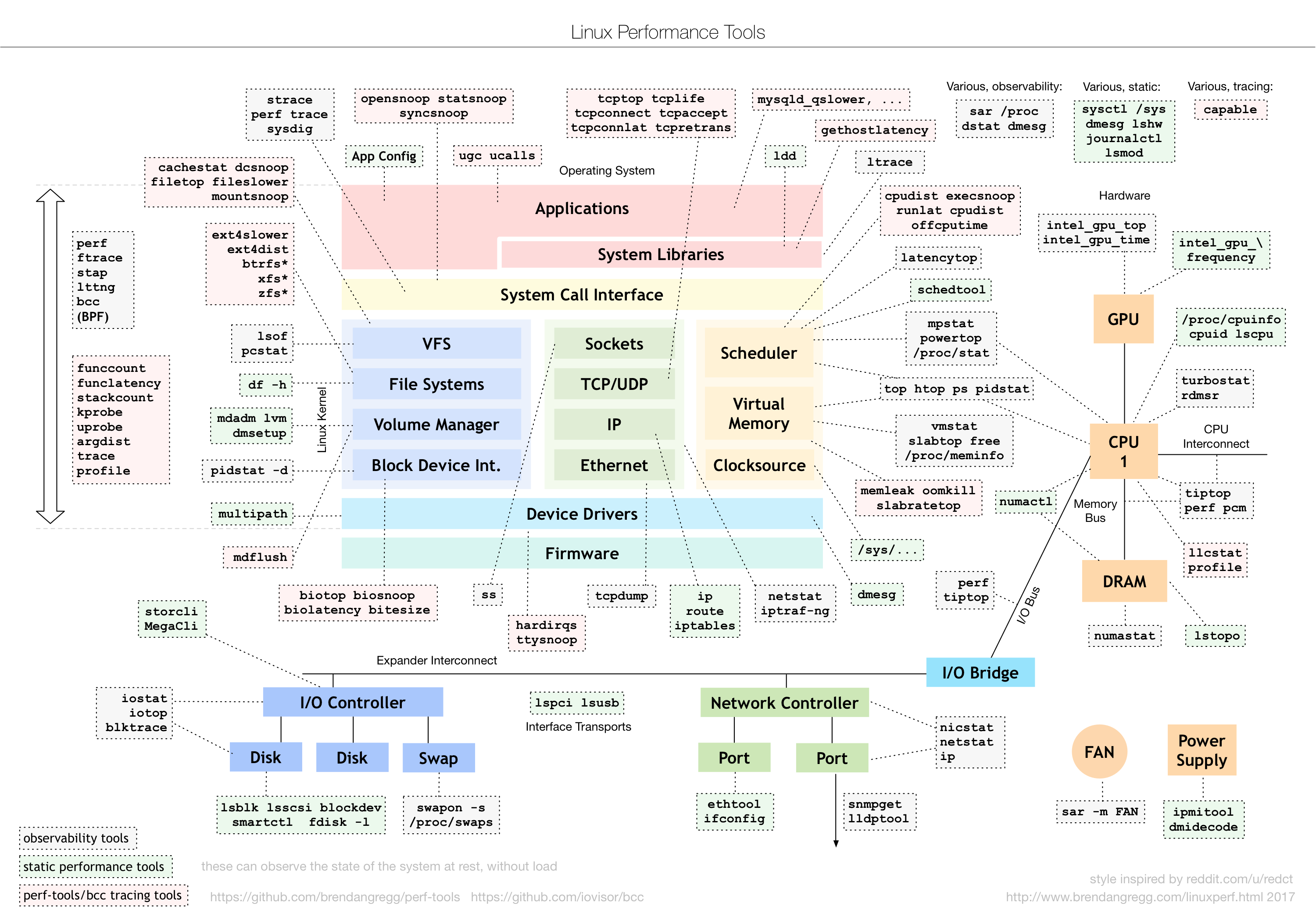
1.Linux性能工具图
2.性能优化方向
3.CPU
⑴平均负载
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,可以简单理解为平均活跃进程数,它和 CPU 使用率并没有直接关系。
当我们使用top或uptime时候可以看到:
load averages: 3.91 4.40 4.94
过去 1 分钟、5 分钟、15 分钟的平均负载(Load Average),注意顺序哈!平均负载的三个值的是一种进程活跃趋势。
-
可运行态 是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程
-
不可中断态 是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程,是系统对进程和硬件设备的一种保护机制
当平均负载为 2 时,意味着什么呢?
- 在只有 2 个 CPU 的系统上,意味着所有的 CPU 都刚好被完全占用。
- 在 4 个 CPU 的系统上,意味着 CPU 有 50% 的空闲。
- 而在只有 1 个 CPU 的系统中,则意味着有一半的进程竞争不到 CPU。
一般当平均负载高于 CPU 数量 70% 的时,我们就应该注意了。
平均负载和CPU使用率的关系:
平均负载它仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。
而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。
- CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的
- I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高
- 大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高
⑵CPU上下文切换
平均负载升高有个容易被忽视的原因就是多个进程竞争 CPU,CPU 上下文切换。
CPU上下文包括:
- 寄存器 CPU自带的快速内存
- 程序计数器 存储当前或者即将执行的下一条指令位置
CPU 上下文切换就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
①进程上下文切换
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间
- 内核空间具有最高权限,可以直接访问所有资源
- 用户空间只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。
②线程上下文切换
③中断上下文切换
工具篇:
stress 是一个 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景
mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标
# -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据
$ mpstat -P ALL 5
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:30:06 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:30:11 all 50.05 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 49.95
13:30:11 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
13:30:11 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
$ pidstat -u 5 1
13:37:07 UID PID %usr %system %guest %wait %CPU CPU Command
13:37:12 0 2962 100.00 0.00 0.00 0.00 100.00 1 stress
top和ps或者lsof
htop 因为它更直接(在F2配置中勾选所有开关项,打开颜色区分功能),不同的负载会用不同的颜色标识。比如cpu密集型的应用,它的负载颜色是绿色偏高,iowait的操作,它的负载颜色是红色偏高等等
atop命令,好像是基于sar的统计生成的报告,直接就把有问题的进程标红了,更直观
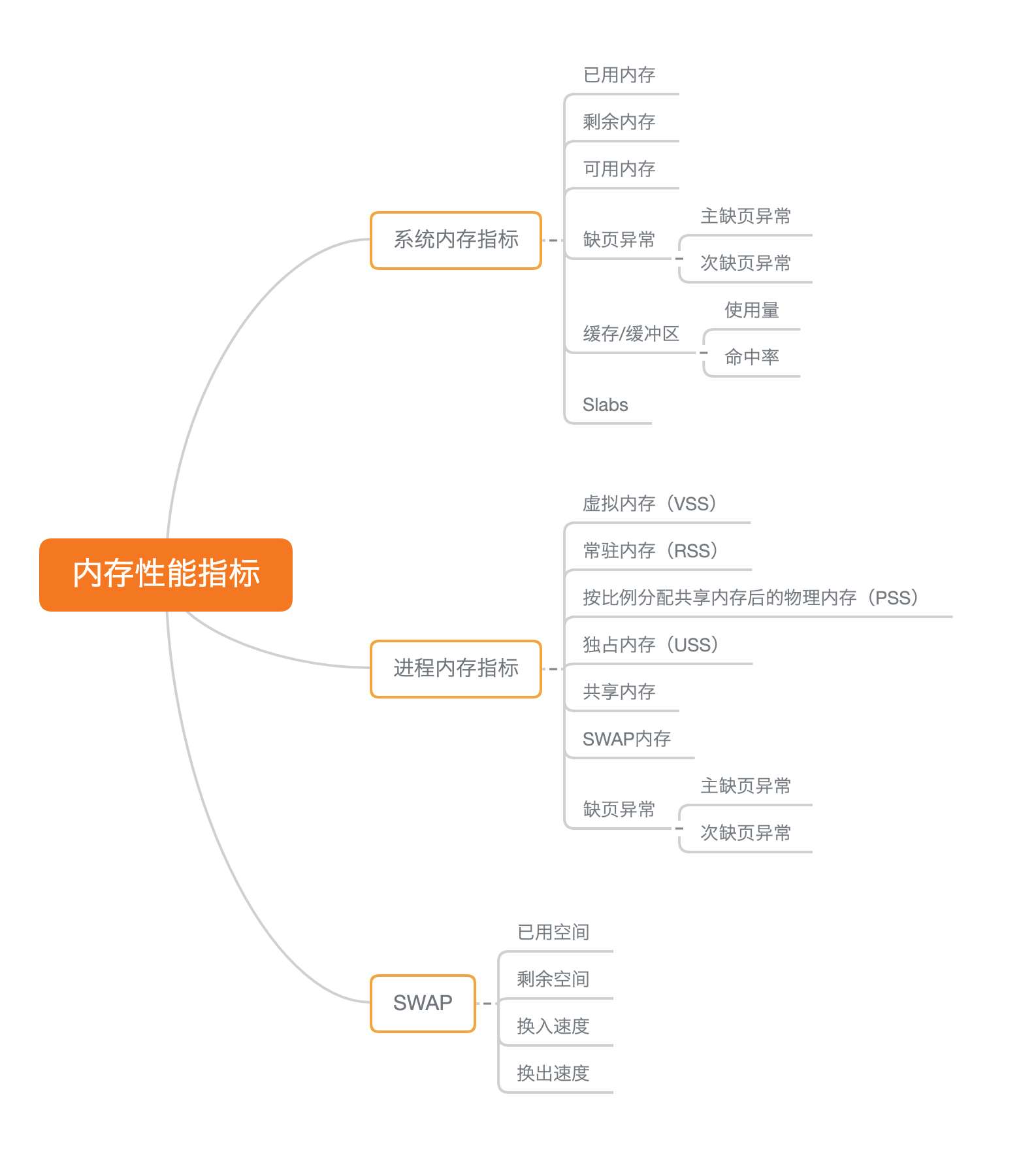
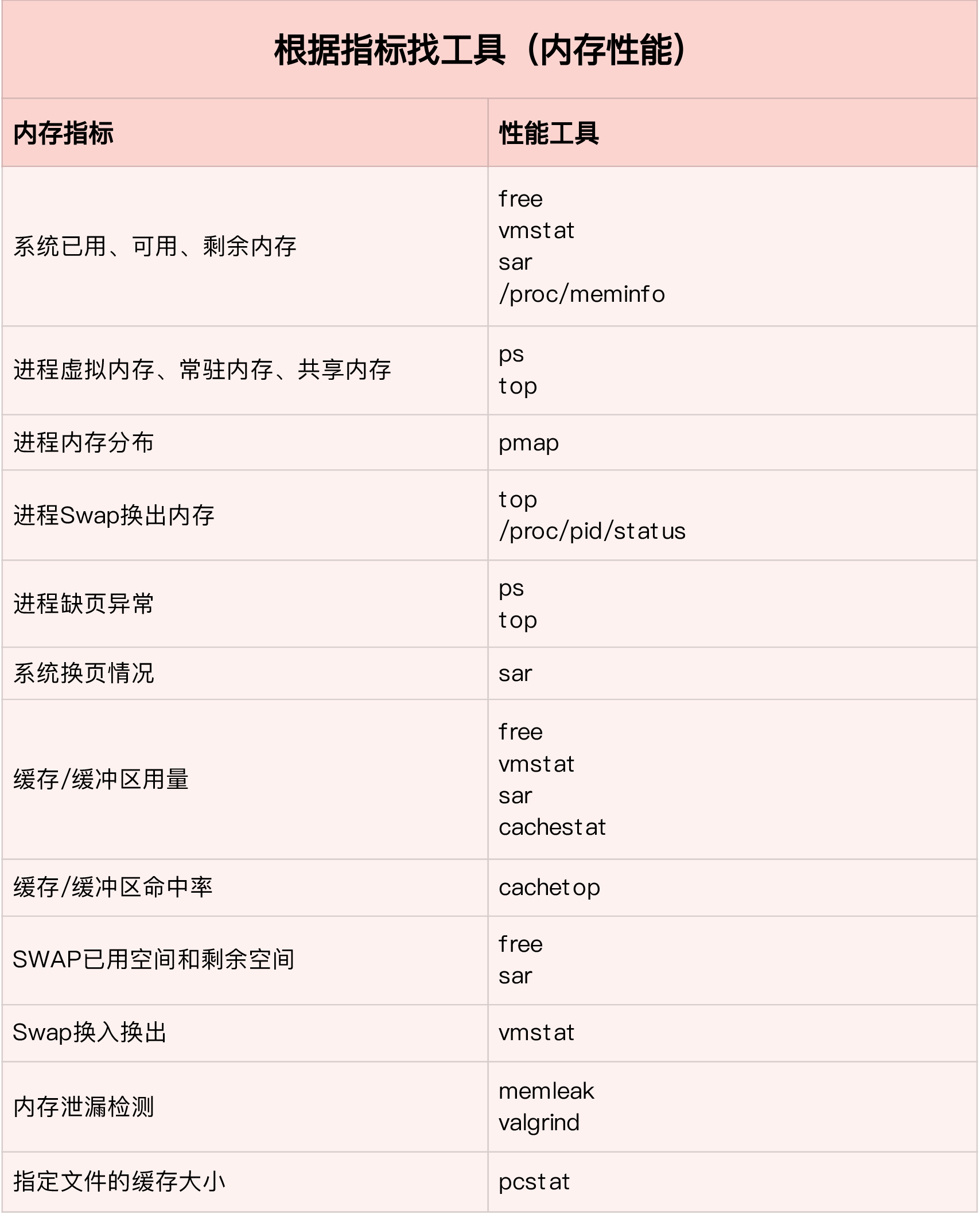
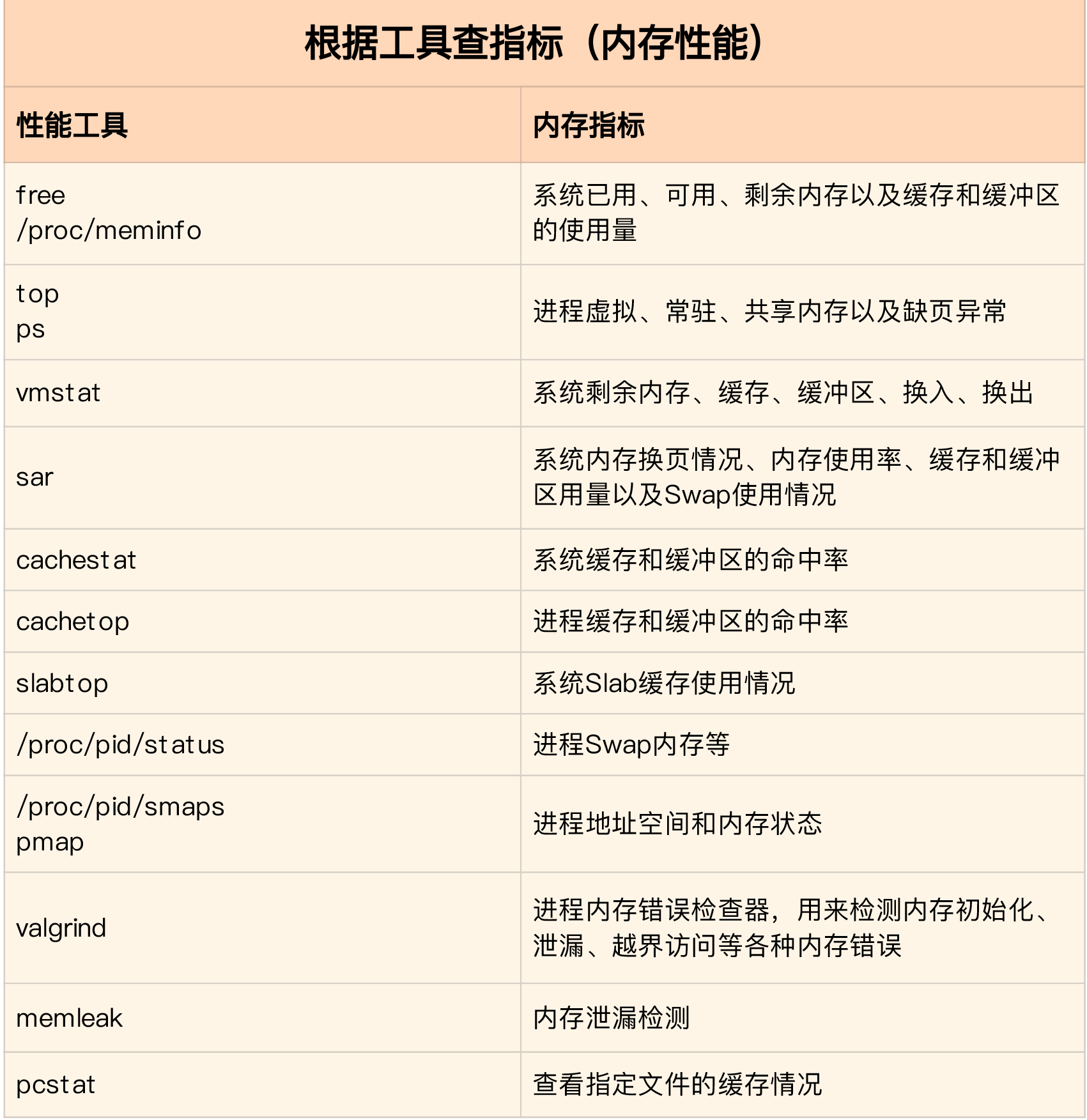
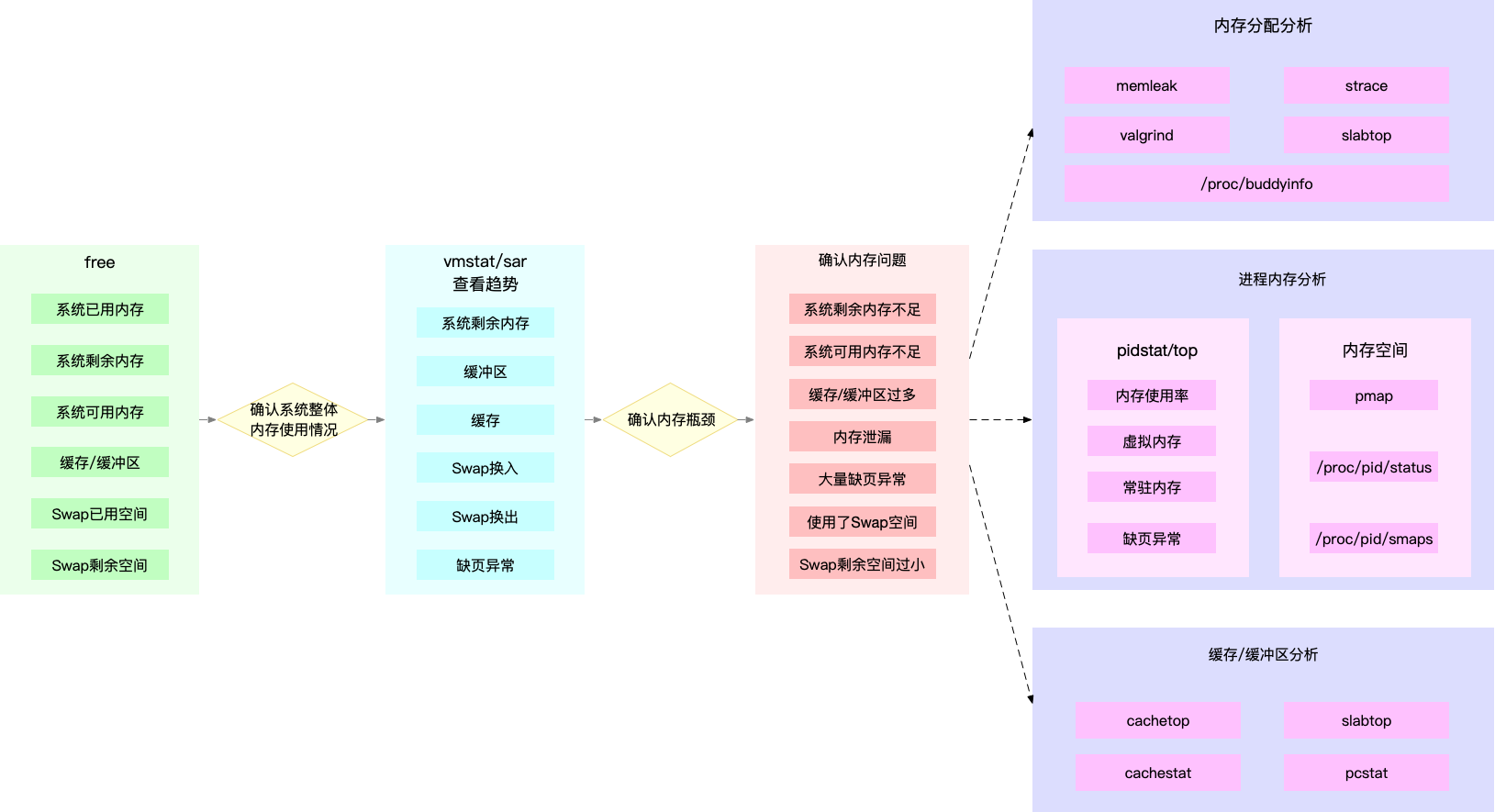
4.内存
5.网络
⑴查看网络配置命令
ifconfig eth0
eth0 Link encap:Ethernet HWaddr F6:DA:F4:1F:5E:CB
inet addr:10.144.46.155 Bcast:10.144.255.255 Mask:255.255.0.0
inet6 addr: fe80::f4da:f4ff:fe1f:5ecb/64 Scope:Link
UP BROADCAST RUNNING(表示物理网络连通) MULTICAST MTU:1500 Metric:1
RX(重点) packets:1744127025 errors:0 dropped:0 overruns:0 frame:0
TX(重点) packets:1726557188 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:111947366067 (104.2 GiB) TX bytes:234661860465 (218.5 GiB)
- errors 表示发生错误的数据包数,比如校验错误、帧同步错误等;
- dropped 表示丢弃的数据包数,即数据包已经收到了 Ring Buffer,但因为内存不足等原因丢包;
- overruns 表示超限数据包数,即网络 I/O 速度过快,导致 Ring Buffer 中的数据包来不及处理(队列满)而导致的丢包;
- carrier 表示发生 carrirer 错误的数据包数,比如双工模式不匹配、物理电缆出现问题等;
- collisions 表示碰撞数据包数。
⑵查看套接字信息
[work(caibin)@tjtx144-46-155 ~]$ netstat -nlp | head -n 3
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
Active Internet connections (only servers)
Proto Recv-Q(重点) Send-Q(重点) Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN -
接收队列(Recv-Q)和发送队列(Send-Q)需要你特别关注,它们通常应该是 0。当你发现它们不是 0 时,说明有网络包的堆积发生。
在不同套接字状态下,它们的含义不同:
- 当套接字处于连接状态(Established)时
- Recv-Q 表示套接字缓冲还没有被应用程序取走的字节数(即接收队列长度)
- 而 Send-Q 表示还没有被远端主机确认的字节数(即发送队列长度)
- 当套接字处于监听状态(Listening)时
- Recv-Q 表示 syn backlog 的当前值
- 而 Send-Q 表示最大的 syn backlog 值
⑶协议栈统计信息
ss 只显示已经连接、关闭、孤儿套接字等简要统计,而 netstat 则提供的是更详细的网络协议栈信息。
①简单模式
[work(caibin)@tjtx144-46-155 ~]$ ss -s //非工具
Total: 837 (kernel 0)
TCP: 21455 (estab 793, closed 20650, orphaned 3, synrecv 0, timewait 1716/0), ports 0
Transport Total IP IPv6
* 0 - -
RAW 0 0 0
UDP 18 2 16
TCP 805 15 790
INET 823 17 806
FRAG 0 0 0
②复杂模式
$ netstat -s
⑶网络吞吐和PPS
sar命令(无需安装)
# 数字 1 表示每隔 1 秒输出一组数据
$ sar -n DEV 1
[work(caibin)@tjtx144-46-155 ~]$ sar -n DEV 1
Linux 4.18.7-1.el7.elrepo.x86_64 (tjtx144-46-155.58os.org) 12/29/2019 _x86_64_ (40 CPU)
07:25:48 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
07:25:49 PM eth0 7309.78 7288.04 430.63 947.79 0.00 0.00 0.00
07:25:49 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
07:25:49 PM tunl0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
07:25:49 PM tunnat 0.00 0.00 0.00 0.00 0.00 0.00 0.00
- rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包 / 秒。
- rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。
- rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包 / 秒。
- %ifutil 是网络接口的使用率,即半双工模式下为 (rxkB/s+txkB/s)/Bandwidth,而全双工模式下为 max(rxkB/s, txkB/s)/Bandwidth。
查看网络带宽
ethtool(无需安装)
[work(caibin)@tjtx144-46-155 ~]$ ethtool eth0 | grep Speed
Cannot get wake-on-lan settings: Operation not permitted
Speed: 10000Mb/s
压测工具
sysbench 是一款开源的多线程性能测试工具,可以执行CPU/内存/线程/IO/数据库等方面的性能测试
最后
以上就是欣慰月亮最近收集整理的关于【Linux】Linux性能优化的全部内容,更多相关【Linux】Linux性能优化内容请搜索靠谱客的其他文章。








发表评论 取消回复