3D检测中点云的表征方式总结(一)
- 1.RSN: Range Sparse Net for Efficient, Accurate LiDAR 3D Object Detection(cvpr2021)
- 2.PV-RCNN: Point-voxel feature set abstraction for 3D object detection(cvpr2020)
- 3.HVPR: Hybrid Voxel-Point Representation for Single-stage 3D Object Detection(cvpr2021)
- 4.HVNet: Hybrid Voxel Network for LiDAR Based 3D Object Detection(cvpr2020)
- 5.Cylindrical and asymmetrical 3D convolution networks for LiDAR segmentation(cvpr2020)
- 6.It’s all around you: Range-guided cylindrical network for 3D object detection
- 7.End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds
- 8.Pillar-based Object Detection for Autonomous Driving(eccv2020)
- 9.Every View Counts: Cross-View Consistency in 3D Object Detection with Hybrid-Cylindrical-Spherical Voxelization(nips2020)
- 10.Center-based 3D object detection and tracking
- 11. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation(cvpr2017).
- 12.SECOND: Sparsely Embedded Convolutional Detection.
- 13.VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection(cvpr2018).
1.RSN: Range Sparse Net for Efficient, Accurate LiDAR 3D Object Detection(cvpr2021)
数据集: Waymo datasets。
最终特征:voxel级别的特征(point pillar方式)。
先使用一个unet的分割网络,将点分成前景点和背景点,然后只用前景点(使后面的稀疏卷积更有效),使用pointpillar的表征提取方式,进入设计的稀疏网络。类别分开训练。
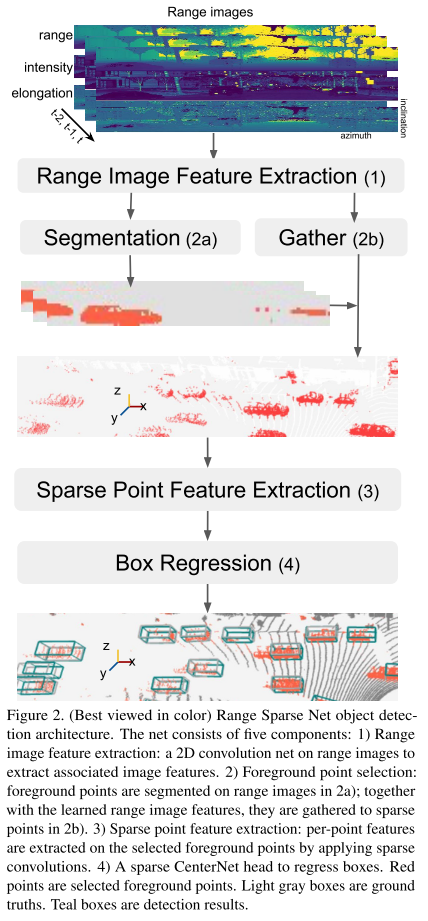
2.PV-RCNN: Point-voxel feature set abstraction for 3D object detection(cvpr2020)
数据集: kitti datasets。
最终特征:point级别的特征(融合了voxel级别的特征)。
先将原始点云提体素特征,分成H×W×C个格子,求mean,进入3D稀疏网络,进行不同倍数的下采样,然后在最后一个下采样上拍成bev,做一个ROI,得到候选框,以及前后背景。然后在原始点云上使用FPS进行点的采样,当做一个key point,将该点映射到不同下采样倍数的feature map上,得到该点在该feature map上的特征,将不同feature map上的该点的特征拼接起来,作为最后的feature map,是进行fps下采样后的point-wise的特征,根据前后背景点给予不同权重。
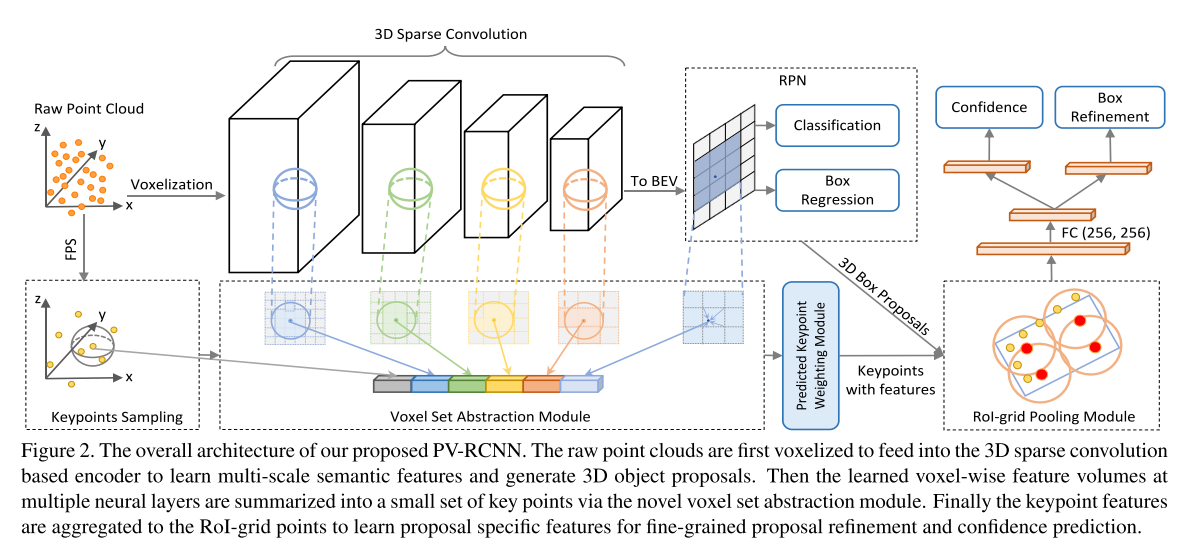
3.HVPR: Hybrid Voxel-Point Representation for Single-stage 3D Object Detection(cvpr2021)
数据集: kitti datastets。
最终特征:voxel级别的特征。
分别提取voxel级别和points级别的特征。voxel级别的特征采用point pillar的方式,以point net作为excoder得到voxel级别的特征。points是按照PointNet++的方式在点级别,使用3d卷积直接得到点的特征。然后将点的特征与voxel的特征进行点乘,得到一张相关性的map,根据相关性分数得到离某个voxel最近的k个点的特征,计算这k个点和这个voxel的匹配概率,然后将该概率乘以该点的特征赋予到该voxel作为最后的feature。最终的feature 是voxel级别,point-wise上的特征提取用的point net。具体实现是将voxel 以及其feature存到了memory中以为了更快,但是是在kitti上做的实验,kitti数据集较少,可以这么存,数据大了无法做到。
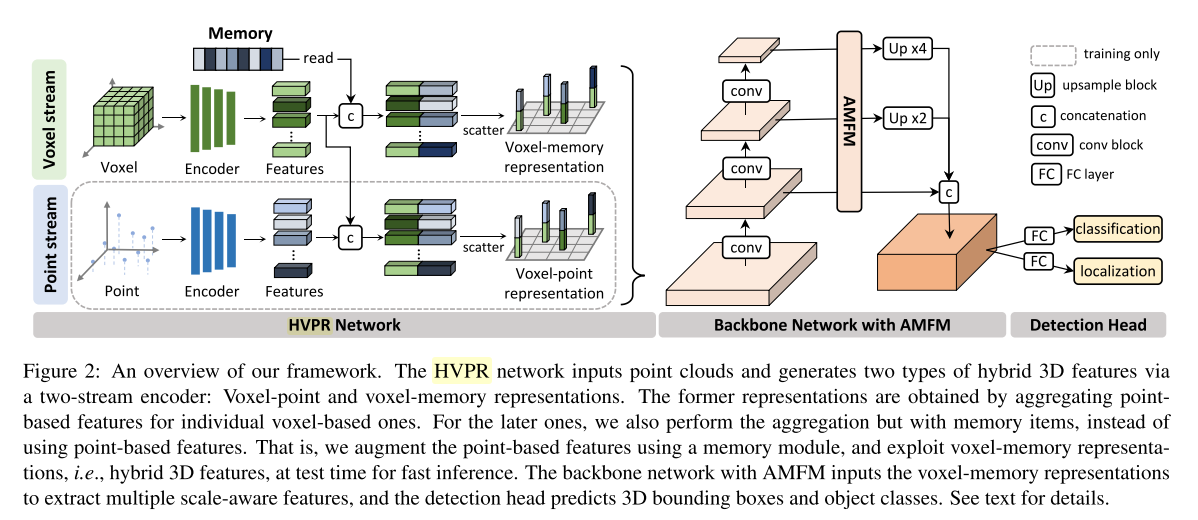
4.HVNet: Hybrid Voxel Network for LiDAR Based 3D Object Detection(cvpr2020)
数据集: kitti datasets。
最终特征:point级别的特征(融合了voxel级别特征)。
point-wise的特征提取就是xyz;voxel-wise的特征提取:在进行体素化的时候,使用了不同的尺寸,以得到不同粒度的特征。使用attention模块对不同尺度的voxel赋予不同的权重,然后将其进行拼接,同时拼接到voxel中对应的点上。生成伪图像特征图。
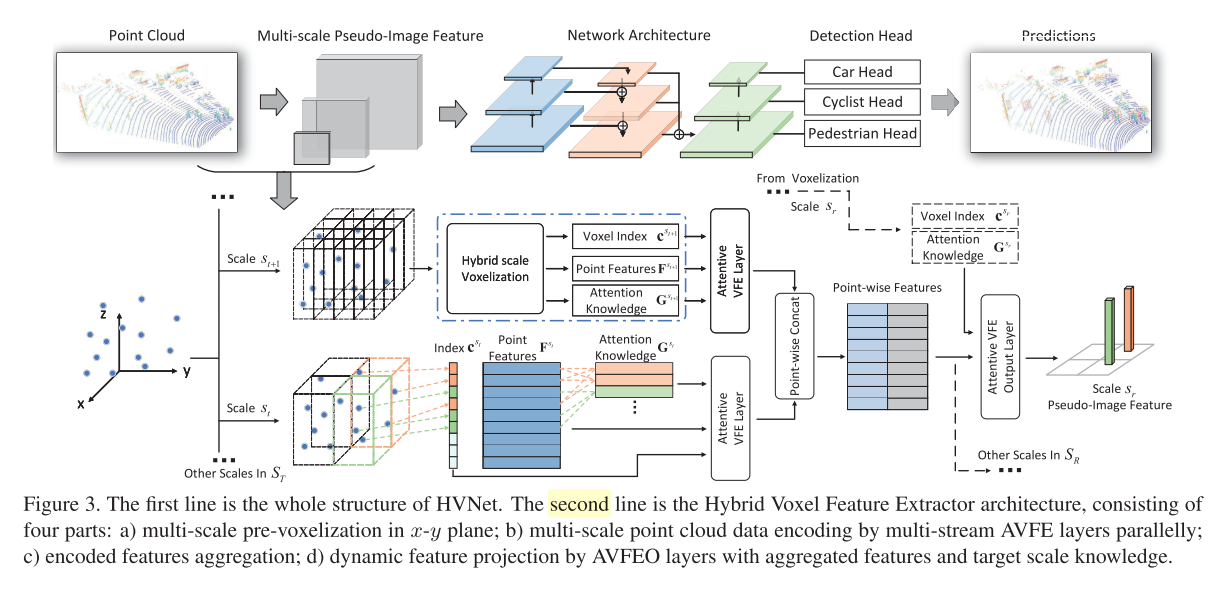
5.Cylindrical and asymmetrical 3D convolution networks for LiDAR segmentation(cvpr2020)
数据集:SemanticKITTI and nuScenes
最终特征:voxel级别的特征。
基于cylindrical坐标系下的点云分割。
具体的特征提取方式:
首先将点进行圆柱坐标系下的grid划分,通过半径,角度等参数完成;然后将全部点云进入多个MLP的操作(n*3的点云直接进入mlp),每个点保留在cyclindrical的坐标,然后将mlp过后的特征赋予到cyclidrical坐标下的每个cell里。得到cylindrical feature,应该属于voxel级别的feature吧
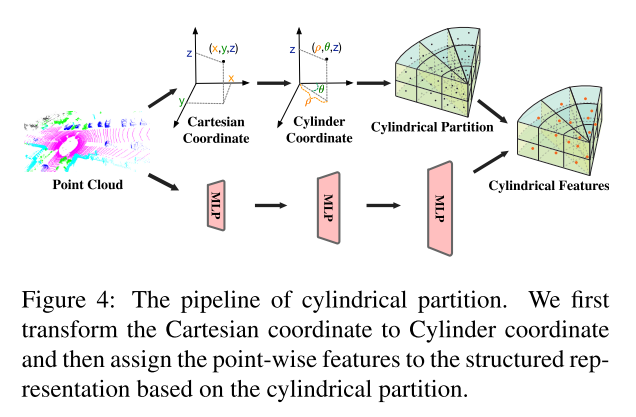
6.It’s all around you: Range-guided cylindrical network for 3D object detection
数据集:nuscense
最终特征:点特征和voxel级别的特征在特征层面上的融合。
特征级别的融合。全部点云的特征提取,再融合range view级别的特征。这里的range view是Cylindrical coordinates。
second基础上做的。全点云输入,用3d卷积处理,然后基于range的特征提取后输入,用3d卷积处理,在中间的主干网,两个方面的特征进行融合(相乘),然后用级联操作,concat到最后作为下一个block的输入。实验结果逊色于center point。基础代码也是在center point上操作的。
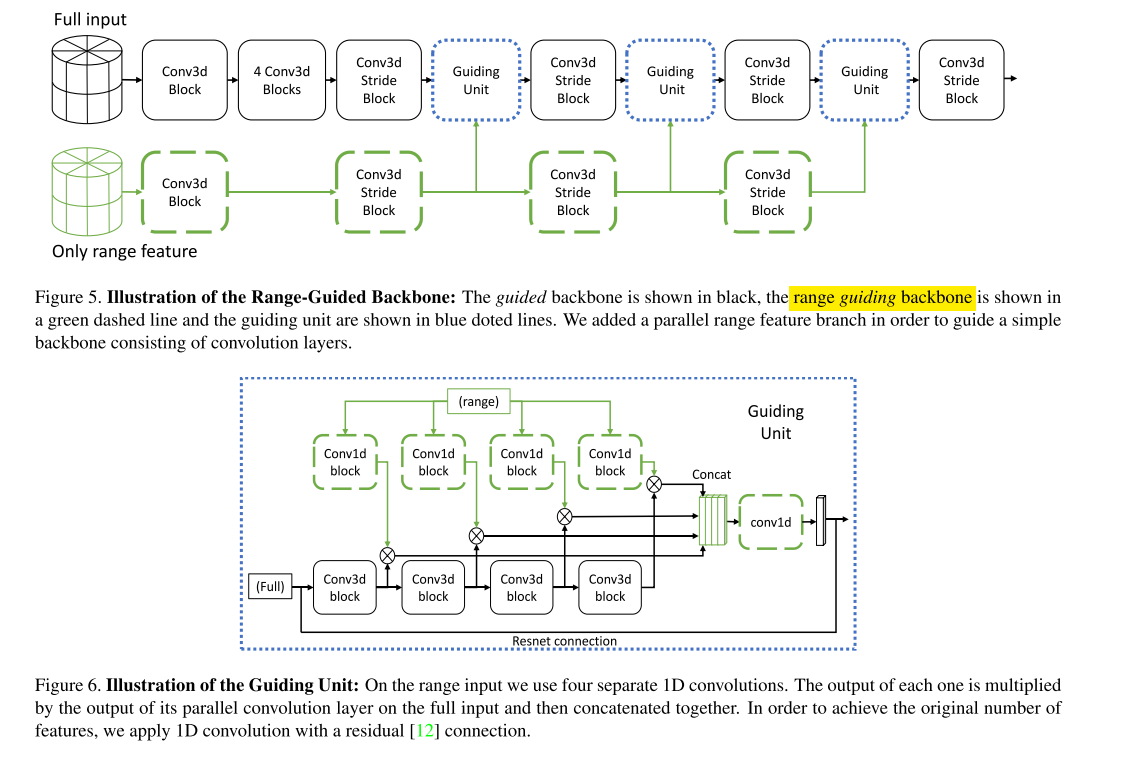
7.End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds
数据集:Waymo Open Dataset。
最终特征:point级别的特征。
bev坐标系和透视坐标系下的特征提取及融合。
首先在bev坐标系下进行体素的提取。然后用FC和maxpooling的方式得到voxel级别的特征(类似于point pillar),透视坐标系下的基于voxel级别特征提取方式一致,然后在点级别上进行concat,一对多的关系。最终的特征是点级别的特征。
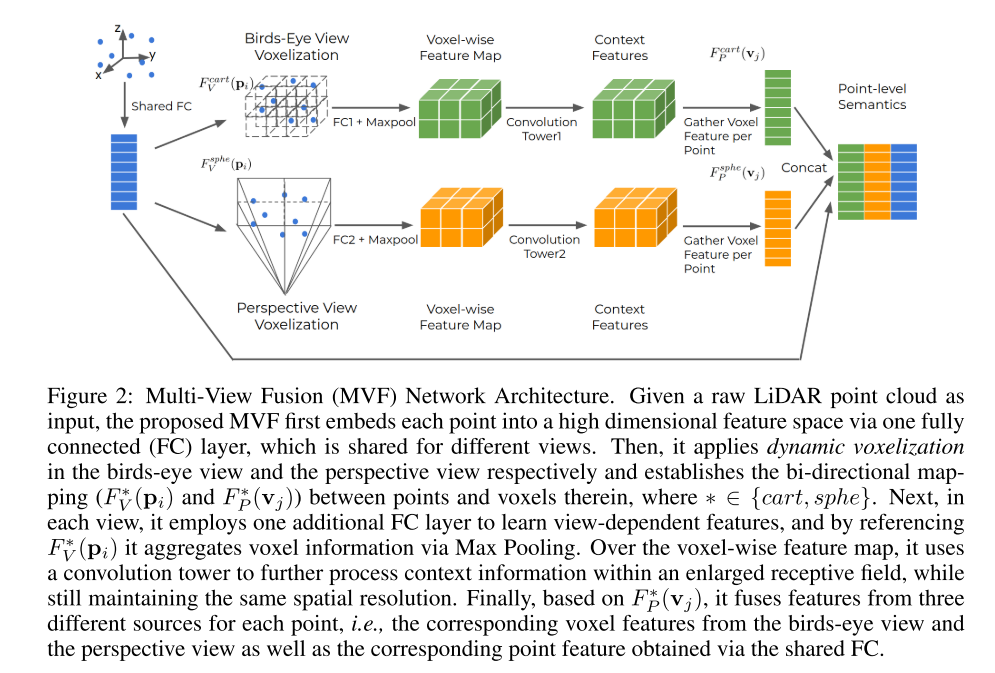
8.Pillar-based Object Detection for Autonomous Driving(eccv2020)
数据集:Waymo Open Dataset。
最终特征:point级别的特征(融合不同view级别的voxel特征)。
Cylindrical坐标系和bev坐标系的融合。和7,做对比,以及和球体坐标系做对比,该方法效果较好。
分别在圆柱坐标系和bev坐标系下得到pillar的特征,然后使用最近邻或者是插值法赋予到对应的点上,然后将点再进行一次point pillar,拍成bev进入检测。点级别上对齐。
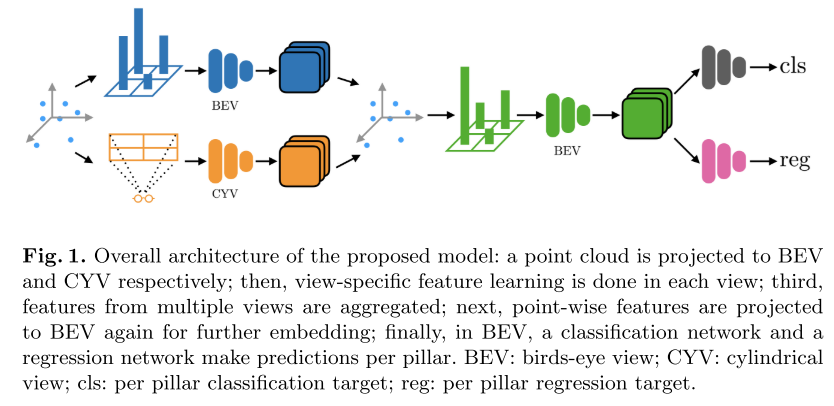
9.Every View Counts: Cross-View Consistency in 3D Object Detection with Hybrid-Cylindrical-Spherical Voxelization(nips2020)
数据集:NuScenes 3D detection dataset
该篇paper是发表在nips2020,主要的贡献是将多个view的特征进行融合,包括bev,mvf,cylindrical等,融合方式是在loss层面上。不过mAP表现不如it’s all around you,(test集上的map),不如center point。
10.Center-based 3D object detection and tracking
数据集:NuScenes 3D detection dataset
该篇paper的表征使用了point pillar和voxel net的表征提取方式,并将两种方法做对比。voxel net精度高于point pillar,但是复杂度也大于point pillar。
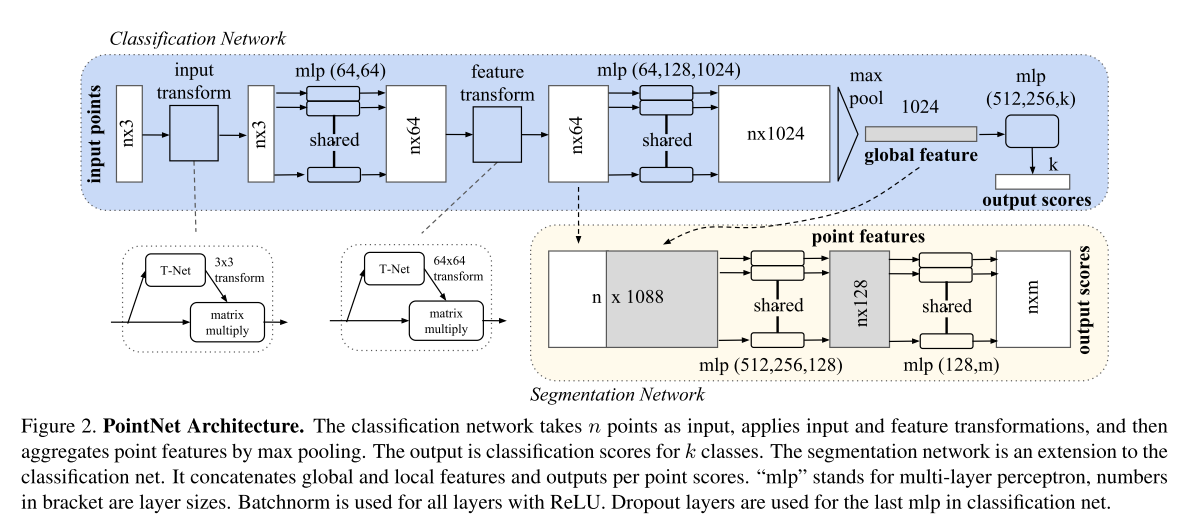
11. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation(cvpr2017).
最终特征:point级别特征。
表征相关:
点云直接输入,经过一个mlp,核为(1,3),因为点是(x,y,z),然后经过各种转换,mlp,maxpooling后输出一个全局的feature map。
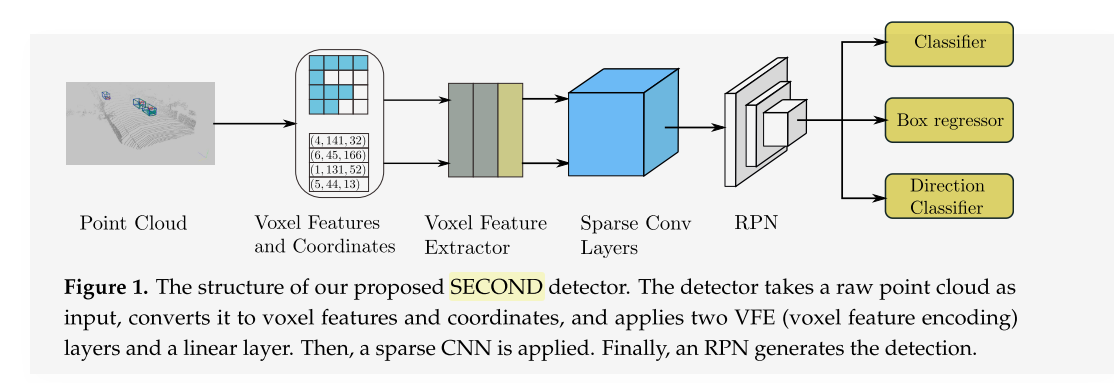
12.SECOND: Sparsely Embedded Convolutional Detection.
第一个提出稀疏卷积的paper
representation:划分voxel,用vfe对每个voxel提取特征(与voxelnet一样,也是pointnet),然后直接进入3d稀疏卷积,
rpn:使用类似ssd作为rpn,上采样之后concat在一起,后面跟一个1x1的conv分别展开不同的head任务。
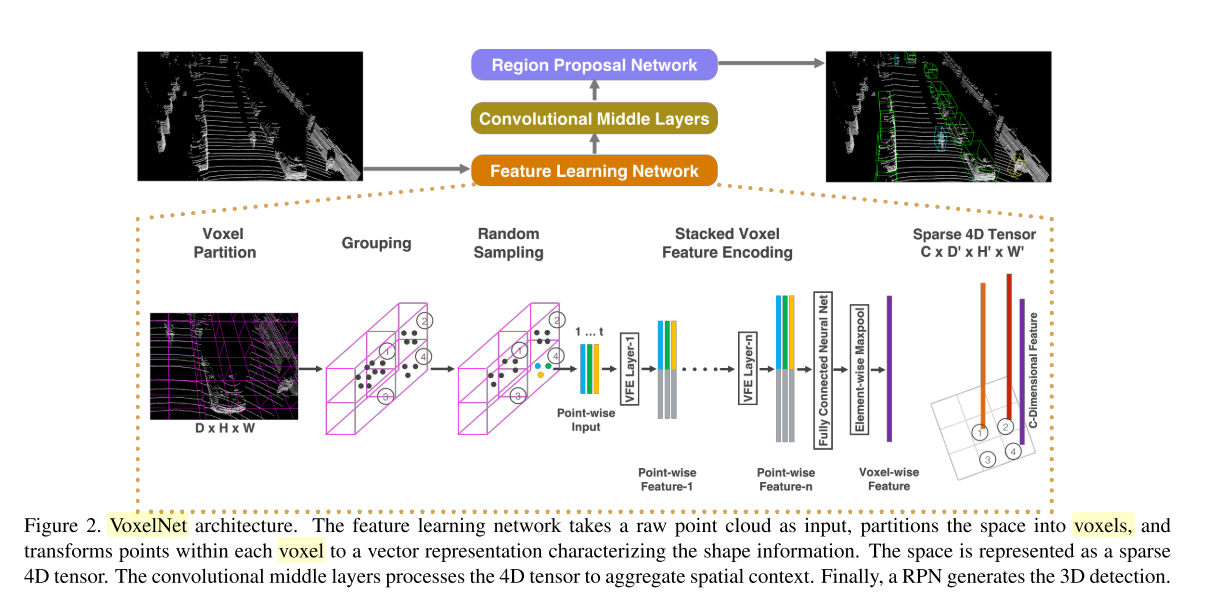
13.VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection(cvpr2018).
representation:划分voxel,voxel中也进行sampling,然后对每个voxel经过一个point net提取局部特征,将局部特征拼接到每个point之后,然后过一个fc,一个maxpoolong得到voxel级别的特征,然后过一个3d卷积
最后
以上就是健壮火龙果最近收集整理的关于3D目标检测中点云的表征方式总结(一)1.RSN: Range Sparse Net for Efficient, Accurate LiDAR 3D Object Detection(cvpr2021)2.PV-RCNN: Point-voxel feature set abstraction for 3D object detection(cvpr2020)3.HVPR: Hybrid Voxel-Point Representation for Single-stage 3D Object的全部内容,更多相关3D目标检测中点云的表征方式总结(一)1.RSN:内容请搜索靠谱客的其他文章。








发表评论 取消回复