我在项目中应用的SVM库是国立台湾大学林智仁教授开发的一套开源软件,主要有LIBSVM与LIBLINEAR两个,LIBSVM是对非线性数据进行分类,大家也比较熟悉,LIBLINEAR是对线性数据进行分类,时间复杂度较之LIBSVM要低得多,而且运用于嵌入式领域的话产生的训练集占用芯片内存也要少得多,所以如果需要分类的数据有比较好的区分度的话,推荐使用LIBLINEAR。
LIBLINEAR主要解决大规模数据分类,先来看一下前几章提到的最优间隔分类器模型:
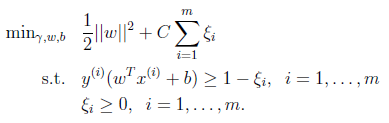
基于上面的模型,LIBLINEAR提供了8种分类方法和3中回归方法,而且能够任意的设置,优化参数。下面是源码中对LIBLINEAR的功能介绍:
1 void exit_with_help() 2 { 3 printf( 4 "Usage: train [options] training_set_file [model_file]n" 5 "options:n" 6 "-s type : set type of solver (default 1)n" 7 " for multi-class classificationn" 8 " 0 -- L2-regularized logistic regression (primal)n" 9 " 1 -- L2-regularized L2-loss support vector classification (dual)n" 10 " 2 -- L2-regularized L2-loss support vector classification (primal)n" 11 " 3 -- L2-regularized L1-loss support vector classification (dual)n" 12 " 4 -- support vector classification by Crammer and Singern" 13 " 5 -- L1-regularized L2-loss support vector classificationn" 14 " 6 -- L1-regularized logistic regressionn" 15 " 7 -- L2-regularized logistic regression (dual)n" 16 " for regressionn" 17 " 11 -- L2-regularized L2-loss support vector regression (primal)n" 18 " 12 -- L2-regularized L2-loss support vector regression (dual)n" 19 " 13 -- L2-regularized L1-loss support vector regression (dual)n" 20 "-c cost : set the parameter C (default 1)n" 21 "-p epsilon : set the epsilon in loss function of SVR (default 0.1)n" 22 "-e epsilon : set tolerance of termination criterionn" 23 " -s 0 and 2n" 24 " |f'(w)|_2 <= eps*min(pos,neg)/l*|f'(w0)|_2,n" 25 " where f is the primal function and pos/neg are # ofn" 26 " positive/negative data (default 0.01)n" 27 " -s 11n" 28 " |f'(w)|_2 <= eps*|f'(w0)|_2 (default 0.001)n" 29 " -s 1, 3, 4, and 7n" 30 " Dual maximal violation <= eps; similar to libsvm (default 0.1)n" 31 " -s 5 and 6n" 32 " |f'(w)|_1 <= eps*min(pos,neg)/l*|f'(w0)|_1,n" 33 " where f is the primal function (default 0.01)n" 34 " -s 12 and 13n" 35 " |f'(alpha)|_1 <= eps |f'(alpha0)|,n" 36 " where f is the dual function (default 0.1)n" 37 "-B bias : if bias >= 0, instance x becomes [x; bias]; if < 0, no bias term added (default -1)n" 38 "-wi weight: weights adjust the parameter C of different classes (see README for details)n" 39 "-v n: n-fold cross validation moden" 40 "-q : quiet mode (no outputs)n" 41 ); 42 exit(1); 43 }
库的实现主要在linear.cpp这个文件中,其中train()函数负责训练数据得出相应的model,predict()函数负责预判未知的输入数据。具体的使用帮助请参考软件包中的README文件。我在项目中使用的训练方法主要是坐标下降法,下面就是坐标下降法 的主要原理和应用。
L2-regularized L1- and L2-loss Support Vector Classification(dual)
L2-regularized L1-loss support vector classification (dual)的最优化模型:
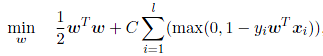
L2-regularized L2-loss support vector classification (dual)的最后化模型:
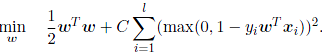
他们的对偶形式都是
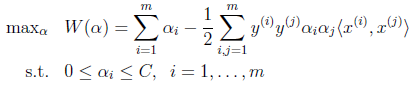
下面讨论的求解过程以L1 SVC为准,L1与L2的泛化能力差不多,而训练时间一般L2要快些。
在求解这个方程之前我们先来了解一下坐标下降法(上述对偶形式的求解方法)。
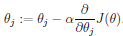
J(θ)以线性回归的例子来定义:
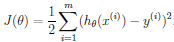
这里的α是叫做学习速度(learning rate), 它决定了坐标下降的幅度大小,假设在只有一个训练样本的情况下对J(θ)求偏导并代入上式:
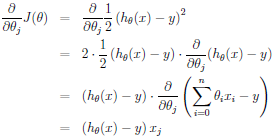
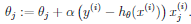
Θ的大小与误差偏移(y-h(x))成比例,也就是说如果遇上一个与实际值相近的预测值,则我们几乎不需要对θ做改变,相反,如遇到差距比较大的值,则要对θ做一定的调整。
现在再回到先前提到的对偶问题
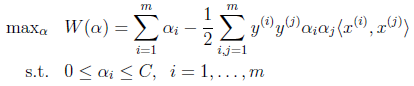
为方便起见,我们把式子改写成:
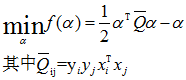
对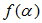 关于
关于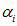 求导得
求导得
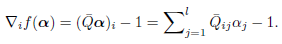
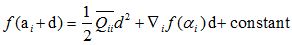
当d=0,即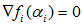 时收敛,也就是说
时收敛,也就是说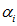 达到最优值,在先前SVM原理简介中提到
达到最优值,在先前SVM原理简介中提到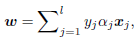 ,带入到
,带入到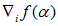 中得到:
中得到: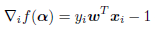 。在更新α的同时我们也需要更新w:
。在更新α的同时我们也需要更新w: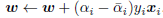 ,其中
,其中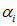 是更新后的值,
是更新后的值,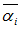 是更新前的值,
是更新前的值,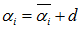 ,两个值的差值d可以对上面的
,两个值的差值d可以对上面的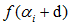 关于d求导得到 :
关于d求导得到 :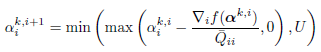 ,可能写的比较乱,下面列出整个流程的伪代码来理清思路。
,可能写的比较乱,下面列出整个流程的伪代码来理清思路。

贴出LIBLINEAR源码中使用坐标下降法的核心代码
1 if(fabs(PG) > 1.0e-12) 2 { 3 double alpha_old = alpha[i]; 4 alpha[i] = min(max(alpha[i] - G/QD[i], 0.0), C); 5 d = (alpha[i] - alpha_old)*yi; 6 xi = prob->x[i]; 7 while (xi->index != -1) 8 { 9 w[xi->index-1] += d*xi->value; 10 xi++; 11 } 12 }
至于LIBLINEAR用到的其他方法(比如牛顿法)由于空余时间有限,也因为我在项目中用到的SVM对于训练时间没有太多要求,等有时间再来好好研究一下。一般来讲牛顿法比坐标下降法收敛的迭代次数要少得多,牛顿法要用到Hesse矩阵,所以每次迭代的运算量将会更大,但总的来说使用牛顿法所消耗的训练时间还是要比坐标下降法快得多,特别在特征量比较少的时候。
下面再来看predict,LIBLINEAR在训练时求出来的实际上就是个超平面,在预测时只要判断未知点在超平面的里面还是外面就可以完成判断,是常数级别的时间复杂度。因为我使用的SVM应用于嵌入式领域,使用核函数的SVM对于我来说太慢了,而LIBLINEAR刚好符合我的要求,在实际使用时我选取的是6个特征量,在cortex-m3中平均0.25ms就可以完成一次预测。下面是predict的源码。
1 double predict_values(const struct model *model_, const struct feature_node *x, double *dec_values) 2 { 3 int idx; 4 int n; 5 if(model_->bias>=0) 6 n=model_->nr_feature+1; 7 else 8 n=model_->nr_feature; 9 double *w=model_->w; 10 int nr_class=model_->nr_class; 11 int i; 12 int nr_w; 13 if(nr_class==2 && model_->param.solver_type != MCSVM_CS) 14 nr_w = 1; 15 else 16 nr_w = nr_class; 17 18 const feature_node *lx=x; 19 for(i=0;i<nr_w;i++) 20 dec_values[i] = 0; 21 for(; (idx=lx->index)!=-1; lx++) 22 { 23 // the dimension of testing data may exceed that of training 24 if(idx<=n) 25 for(i=0;i<nr_w;i++) 26 dec_values[i] += w[(idx-1)*nr_w+i]*lx->value; 27 } 28 29 if(nr_class==2) 30 { 31 if(model_->param.solver_type == L2R_L2LOSS_SVR || 32 model_->param.solver_type == L2R_L1LOSS_SVR_DUAL || 33 model_->param.solver_type == L2R_L2LOSS_SVR_DUAL) 34 return dec_values[0]; 35 else 36 return (dec_values[0]>0)?model_->label[0]:model_->label[1]; 37 } 38 else 39 { 40 int dec_max_idx = 0; 41 for(i=1;i<nr_class;i++) 42 { 43 if(dec_values[i] > dec_values[dec_max_idx]) 44 dec_max_idx = i; 45 } 46 return model_->label[dec_max_idx]; 47 } 48 }
对于惩罚因子C的优化问题,可以借助LIBSVM中grid.py这个工具,它使用交叉验证来选出预测精度最高的那个参数,如果同时优化两个参数(RBF kernel中的c和g),它可以借助gnuplot画出等高线来帮助我们直观的了解整个优化的过程,当然可以根据你自己的需要来修改grid.py来优化你想要的参数,非常有用的小工具。
Usage: grid.py [grid_options] [svm_options] dataset grid_options : -log2c {begin,end,step | "null"} : set the range of c (default -5,15,2) begin,end,step -- c_range = 2^{begin,...,begin+k*step,...,end} "null" -- do not grid with c -log2g {begin,end,step | "null"} : set the range of g (default 3,-15,-2) begin,end,step -- g_range = 2^{begin,...,begin+k*step,...,end} "null" -- do not grid with g -v n : n-fold cross validation (default 5) -svmtrain pathname : set svm executable path and name -gnuplot {pathname | "null"} : pathname -- set gnuplot executable path and name "null" -- do not plot -out {pathname | "null"} : (default dataset.out) pathname -- set output file path and name "null" -- do not output file -png pathname : set graphic output file path and name (default dataset.png) -resume [pathname] : resume the grid task using an existing output file (default pathname is dataset.out) This is experimental. Try this option only if some parameters have been checked for the SAME data.
转载于:https://www.cnblogs.com/loujiayu/p/3500934.html
最后
以上就是紧张大侠最近收集整理的关于SVM应用 L2-regularized L1- and L2-loss Support Vector Classification(dual)的全部内容,更多相关SVM应用 L2-regularized内容请搜索靠谱客的其他文章。








发表评论 取消回复