前言
上一篇我们已经将大数据集群的三台虚拟机搭建完成 接下来我们要对虚拟机进行相关设置已满足我们集群需求
一 通过xmanager连接到我们的虚拟机上
通过 xmanager 连接到 Linux 虚拟机上
二 开始配置环境(由于我的虚拟机是一张白纸 所以我们需要安装一些必要的工具) 需要连接外网
1. 安装 gcc-c++
yum install -y gcc-c++2. 安装 vim
yum install -y vim3. 安装wget
yum install -y wget4. 更改主机名 (每台机器都要做)
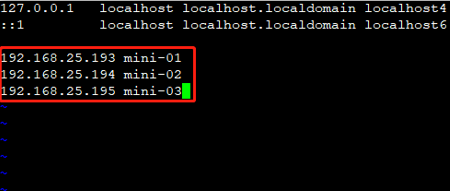
vim /etc/hosts
在文件末尾加入IP和域名的映射 如下图
5. 配置完IP和域名的映射要对虚拟机进行重启让其生效 重启后效果如下图 @后面已变为 mini-01 证明IP域名映射配置成功,如果不是证明配置失败

6. 重启完成以后 配置SSH免密登录 (每台机器都要做)命令如下
① cd ~
② ssh-keygen (连续敲3下回车)
③ ssh-copy-id mini-01 根据提示输入的密码(密码是目标机器的密码,此处 mini-01即IP与域名的映射)
这个命令要执行三次(三台机器都要做)
ssh-copy-id mini-01ssh-copy-id mini-02ssh-copy-id mini-03测试SSH免密是否已生效
scp -r /usr/local/apps/jdk mini-02:/usr/local/apps/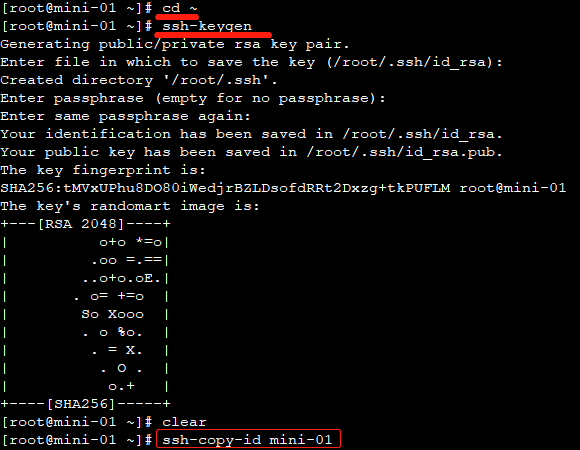
7. 上传解压Jdk压缩包 点击xmanager 新建文件传输 (下图绿色图标)
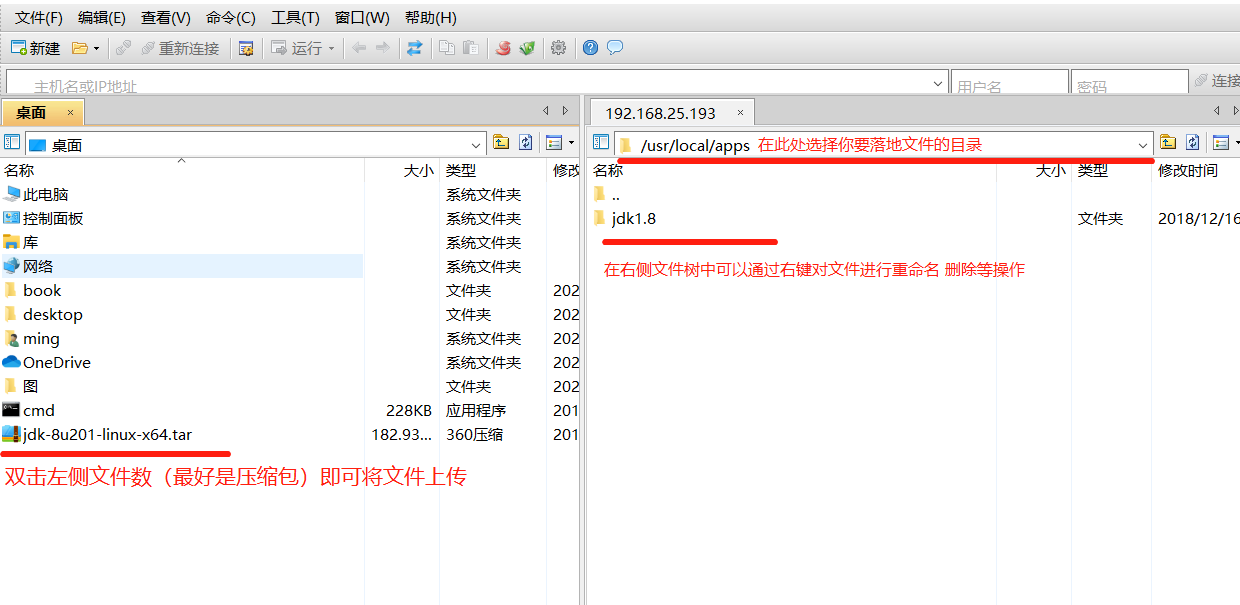
出现如下界面 按照图中文字提示即可上传文件
如果没有Linux版Jdk8 请去如下地址提取
百度云链接 提取码 3f9b
① 将Jdk压缩包上传到指定目录 (我的习惯是在/usr/local/ 下创建一个apps文件夹 把所有软件都放在这里)
cd /usr/local
mkdir apps② 解压Jdk压缩包
tar -zxvf jdk-8u201-linux-x64.tar.gz③ 为Jdk重命名
mv jdk1.8.0_201/ jdk1.8④ 将Jdk安装包分发到其他两台机器
scp -r /usr/local/apps/jdk1.8 mini-02:/usr/local/apps
scp -r /usr/local/apps/jdk1.8 mini-03:/usr/local/apps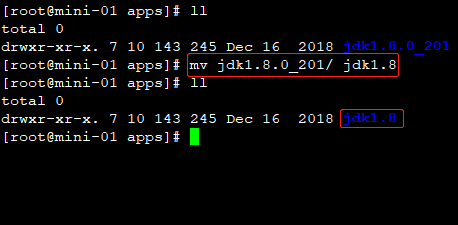
⑤ 配置Java环境变量 直接复制下面代码片段 粘贴在 /etc/profile 文件末尾即可 三台机器都要配置
vim /etc/profile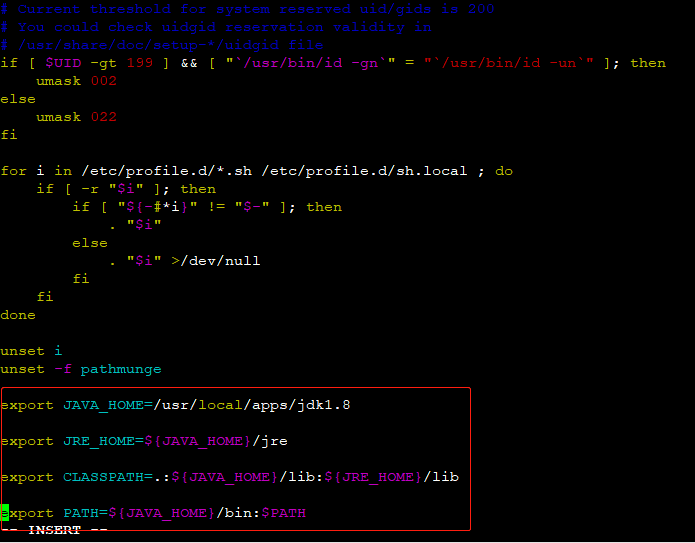
export JAVA_HOME=/usr/local/apps/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH⑥ 最后要source一下 确保文件生效
source /etc/profile然后使用命令 javac 查看Jdk是否配置完成 出现如下图所示证明配置成功

安装并配置hadoop(注意:这里我们先在第一台机器上做配置 然后再用SSH将其分发到其他机器上)
1. 将编译好的hadoop-2.7.5上传到 /usr/loacl/apps 目录下
hadoop源码编译很漫长切容易出错 感兴趣的同学可以自己编译一下 这里我已经编译好了 如果需要后续会写一篇编译hadoop源码的文章 已经编译好的hadoop-2.7.5去如下地址提取
百度网盘链接 提取码 5se4
2. 在当前目录执行解压命令
tar -zxvf hadoop-2.7.5.tar.gz3. 配置hadoop 环境变量 修改 /etc/profile 文件如下
export JAVA_HOME=/usr/local/apps/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/usr/local/apps/hadoop-2.7.5
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH同样也要 source 一下使配置文件生效
source /etc/profile4. 配置 hadoop-env.sh 的Java环境变量
cd /usr/local/apps/hadoop-2.7.5/etc/hadoop通过 editplus 连接到linux虚拟机上
set JAVA_HOME=/usr/local/apps/jdk1.8
5. 修改 core-site.xml 目录同上
cd /usr/local/apps/hadoop-2.7.5/etc/hadoop修改 core-site.xml 相关配置 注意! 拷贝的时候一定要把中文注释去掉 要不格式化hadoop的时候会报错
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定集群的文件系统类型 分布式文件系统 -->
<property>
<name>fs.default.name</name>
<value>hdfs://mini-01:8020</value>
</property>
<!-- 指定临时文件存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/apps/hadoop-2.7.5/hadoopDatas/tempDatas</value>
</property>
<!-- 缓冲区大小 实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制 删除掉的数据可以从垃圾桶中回收 单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
6. hdfs-site.xml 目录同上
cd /usr/local/apps/hadoop-2.7.5/etc/hadoop<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>mini-01:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>mini-01:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/apps/hadoop-2.7.5/hadoopDatas/namenodeDatas,file:///usr/local/apps/hadoop-2.7.5/hadoopDatas/namenodeDatas2</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/apps/hadoop-2.7.5/hadoopDatas/datanodeDatas,file:///usr/local/apps/hadoop-2.7.5/hadoopDatas/datanodeDatas2</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///usr/local/apps/hadoop-2.7.5/hadoopDatas/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///usr/local/apps/hadoop-2.7.5/hadoopDatas/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///usr/local/apps/hadoop-2.7.5/hadoopDatas/dfs/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
7. mapred-site.xml 目录同上
cd /usr/local/apps/hadoop-2.7.5/etc/hadoopmapred-site.xml 不存在 只有一个 .template文件 需要将此文件重命名
mv mapred-site.xml.template mapred-site.xml
修改内容代码如下
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>mini-01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>mini-01:19888</value>
</property>
</configuration>
8. yarn-site.xml 目录同上
cd /usr/local/apps/hadoop-2.7.5/etc/hadoop修改内容如下
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>mini-01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
</configuration>
将配置好的hadoop安装包分发到其他两台机器
scp -r /usr/local/apps/hadoop-2.7.5 mini-02:/usr/local/apps
scp -r /usr/local/apps/hadoop-2.7.5 mini-03:/usr/local/apps注意!更改以上任何一个文件都不允许出现中文,否则在hdfs格式化的时候会报错
配置完成以后 请将更改后的hadoop-2.7.5 分发到其他机器上
9. 格化式hadoop 集群中每台机器都要做
hdfs namenode -format 出现如下提示证明格式化成功
Storage directory ... hadoop-2.7.5/tmp/dfs/has been successfully formatted至此 我们的大数据平台已经搭建完成 让我们启动一下
启动分布式大数据平台
1. 首先我们要关闭防火墙
关闭防火墙 (每台机器都要做)
systemctl stop firewalld2. 进入hadoop安装的sbin目录下
cd /usr/local/apps/hadoop-2.7.5/sbin/mini-01 (主节点 master)执行如下名命令
./start-dfs.sh
./start-yarn.sh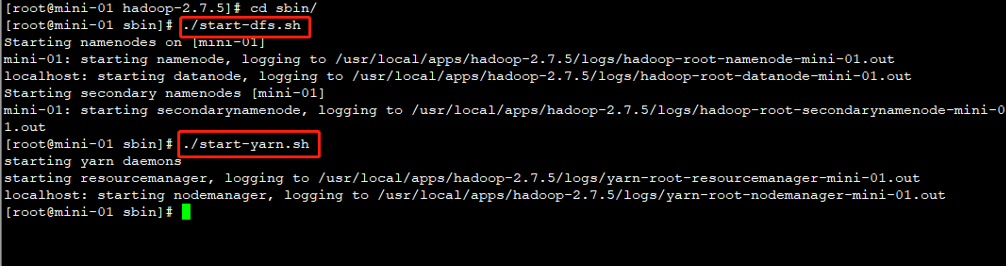
3. mini-02 mini-03(从节点 slave)
./hadoop-daemon.sh start datanode
4. 通过浏览器访问 192.168.25.193:50070 出现如下界面证明大数据平台启动成功
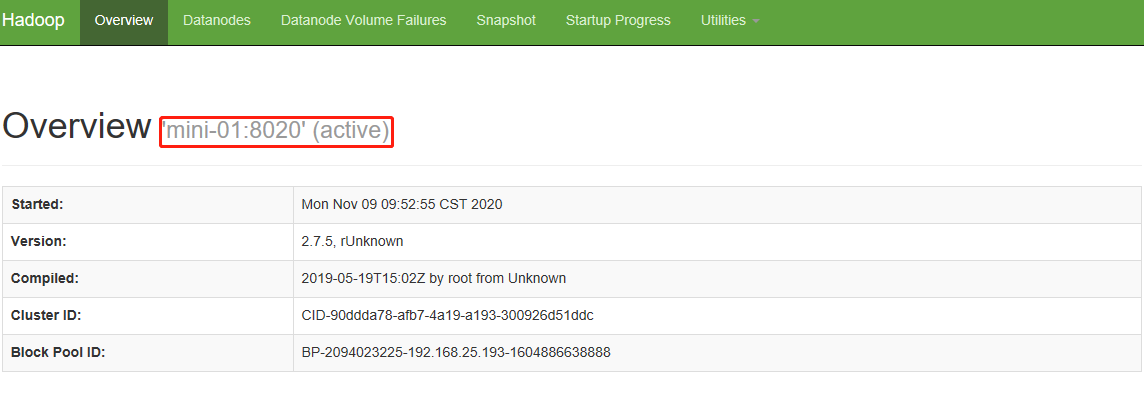
5. 查看存活节点 如果是三个 证明我们的机器运行均正常
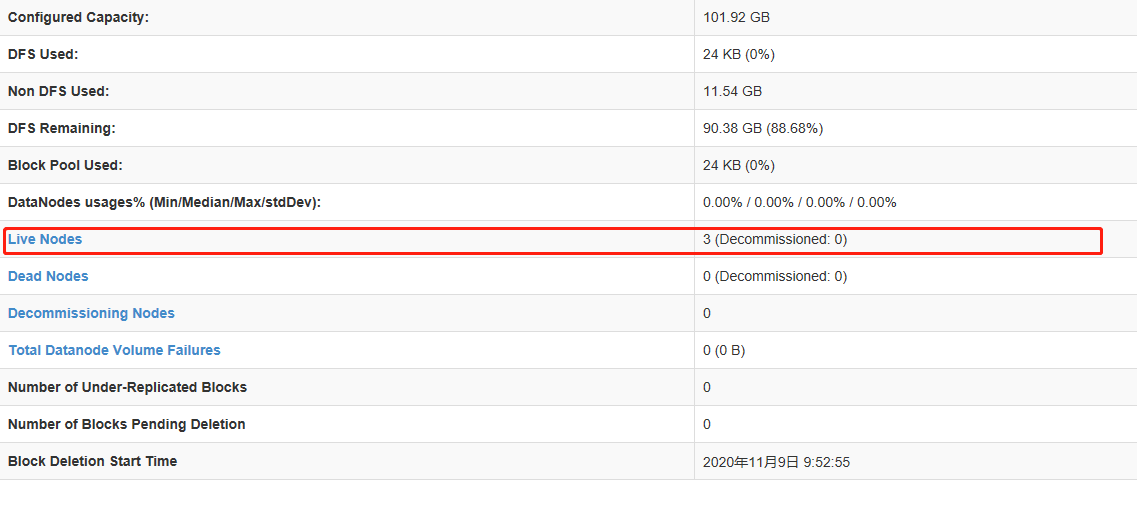
以上~感谢!
最后
以上就是甜蜜网络最近收集整理的关于【Hadoop】 No.2 搭建大数据分布式集群的全部内容,更多相关【Hadoop】内容请搜索靠谱客的其他文章。








发表评论 取消回复