Q1. 在回归模型中,下列哪一项在权衡欠拟合(under-fitting)和过拟合(over-fitting)中影响最大?
A. 多项式阶数
B. 更新权重 w 时,使用的是矩阵求逆还是梯度下降
C. 使用常数项
答案:A
解析:选择合适的多项式阶数非常重要。如果阶数过大,模型就会更加复杂,容易发生过拟合;如果阶数较小,模型就会过于简单,容易发生欠拟合。如果有对过拟合和欠拟合概念不清楚的,
Q2关于Logistic回归和SVM,以下说法错误的是?
A. Logistic回归可用于预测事件发生概率的大小
B. Logistic回归的目标函数是最小化后验概率
C. SVM的目标的结构风险最小化
D. SVM可以有效避免模型过拟合
答案:B,Logit回归本质上是一种根据样本对权值进行极大似然估计的方法,而后验概率正比于先验概率和似然函数的乘积。logit仅仅是最大化似然函数,并没有最大化后验概率,更谈不上最小化后验概率。A错误 Logit回归的输出就是样本属于正类别的几率,可以计算出概率,正确C. SVM的目标是找到使得训练数据尽可能分开且分类间隔最大的超平面,应该属于结构风险最小化. D. SVM可以通过正则化系数控制模型的复杂度,避免过拟合。
Q3在其他条件不变的前提下,以下哪种做法容易引起机器学习中的过拟合问题
A 增加训练集量
B 减少神经网络隐藏层节点数
C 删除稀疏的特征 S
D SVM算法中使用高斯核/RBF核代替线性核
正确答案:D
Q4机器学习中做特征选择时,可能用到的方法有?
A 卡方
B 信息增益
C 平均互信息
D 期望交叉熵
正确答案:A B C D
Q5在一个n维的空间中, 最好的检测outlier(离群点)的方法是:
A. 作正态分布概率图
B. 作盒形图
C. 马氏距离
D. 作散点图
答案:C
马氏距离是基于卡方分布的,度量多元outlier离群点的统计方法。
Q6对数几率回归(logistics regression)和一般回归分析有什么区别?:
A. 对数几率回归是设计用来预测事件可能性的
B. 对数几率回归可以用来度量模型拟合程度
C. 对数几率回归可以用来估计回归系数
D. 以上所有
答案:D
Q7bootstrap数据是什么意思?(提示:考“bootstrap”和“boosting”区别)
A. 有放回地从总共M个特征中抽样m个特征
B. 无放回地从总共M个特征中抽样m个特征
C. 有放回地从总共N个样本中抽样n个样本
D. 无放回地从总共N个样本中抽样n个样本
答案:C
Q8如果SVM模型欠拟合, 以下方法哪些可以改进模型 :
A. 增大惩罚参数C的值
B. 减小惩罚参数C的值
C. 减小核系数(gamma参数)
答案: A
如果SVM模型欠拟合, 我们可以调高参数C的值, 使得模型复杂度上升.
Q9我们想在大数据集上训练决策树, 为了使用较少时间, 我们可以 :
A. 增加树的深度
B. 增加学习率 (learning rate)
C. 减少树的深度
D. 减少树的数量
答案: C
增加树的深度, 会导致所有节点不断分裂, 直到叶子节点是纯的为止. 所以, 增加深度, 会延长训练时间.
Q10假如我们使用非线性可分的SVM目标函数作为最优化对象, 我们怎么保证模型线性可分 :
A. 设C=1
B. 设C=0
C. 设C=无穷大
D. 以上都不对
答案: C
C无穷大保证了所有的线性不可分都是可以忍受的.常数C决定了松弛变量之和的影响程度,如果越大,影响越严重,那么在优化的时候会更多的注重所有点到分界面的距离,
Q11在有监督学习中, 我们如何使用聚类方法? :
A. 我们可以先创建聚类类别, 然后在每个类别上用监督学习分别进行学习
B. 我们可以使用聚类“类别id”作为一个新的特征项, 然后再用监督学习分别进行学习
C. 在进行监督学习之前, 我们不能新建聚类类别
D. 我们不可以使用聚类“类别id”作为一个新的特征项, 然后再用监督学习分别进行学习
答案: AB
我们可以为每个聚类构建不同的模型, 提高预测准确率。
“类别id”作为一个特征项去训练, 可以有效地总结了数据特征。
Q12下面的交叉验证方法 :
i. 有放回的Bootstrap方法
ii. 留一个测试样本的交叉验证
iii. 5折交叉验证
iv. 重复两次的5折教程验证
当样本是1000时,下面执行时间的顺序,正确的是:
A. i > ii > iii > iv
B. ii > iv > iii > i
C. iv > i > ii > iii
D. ii > iii > iv > i
答案: B
Boostrap方法是传统地随机抽样,验证一次的验证方法,只需要训练1次模型,所以时间最少。
留一个测试样本的交叉验证,需要n次训练过程(n是样本个数),这里,要训练1000个模型。
5折交叉验证需要训练5个模型。重复2次的5折交叉验证,需要训练10个模型。
Q13关于主成分分析PCA说法正确的是:
A 我们必须在使用PCA前规范化数据
B 我们应该选择使得模型有最大variance的主成分
C 我们应该选择使得模型有最小variance的主成分
D我们可以使用PCA在低纬度上做数据可视化
答案: ABD
PCA对数据尺度很敏感, 打个比方, 如果单位是从km变为cm, 这样的数据尺度对PCA最后的结果可能很有影响(从不怎么重要的成分变为很重要的成分).
我们总是应该选择使得模型有最大variance的主成分
有时在低维度上左图是需要PCA的降维帮助的
Q14以下描述错误的是?
A SVM是这样一个分类器,他寻找具有最小边缘的超平面,因此它也经常被称为最小边缘分类器(minimal margin classifier)
B 在聚类分析中,簇内的相似性越大,簇间的差别越大,聚类的效果越好
C 在决策树中,随着树中节点变得太大,即使模型的训练误差还在继续减低,但是检验误差开始增大,这是出现了模型拟合不足的问题
D 聚类分析可以看做是一种非监督的分类
答案:AC
解析:A. SVM的策略是最大间隔分类器。
B. 簇内的相似性越大,簇间的差别越大,聚类的效果就越好
C. 训练误差减少与测试误差逐渐增大,是明显的过拟合的特征。
Q15以下说法中正确的是() 机器学习 ML模型 中
A.SVM对噪声(如来自其他分布的噪声样本)鲁棒
B.在AdaBoost算法中,所有被分错的样本的权重更新比例相同
C.Boosting和Bagging都是组合多个分类器投票的方法,二都是根据单个分类器的正确率决定其权重
D.给定n个数据点,如果其中一半用于训练,一般用于测试,则训练误差和测试误差之间的差别会随着n的增加而减少
正确答案:BD
A、SVM本身对噪声具有一定的鲁棒性,但实验证明,是当噪声率低于一定水平的噪声对SVM没有太大影响,但随着噪声率的不断增加,分类器的识别率会降低。
B、AdaBoost算法中不同的训练集是通过调整每个样本对应的权重来实现的。开始时,每个样本对应的权重是相同的,即其中n为样本个数,在此样本分布下训练出一弱分类器。对于分类错误的样本,加大其对应的权重;而对于分类正确的样本,降低其权重,这样分错的样本就被凸显出来,从而得到一个新的样本分布。在新的样本分布下,再次对样本进行训练,得到弱分类器。以此类推,将所有的弱分类器重叠加起来,得到强分类器。
C、Bagging与Boosting的区别:
取样方式不同。
Bagging采用均匀取样,而Boosting根据错误率取样。
Bagging的各个预测函数没有权重,而Boosting是有权重的。
Bagging的各个预测函数可以并行生成,而Boosing的各个预测函数只能顺序生成。
A. SVM解决的是结构风险最小, 经验风险处理较弱, 所以对数据噪声敏感.
B. AdaBoost算法中, 每个迭代训练一个学习器并按其误分类率得到该学习器的权重alpha, 这个学习器的权重算出两个更新比例去修正全部样本的权重: 正样本是exp(-alpha), 负样本是exp(alpha). 所以所有被分错的样本的权重更新比例相同.
C. bagging的学习器之间无权重不同, 简单取投票结果; Boosting的adaboost根据误分类率决定权重, boosting的gbdt则是固定小权重(也称学习率), 用逼近伪残差函数本身代替权重.
D: 根据中心极限定律, 随着n的增加, 训练误差和测试误差之间的差别必然减少 – 这就是大数据训练的由来
————————————————
Q16. K-Means 算法无法聚以下哪种形状的样本?
A. 圆形分布
B. 螺旋分布
C. 带状分布
D. 凸多边形分布
答案:B
解析:K-Means 算法是基于距离测量的,无法聚非凸形状的样本。
Q17. 向量 X=[1,2,3,4,-9,0] 的 L1 范数为?
A. 1
B. 19
C. 6
D. √111
答案:B
解析:L0 范数表示向量中所有非零元素的个数;L1 范数指的是向量中各元素的绝对值之和,又称“稀疏矩阵算子”;L2 范数指的是向量中各元素的平方和再求平方根。
本例中,L0 范数为 5,L1 范数为 19,L2 范数为 √111。
————————————————
Q18以下哪些方法不可以直接来对文本分类?
A. K-Means
B. 决策树
C. 支持向量机
D. kNN
答案:A
解析:K-Means 是无监督算法,它之所以不能称为分类是因为它之前并没有类别标签,因此只能聚类。
Q19下面这张图是一个简单的线性回归模型,图中标注了每个样本点预测值与真实值的残差。计算 SSE 为多少?
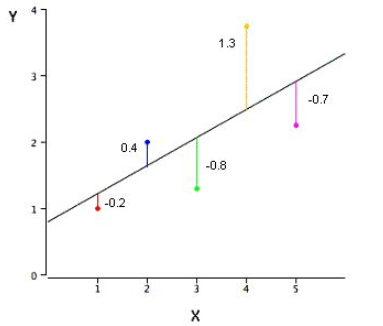
A. 3.02
B. 0.75
C. 1.01
D. 0.604
答案:A
解析:SSE 是平方误差之和(Sum of Squared Error),SSE = (-0.2)^2 + (0.4)^2 + (-0.8)^2 + (1.3)^2 + (-0.7)^2 = 3.02
Q20. 关于 k 折交叉验证,下列说法正确的是?
A. k 值并不是越大越好,k 值过大,会降低运算速度
B. 选择更大的 k 值,会让偏差更小,因为 k 值越大,训练集越接近整个训练样本
C. 选择合适的 k 值,能减小验方差
D. 以上说法都正确
答案: D
解析:机器学习中,在样本量不充足的情况下,为了充分利用数据集对算法效果进行测试,将数据集随机分为 k 个包,每次将其中一个包作为测试集,剩下 k-1 个包作为训练集进行训练。
k 折交叉验证的的 k 值不能太大,也不能太小。k 值过大,会降低运算速度。若 k 与样本数量 N 相同,则是留一法(Leave-One-Out)。k 值较大,训练集越接近整个训练样本,有利于减小模型偏差(bias)。一般可以将 k 作为超参数调试,根据表现选择合适的 k 值。
k 折交叉验证能够有效提高模型的学习能力,类似于增加了训练样本数量,使得学习的模型更加稳健,鲁棒性更强。选择合适的 k 值能够有效避免过拟合。
Q21、我们知道二元分类的输出是概率值。一般设定输出概率大于或等于 0.5,则预测为正类;若输出概率小于 0.5,则预测为负类。那么,如果将阈值 0.5 提高,例如 0.6,大于或等于 0.6 的才预测为正类。则准确率(Precision)和召回率(Recall)会发生什么变化(多选)?
A. 准确率(Precision)增加或者不变
B. 准确率(Precision)减小
C. 召回率(Recall)减小或者不变
D. 召回率(Recall)增大
答案:AC
解析:本题考察的是二元分类阈值提高对准确率和召回率的影响。
首先来看一下什么是准确率和召回率,下面分别用 P 和 R 代表。以一个简单的例子来说明,例如预测 20 个西瓜中哪些是好瓜,这 20 个西瓜中实际有 15 个好瓜,5 个坏瓜。某个模型预测的结果是:16 个好瓜,4 个坏瓜。其中,预测的 16 个好瓜中有 14 个确实是好瓜,预测的 4 个坏瓜中有 3 个确实是坏瓜。下面以一张图表说明:

这样,准确率 P 的定义是:
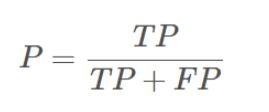
可以理解为预测好瓜中,确实是好瓜的比例。该例子中 P = 14/(14+2)。
召回率 R 的定义是:
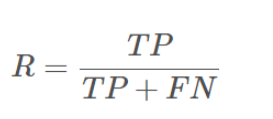
可以理解为真实的好瓜被预测出来的比例。该例子中 R = 14/(14+1)。
现在,如果二元分类阈值提高,相当于判定好瓜的标准更严格了。所以可能会造成预测是好瓜的数目减少,即 TP 和 FP 均减小。因此准确率可能会增加,极端的,苛刻条件,只预测一个是好瓜,那该瓜是好瓜的概率会很大,即准确率很高。但是 15 个好瓜你只挑出来 1 个,召回率就降低了。
Q22. 下面有关分类算法的准确率,召回率,F1 值的描述,错误的是?
A.准确率是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率
B.召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率
C.正确率、召回率和 F 值取值都在 0 和 1 之间,数值越接近 0,查准率或查全率就越高
D.为了解决准确率和召回率冲突问题,引入了F1分数
答案:C
解析
F1值定义为: F1 = 2PR / (P + R)
精准率和召回率和 F1 取值都在 0 和 1 之间,精准率和召回率高,F1 值也会高,不存在数值越接近 0 越高的说法,应该是数值越接近 1 越高。
最后
以上就是甜美小熊猫最近收集整理的关于机器学习复习模拟题的全部内容,更多相关机器学习复习模拟题内容请搜索靠谱客的其他文章。








发表评论 取消回复