loader,0): # 从0开始迭代
print(batch_idx)
函数解释
以上程序中inputs的大小为[batchsize,每个运算数据的大小]
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) # 下标从 1 开始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
train_loader为一个batchszie,batch_idx是迭代次数的索引可以帮助输出阶段参数,
enumerate:返回值有两个:一个是序号,也就是在这里的batch地址,一个是数据train_ids
for i, data in enumerate(train_loader,1): # 注意enumerate返回值有两个,一个是序号,一个是数据(包含训练数据和标签)
x_data, label = data
nn.Module
可通过继承 MODULE 类来构造模型,Module 类是 nn 模块⾥提供的⼀个模型构造类,是所有神经⽹络模块的基类
模型:
class MyConv2D(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size):
super(MyConv2D, self).__init__()
# 初始化卷积层的2个参数:卷积核、偏差
if isinstance(kernel_size, int):
kernel_size = (kernel_size, kernel_size)
self.weight = nn.Parameter(torch.randn((out_channels, in_channels) + kernel_size))
self.bias = nn.Parameter(torch.randn(out_channels, 1, 1))
def forward(self, x):
"""
:param x: 输入图片,shape(batch_size, C_in, H, W)
:return: shape(batch_size,C_out, H_out, W_out)
"""
return corr2d_multi_in_out(x, self.weight) + self.bias
# corr2d_multi_in_out是可在类的初始化或全局定义的函数
调用:
net = MyConv2D()
net(X) # 实例化后传入参数X,系统将自动调用forward来完成前向计算。
Module的子类: Sequential(ModuleList 和 ModuleDict与Sequential类似,主要参数形式不同)
# 先导入from torch.nn import init
# 用net.parameters() & net.named_parameters() & net.state_dict()初始化模型的参数
class MyConv2D(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size):
self.weight = nn.Parameter(torch.randn((out_channels, in_channels) + kernel_size))
self.bias = nn.Parameter(torch.randn(out_channels, 1, 1))
# 或默认的初始化方法,如线性层
m=nn.Linear(3, 4)# 线性层有weight和bias两个参数
print(m.weight) #size:(3, 4)
print(m.bias) #size:(1, 4)
net = MySequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
net(X)
训练过程
x = Variable(torch.ones(2,2),requires_grad = False) temp = Variable(torch.zeros(2,2),requires_grad = True) y = x + temp + 2 y = y.mean() #求平均数 y.backward() #反向传递函数,用于求y对前面的变量(x)的梯度 print(x.grad) # d(y)/d(x)
定义模型与训练过程
# 定义模型
net = ConvMoule().to(device)# nn
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
# 在定义好模型之后
optimizer.zero_grad()
output = net(data)
loss = criterion(output, target.long())
loss.backward() # Back Propagation
optimizer.step() # Gardient Descent
total_loss += loss.item()
optimizer.zero_grad()
打印参数
def parameters(self):
for name, param in self.named_parameters():
yield param
for name, param in model.named_parameters():
if param.requires_grad:
print(name)
PyTorch 中,nn 与 nn.functional 有什么区别?
面向对象
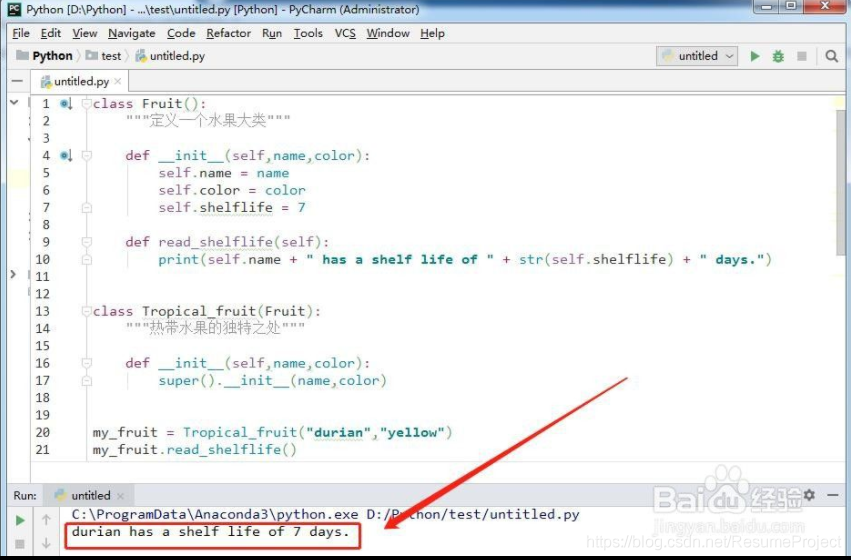
类的- -init- -方法:
初始化对象属性的构造方法,实例化类时此方法会自动执行,如果实例化类时给类传了参数,则此参数也是呈交给此方法来处理输入的数据
类的其他方法:
类方法的创建,此与函数的定义相类似,区别在于类方法的创建首个形参必须是self
super函数与多继承
python super函数,Python3.x 和 Python2.x 的一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx
python 多继承
Python3.x 和 Python2.x 的一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx
flatten
1)flatten(x,1)是按照x的第1个维度拼接(按照列来拼接,横向拼接);
2)flatten(x,0)是按照x的第0个维度拼接(按照行来拼接,纵向拼接);
3)有时候会遇到flatten里面有两个维度参数,flatten(x, start_dim, end_dimension),此时flatten函数执行的功能是将从start_dim到end_dim之间的所有维度值乘起来,其他的维度保持不变。例如x是一个size为[4,5,6]的tensor, flatten(x, 0, 1)的结果是一个size为[20,6]的tensor。
常见错误与注意
测试集不进行梯度变化:
用with torch.no_grad():包起来
x.view(x.shape[0], -1)
pytorch提示:torch.device’ object has no attribute ‘_apply’
原因是模型没有实例化,net = model() 写成了 net = model;
忘了加括号,笑哭。。。
pytorch提示:named_parameters() missing 1 required positional argument: ‘self’
调用类的方法时一定要加括号,net = AlexnetOfTV.AlexNet应为net = AlexnetOfTV.AlexNet(),然后再使用net.named_parameters()读取参数。
<built-in method size of Tensor object at 0x000001B4AC242098>
size后少了()
Pytorch出现‘Tensor‘ object is not callable解决办法
Can’t call numpy() on Tensor that requires grad. Use tensor.detach().numpy() instead.
all_prediction = np.concatenate((all_prediction,prediction),axis=0)改成
all_prediction = np.concatenate((all_prediction,prediction.detach().cpu().numpy()),axis=0)
NotImplementedError:未实现错误,比如net实例化结果代码中没有实现forward函数
takes 1 positional argument but 2 were given
在类函数中加上self,因为在类调用类内部函数时,会自动传入self参数;在函数调用是传入参数是(self,x)
参数 batch_first=True
pytorch的bug
expected scalar type Double but found Float
transf = transforms.ToTensor()
img_tensor = transf(img)
x = img_tensor.unsqueeze(0)
y = net.features(x)# 提取特征
img_tensor = transf(arr).to(torch.float32)# 第二次报错,需类型转换[PyTorch]中的数据类型
x = img_tensor.unsqueeze(0)
y = net.features(x)# 提取特征
python+pycharm小技巧
函数的参数类型
打印结果到文件:
f = open("./output/recard", 'w+')
print("结果", file=f)
__all__
如果这个包内的类或方法不在__all__里面,就相当于没有上白名单,外面的包就不能正常使用这些没有上白名单的方法和类。
如果没有设置__all__,那么外面可以通过包内的约定来显示可见性。即:python通过private对应两个下划线__,protected对应一个下划线_,public 对应没有下划线,来约定类似于java的可见性控制。
python中的_all_用法
【Python】用 all 暴露接口
__init__.py
__init__.py的在文件夹中,可以使文件夹变为一个python模块,python的每个模块对应的包中都有一个__init__.py文件的存在
通常__init__.py文件为空,但是我们还可以为它增加其他的功能,我们在导入一个模块时候(也叫包),实际上导入的是这个模块的__init__.py文件。我们可以在__init__.py导入我们需要的模块,不需要一个个导入
_init_.py 中还有一个重要的变量,叫做 _all_。我们有时会使出一招“全部导入”,也就是这样:from PackageName import *,这时 import 就会把注册在包 init.py 文件中 all 列表中的子模块和子包导入到当前作用域中来
python无法导入自己的模块的解决办法
https://blog.csdn.net/weixin_40841247/article/details/88682551
RuntimeError: expected padding to be a single integer value or a list of 1 values to match the convolution dimensions, but got padding=[0, 0]
————————————————
版权声明:本文为CSDN博主「gdymind」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/gdymind/article/details/82933534
还有一种可能:你的赋值少了一个维度,卷积核的维度应该是这样的
pycharm dubug不成功原因
可能是系统原因,还有可能是断点在注释上
python 删除字典中的某个元素
最后
以上就是欣喜龙猫最近收集整理的关于pytorch -nn基础数据加载nn.ModuleModule的子类: Sequential(ModuleList 和 ModuleDict与Sequential类似,主要参数形式不同)面向对象常见错误与注意pytorch的bugpython+pycharm小技巧的全部内容,更多相关pytorch内容请搜索靠谱客的其他文章。

![mmClassification学习笔记前言mmcv安装mmcv库文件夹架构mmcv概要mmcvclassification文件夹官方给的demo[只是一个模型推理]根据官方教程进行学习](https://www.shuijiaxian.com/files_image/reation/bcimg12.png)





![while[0 -gt 0]: 未找到命令_TensorFlow 2.0 简明指南](https://www.shuijiaxian.com/files_image/reation/bcimg18.png)
发表评论 取消回复