在看本博客前,请先看原论文:FcaNet论文
前网络设计主流思考角度:depth、width、cardinality、attention。
一、作者主要贡献
作者从频域角度重新思考通道注意力机制,数学上证明了全局平均池化是频域特征分解的一个特例;将通道注意力的预处理方法推广到频域,提出multi-spectral通道注意力,FcaNet并开源。
二、GAP存在的问题
GAP存在的问题:一个通道的特征图直接下采样为一个值,导致其不能很好的捕捉到丰富的输入特征信息(信息丢失问题),从而在处理不同的输入信息时缺乏特征多样性。
对GAP问题的分析:
- 特征图的通道有很多,不同通道的均值可能是相同的,但是他们代表的语义内容信息可能是不同的,GAP导致网络只能捕捉到该均值所代表的信息。我的理解是不同的特征图均值相同导致网络认为他们所代表的特征信息相同,无法捕捉到多样的特征信息。
- 从频域角度分析,做做证明GAP等价于离散余弦变换(DCT)的最低频。如果只使用GAP,会导致网络丢弃通道上其他频率包含的大量有用信息。
- 引用CBAM作为论据,CBAM使用全局平均池化和全局最大池化来增强特征信息的多样性。
三、解决信息丢失
使用多种但是有限的频率成分共同组成来代替单一的GAP。将输入特征图均分为多份,每一份特征图都有其对应的2D DCT频率分量(权重)。不同频率成分包含不同的信息。
对SENet进行改进,网络简图如下:
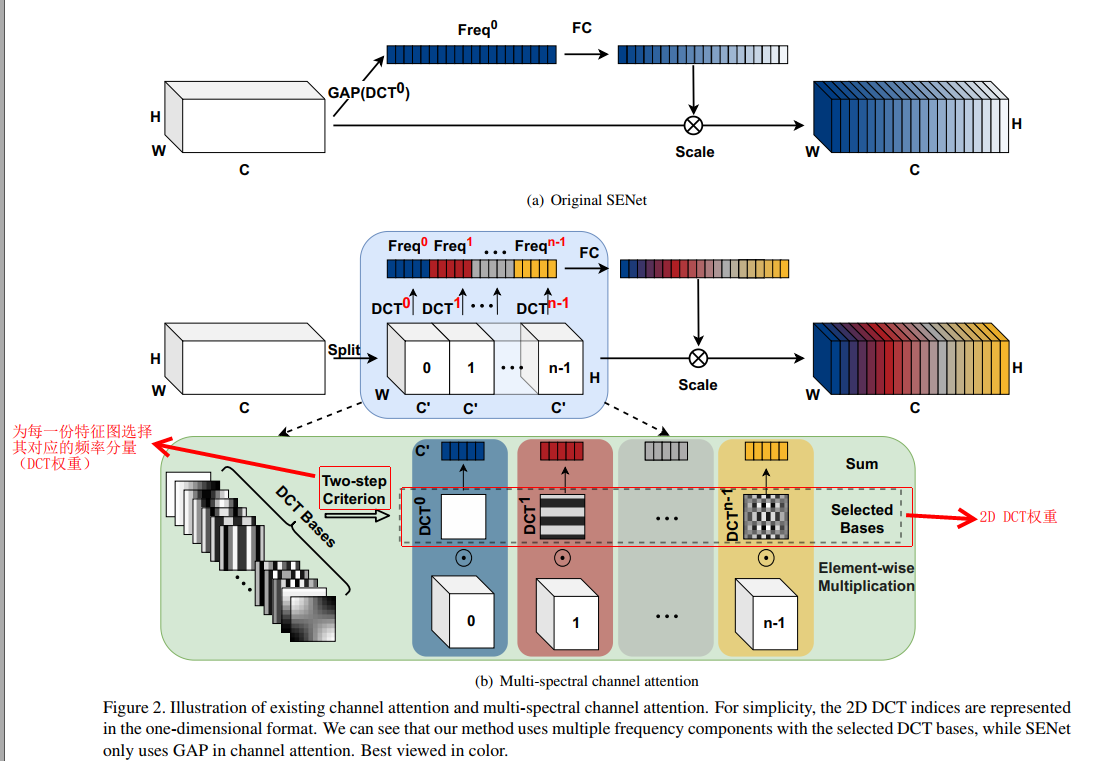
-
分析:对于输入到注意力模块的特征图x,按照DCT过滤器的个数将输入特征图均分为n组,代码默认是分为n=16组,也就是用16个DCT核分别对16组特征图进行预处理,一组里面的所有特征图都使用该组对应的一个DCT核进行处理,每个核的权重weight,预处理操作
torch.sum(x*self.weight, dim=[2, 3]),即输入x与DCT核点乘,之后在空间维度求和。其他部分和SENet一样操作。 -
获取DCT核的权重的代码:
def get_dct_filter(self, tile_size_x, tile_size_y, mapper_x, mapper_y, channel):
"""
Args:
:param tile_size_x: 过滤器的宽,等于输入特征图的宽
:param tile_size_y: 过滤器的高,等于输入特征图的高
:param mapper_x: 频率分量对应的x坐标
:param mapper_y: 频率分量对应的y坐标
:param channel: 输入特征图的通道数
:return:
"""
dct_filter = torch.zeros(channel, tile_size_x, tile_size_y)
# 创建一个和输入特征图一样形状的三维张量作为过滤器(2D DCT 权重)
c_part = channel // len(mapper_x)
# 划分为len(mapper_x)份,每一份包含c_part个通道
# 一个频率分量预处理一份特征图,共len(mapper_x)个频率分量,所以将2D DCT过滤器分为len(mapper_x)份
# 遍历过滤器,并填写过滤器的权重
for i, (u_x, u_y) in enumerate(zip(mapper_x, mapper_y)):
for t_x in range(tile_size_x):
# 遍历过滤器的x坐标
for t_y in range(tile_size_y):
# 遍历过滤器的y坐标
# 太妙了,将过滤器划分组数,而输入的特征图就不需要再划分了
# i*c_part到(i+1)*c_part的特征图为均分的特征图中的一份,i表示第i份
# 计算每一份dct_weight
dct_filter[i * c_part: (i + 1) * c_part, t_x, t_y] =
self.build_filter(t_x, u_x, tile_size_x) * self.build_filter(t_y, v_y, tile_size_y)
# t_x为过滤器的x坐标(公式7中的j),u_x为被选择的频率分量对应的x坐标(公式7中的w,即频率),tile_size_x过滤器的x轴总长度(公式7中的W)
return dct_filter
def build_filter(self, pos, freq, POS):
"""计算dct_weight,计算方法参考论文中公式7和2d-dct变换的完整公式
Args:
pos: 遍历DCT过滤器过程中,当前遍历时刻对应的过滤器坐标
freq: 被选择的频率分量的坐标
POS: 过滤器总宽/高
"""
result = math.cos(math.pi * freq * (pos + 0.5) / POS) / math.sqrt(POS)
if freq == 0:
# GAP
return result
else:
return result * math.sqrt(2)
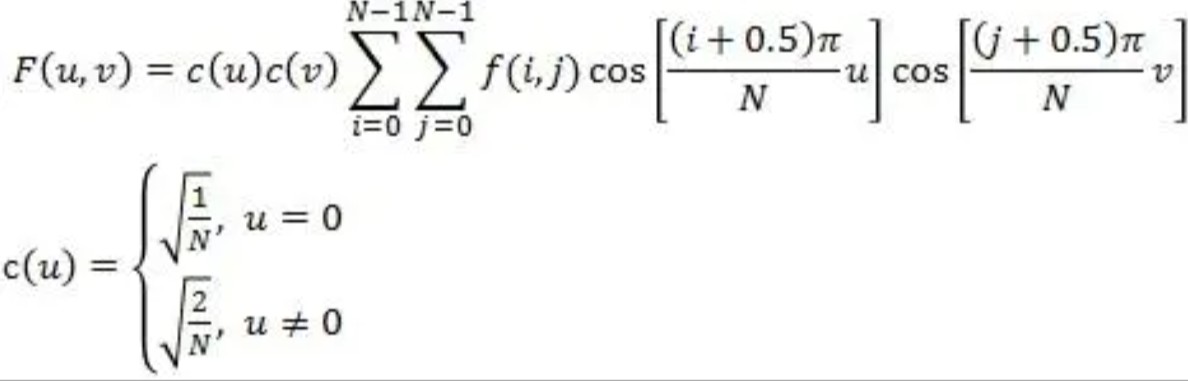
注:完整的2D DCT的核计算公式与论文中的有点差异,所以在代码实现计算2D DCT滤波器权重时,需要乘c(u)或c(v),如下
- 获取频率分量对应的索引(坐标):
# 计算频率分量的索引,通过索引获取特征图上面的频率分量,默认取16个频率分量
mapper_x, mapper_y = get_freq_indices(freq_sel_method)
# 有多少个频率分量,就将特征图均分为多少份,一份特征图用一个频率分量来进行预处理
self.num_split = len(mapper_x)
# ?这个变量有何用, 在哪里划分特征图,为每一份特征图使用对应的频率分量
# 确保获取不同分辨率特征图的频率分量时,等同于在7x7的特征图
# 比如rank3=(1,2),在56x56上面映射为坐标(8,16)对应的频率分量
mapper_x = [temp_x * (dct_h // 7) for temp_x in mapper_x]
mapper_y = [temp_y * (dct_w // 7) for temp_y in mapper_y]
def get_freq_indices(method):
assert method in ['top1', 'top2', 'top4', 'top8', 'top16', 'top32',
'bot1', 'bot2', 'bot4', 'bot8', 'bot16', 'bot32',
'low1', 'low2', 'low4', 'low8', 'low16', 'low32']
num_freq = int(method[3:])
# 选择的频率分量数
# 采用分类准确率排名前num_freq的频率分量
if 'top' in method:
# 索引根据paper实验提供,论文中图4的排名
all_top_indices_x = [0, 0, 6, 0, 0, 1, 1, 4, 5, 1, 3, 0, 0, 0, 3, 2, 4, 6, 3, 5, 5, 2, 6, 5, 5, 3, 3, 4, 2, 2,
6, 1]
all_top_indices_y = [0, 1, 0, 5, 2, 0, 2, 0, 0, 6, 0, 4, 6, 3, 5, 2, 6, 3, 3, 3, 5, 1, 1, 2, 4, 2, 1, 1, 3, 0,
5, 3]
mapper_x = all_top_indices_x[:num_freq]
mapper_y = all_top_indices_y[:num_freq]
return mapper_x, mapper_y
最后
以上就是炙热芝麻最近收集整理的关于FcaNet从频域角度重新思考CV注意力机制的全部内容,更多相关FcaNet从频域角度重新思考CV注意力机制内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复