
介绍
在我们学习机器算法的时候,可以将机器学习算法视为包含刀枪剑戟斧钺钩叉的一个军械库。你可以使用各种各样的兵器,但你要明白这些兵器是需要在合适的时间合理的地点使用它们。作为类比,你可以将“回归算法”想象成能够有效切割数据的剑,但无法处理高度复杂的数据。相反的是,“支持向量机(SVM)”就像一把锋利的刀,它比较适用于较小的数据集,但在较小的数据集上面,它可以构建更加强大的模型。
相信在你学习机器学习算法解决分类问题的时候,肯定听说过支持向量机(SVM),在过去的五十年中SVM在随着时间进行演化,并且在分类之外也得到了应用,比如回归、离散值分析、排序。我相信你在不同的途径中肯定也接触过支持向量机,是不是觉得已经对这个东西有些头痛,认为很多人都会,但是自己好像怎么都不能明白过来它的原理,或者说你已经对自己有关支持向量机的知识已经很有自信了,那么现在你来对地方了,这份技能测试就是专门测试你对于支持向量机的掌握程度已经是否可以应用。这份测试已经有超过550多人参加了,最后我会放出这些人的分数的分布情况,从而方便你对比一下自己的支持向量机的水平程度。
技能测试问题(每题1分)
问题背景:1-2
假设你使用的是一个线性SVM分类器,是用来解决存在的2分类问题。现在你已经获得了以下数据,其中一些点用红色圈起来表示支持向量。
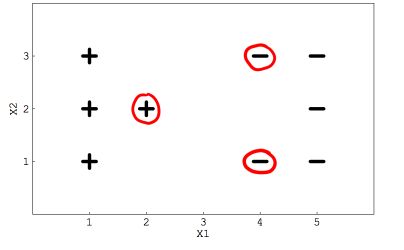
1)如果从数据中删除以下任何一个红点。决策边界会改变吗?
A)YES B)NO
2)[是或否]如果从数据中删除非红色圆圈点,决策边界会发生变化吗?
A)真 B)假
3)有关于支持向量机的泛化误差是什么意思?
A)超平面与支持向量的距离 B)支持向量机对未知数据的预测精度如何 C)支持向量机中的阈值误差量
4)当C参数设置为无穷大时,以下哪项成立?
A)如果存在最优的超平面,那么则会是完全可以分类数据 B)软边际分类器将分离数据
C)以上都不是
5)硬边缘是什么意思?
A)SVM允许分类中的误差很小 B)SVM允许分类中的误差很大 C)以上都不是
6)训练支持向量机的最小时间复杂度是O(n2)。根据这一事实,什么尺寸的数据集不是最适合SVM的?
A)大型数据集 B)小型数据集 C)中型数据集 D)大小无关紧要
7)支持向量机的有效性取决于:
A)内核的选择 B)内核的参数 C)软边距的参数C D)以上所有
8)支持向量是最接近决策边界的数据点。
A)是 B)否
9)支持向量机在以下什么情况中的效果最差:
A)数据是线性可分的 B)数据干净并且可以使用 C)数据有噪音且包含重叠点
10)假设在支持向量机中使用高Gamma值并且使用RBF内核。这意味着什么?
A)模型考虑甚至远离超平面的点进行建模 B)模型只考虑超平面附近的点进行建模 C)模型不会受到点距离超平面的影响并进行建模 D)没有以上
11)支持向量机中的代价参数表示:
A)要进行的交叉验证的数量 B)要使用的内核 C)模型的分类错误和简单性之间的权衡 D)以上都不是
12)
假设你正在基于数据X进行构建支持向量机模型。数据X可能容易出错,这意味着你不应该过多地信任任何特定的数据点。假如现在你想建立一个支持向量机模型,它的二次核函数为2次多项式,它使用松弛变量C作为它的超参数之一。基于此,请给出以下问题的答案。
当你使用非常大的C值(C->无穷大)时会发生什么?
注意:对于小C,也可以正确地对所有数据点进行分类
A)对于给定的超参数C,我们仍然可以正确的对数据进行分类 B)对于给定的超参数C,我们不能对数据进行正确的分类 C)不好说 D)以上都不是
13)当使用非常小的C值(C~0)会发生什么?
A)将会发生分类错误 B)数据将被正确的分类 C)不好说 D)以上都不是
14)如果我正在使用我的数据集的所有特征,并且我在训练集上达到100%的准确率,但在验证集上却只达到约70%,我应该注意什么?
A)欠拟合 B)没什么注意的,模型是非常完美的 C)过度拟合
15)以下哪项是支持向量机在现实世界中的实际应用?
A)文本和超文本分类 B)图像分类 C)新闻文章的聚类 D)以上所有
问题背景:16 - 18
假设你在训练支持向量机后训练了一个具有线性决策边界的支持向量机,你正确的发现了你的支持向量机的模型还不合适。
16)下面选项中哪一个是你更能考虑进行迭代支持向量机的?
A)增加你的数据点 B)减少你的数据点 C)尝试计算更多的变量 D)尝试减少变量
17)假设你在前一个问题中给出了正确的答案。你认为实际上会发生什么?
1.我们正在降低偏差 2.我们正在降低方差 3.我们正在增加偏差 4.我们正在增加方差
A)1和2 B)2和3 C)1和4 D)2和4
18)在上面的问题中,假设你想要更改其中一个(支持向量机)超参数,以便效果与之前的问题相同,也就是模型不适合?
A)我们将增加参数C B)我们将减小参数C C)C中的变化不起作用 D)这些都不是
19)在支持向量机中使用高斯核函数之前,我们通常使用特征归一化。那么什么是真正的特征归一化?
- 我们进行特征归一化时,以便新特征占主导地位
- 有时,对于分类变量,特征归一化是不可行的
- 当我们在支持向量机中使用高斯核函数时,特征归一化总是有帮助的
A)1 B)1和2 C)1和3 D)2和3
问题背景:20-22
假设你正在处理4分类问题,并且你希望在数据上训练支持向量机模型,因为你正在使用One-vs-all方法。现在回答以下问题
20)在这种情况下我们需要训练支持向量机模型多少次
A)1 B)2 C)3 D)4
21)假设你的数据中具有相同的类分布。现在,比如说在一对一训练中进行1次训练,支持向量机模型需要10秒钟。那么端到端训练一对一的方法需要多少秒?
A)20 B)40 C)60 D)80
22)假设你的问题现在已经发生了改变。现在,数据只有2个类。在这种情况下,你认为我们需要训练支持向量机多少次?
A)1 B)2 C)3 D)4
问题背景:23 - 24
假设你使用的支持向量机的线性核函数为2次多项式,现在认为你已将其应用于数据上并发现它完全符合数据,这意味着,训练和测试精度为100%。
23)现在,假设你增加了这个内核的复杂度(或者说多项式的阶数)。你认为会发生什么?
A)增加复杂性将使数据过度拟合 B)增加复杂性将使数据不适应模型 C)由于你的模型已经100%准确,因此不会发生任何事情 D)以上都不是
24)在上一个问题中,在增加复杂性之后,你发现训练精度仍然是100%。你认为这背后的原因是什么?
- 由于数据是固定的,我们拟合更多的多项式项或参数,因此算法开始记忆数据中的所有内容
- 由于数据是固定的,SVM不需要在大的假设空间中进行搜索
A)1 B)2 C)1和2 D)这些都不是
25)支持向量机中的kernel是什么?
- kernel是将低维数据映射到高维空间
- 这是一个相似函数
A)1 B)2 C)1和2 D)这些都不是
答案与讲解
1)正确答案:A
这三个例子的位置使得删除它们中的任何一个都会在约束中引入松弛效果。因此决策边界将完全改变。
2)正确答案:B
从数据另一方面来说,数据中的其余点不会对决策边界产生太大影响。
3)正确答案:B
统计中的泛化误差通常是样本外误差,它是用来衡量模型预测先见未知的数据值的准确性。
4)正确答案:A
在如此高水平的误差分类惩罚水平上,软边际将不会存在,因为没有错误的余地。
5)正确答案:A
硬边界意味着SVM在分类方面非常严格,并且试图在训练集中完美的完成分类,从而导致过度拟合。
6)正确答案:A
分类边界清晰的数据集与支持向量机的分类效果最好
7)正确答案:D
支持向量机的有效性取决于你如何选择上面提到的三个基本需求,从而最大化你的效率,减少误差和过度拟合。
8)正确答案:A
它们是最接近超平面的点,也是最难分类的点。它们还对决策边界的位置有直接影响。
9)正确答案:C
当数据具有噪声和重叠点时,如何在不分类的情况下画出清晰的超平面是一个很大的问题。
10)正确答案:B
SVM调整中的gamma参数表示超平面附近的或远离超平面的点的影响
对于较低的gamma值,模型将被过于约束并包括训练数据集中的所有的点,而不会真正的捕获形状。
对于更高的gamma值,模型将很好地捕获数据集的形状。
11)正确答案:C
代价参数决定了支持向量机被允许在多大程度上“弯曲”数据。对于低的代价参数,你的目标是一个光滑平稳的超平面,对于更高的代价,你的目标是正确地分类更多的点。它也简称为分类错误的代价。
12)正确答案:A
对于较大的C值,错误分类的点的代价非常高,因此决策边界将尽可能完美地分离数据。
13)正确答案:A
该分类器可以最大化的提高大多数点之间的边距,同时会对少数点进行错误的分类,因为代价是非常低的。
14)正确答案:C
如果我们非常容易就达到了100%的训练准确度,那么我们就需要检查来确认我们是否过度拟合了数据。
15)正确答案:D
支持向量机是高度通用的模型,可用于几乎所有现实世界的问题,从回归到聚类和手写识别。
16)正确答案:C
这里最好的选择是为模型创建尝试更多的变量。
17)正确答案:C
更好的模型将降低偏差并增加方差
18)正确答案:A
增加C参数在这里是正确的,因为它将确保模型的规范化
19)正确答案:B
表述一和二是正确的。
20)正确答案:D
对于一个4分类问题,如果使用one-vs-all方法,则必须至少训练SVM 4次。
21)正确答案:B
需要10×4 = 40秒
22)正确答案:A
仅训练一次SVM就可以得到合适的结果
23)正确答案:A
增加数据的复杂性会使算法过度拟合数据。
24)正确答案:C
两个给定的陈述都是正确的。
25)正确答案:C
两个给定的陈述都是正确的。
结果检查
是不是已经对完答案,已经算出自己的分数了呢,以下是参与者得分的总体分布,看一下自己的水平在那个位置吧:
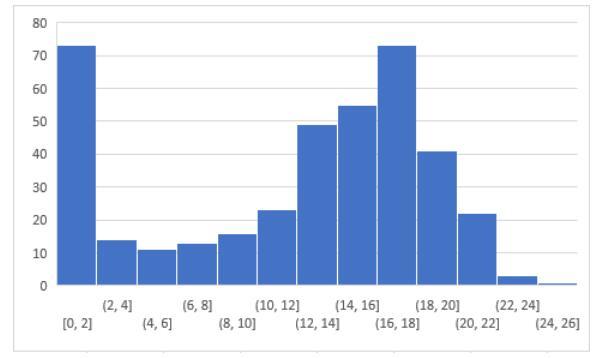
在这个图表中,列表示的得分的人数,行表示获得的分数,全部答对的人只有1位,相信看完自己的分数后,你应该对自己的水平有了一定的了解,也明白自己对于支持向量机的哪些知识还有些不足,这样我们可以更好的去学习。
25 Questions to test a Data Scientist on Support Vector Machines
最后
以上就是明理网络最近收集整理的关于25道题检测你对支持向量机算法的掌握程度的全部内容,更多相关25道题检测你对支持向量机算法内容请搜索靠谱客的其他文章。








发表评论 取消回复