第一次写博客不习惯用markdown。今后习惯了应该会好些吧。今后的研究方向就固定在知识图谱这块了。最近在学习其他大佬们构建的图谱,首先把我学到的东西分享一下吧。顺便构建一个简单的电影领域的知识图谱。
今天首先介绍MySQL和Neo4j.
MySQL
MySQ简介和安装
MySQL是一种关系型数据库[RDBMS]。官网:https://www.mysql.com/。
MySQL 和navicat[一个数据库管理工具]详细的安装步骤我是参考这位博主的:
MySQL 8.0.15安装教程(windows 64位)
数据是编写爬虫从百科中爬取,具体做法先不做介绍直接上sql文件将其导入mysql数据库中即可。
电影数据导入和CSV 转换
把data 中的kg_movie.sql文件直接拖到navicat中。数据见我的gayhub:
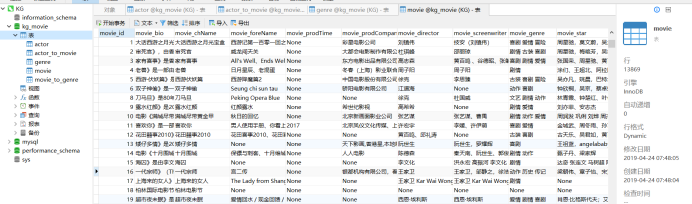
结果显示:一共五张表
- actor : 演员表 描述演员信息 包括生日、简介、国籍等
- movie : 电影表 包含电影名、上映时间、类型、演员等
- genre : 电影类型
- actor_to_movie : 演员和电影的映射表 【用于表示关系】
- movie_to_genre:电影和类型和映射表 【用于表示关系】
导入完毕。
接着把每张表转换为csv文件之后导入neo4j时会使用。具体做法很简单:
- 任意选择一张表,右键 先择导出向导见下图
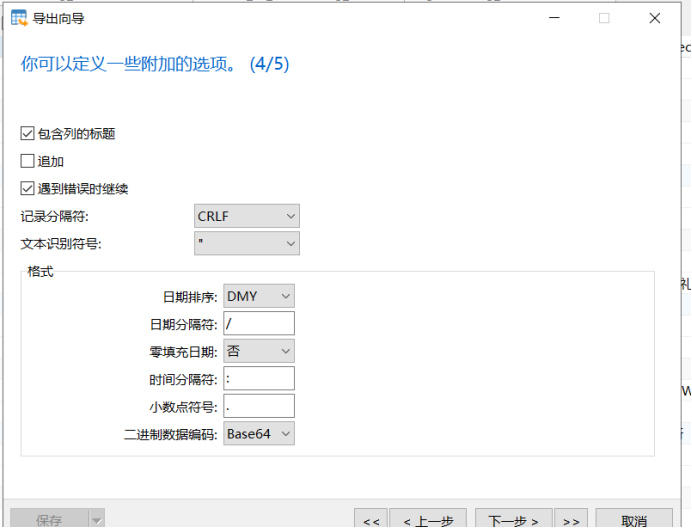
这里可以选择包含列标题 也就是数据库中的字段啦。
之后就可以看到桌面上有五张csv表格。
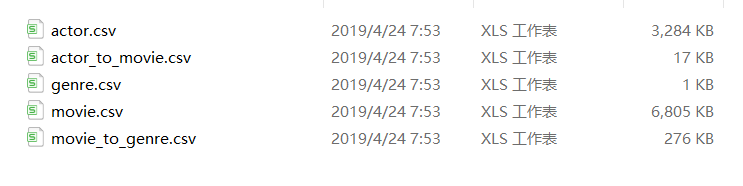 这里的数据也上传在gayhub上了。
这里的数据也上传在gayhub上了。
Neo4j
neo4j简介和安装
neo4j 是当下流行的图数据库(RDB)。官网:https://neo4j.com/
详细的安装教程参考:neo4j安装教程
CSV数据导入
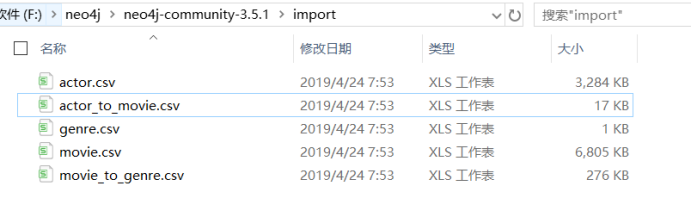
之前的五个csv文件放到neo4安装目录下的import 文件夹下。[系统默认从这导入]
然后开启neo4j服务。在http://localhost:7474命令行输入一下命令:
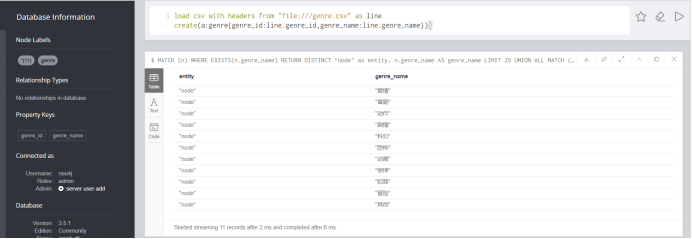
load csv with headers from "file:///genre.csv" as line create(a:genre{genre_id:line.genre_id,genre_name:line.genre_name})
木有学过neo4j 基本命令的童鞋建议先去学一下。这里导入genre.csv 其中with headers 表示文件第一行代表节点属性值(仅限从mysql导出是选择包含列标题的表格)。结果:电影的类型表已经导入。
actor表的导入:
USING PERIODIC COMMIT 100
LOAD CSV FROM 'file:///actor.csv' AS line CREATE (a:Actor { actor_id: line[0], actor_bio: line[1], actor_chName: line[2], actor_foreName: line[3],actor_nationality: line[4], actor_constellation: line[5], actor_birthPlace: line[6], actor_birthDay: line[7], actor_repWorks: line[8], actor_achiem: line[9], actor_brokerage: line[10] })
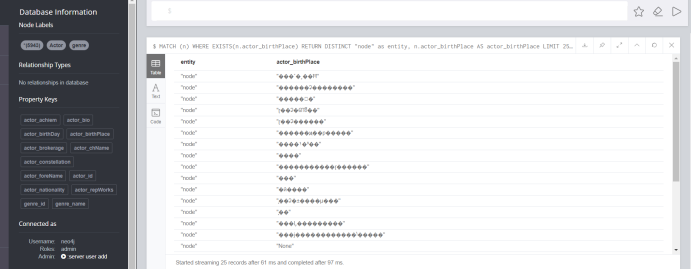
出现乱码:因为 csv 默认GBK格式 ,neo4j支持UTF-8 格式
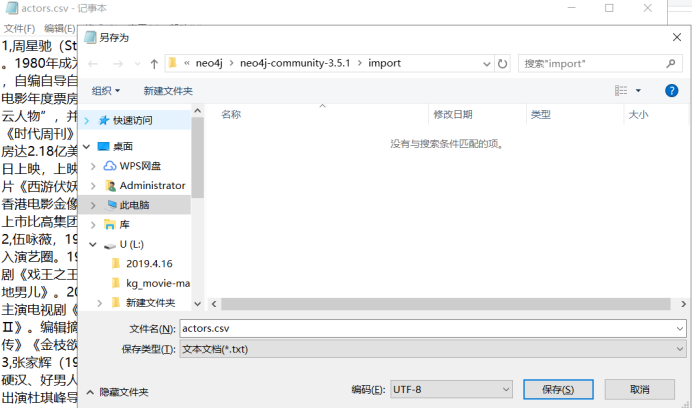
解决方法:选择actor.csv记事本打开,然后另存为选择UTF-8bao保存即可。gayhub中的文件已经是修改完毕后的。
乱码消失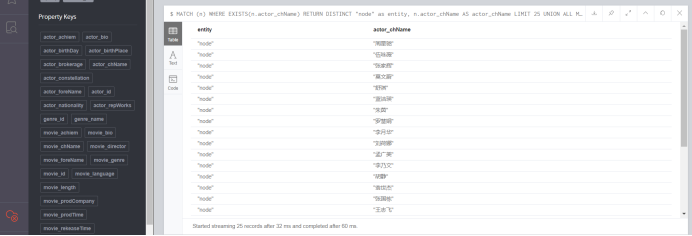
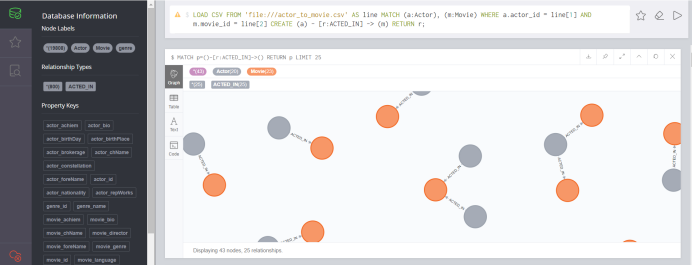
接下来导入演员和电影关系:
LOAD CSV FROM 'file:///actor_to_movie.csv' AS line MATCH (a:Actor), (m:Movie) WHERE a.actor_id = line[1] AND m.movie_id = line[2] CREATE (a) - [r:ACTED_IN] -> (m) RETURN r;
导入电影和类型关系:
USING PERIODIC COMMIT 300
LOAD CSV FROM 'file:///kg_movie_to_genre.csv' AS line MATCH (m:Movie), (g:Genre) WHERE m.movie_id = line[1] AND g.genre_id = line[2] CREATE (m) - [r:Belong_to] -> (g) RETURN r;
导入完成!!!可以做查询了:
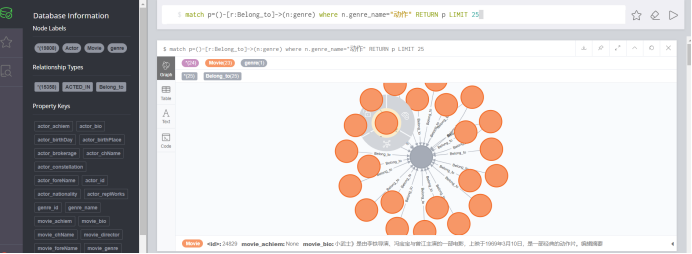
如查找动作片:
match p=()-[r:Belong_to]->(n:genre) where n.genre_name="动作" return p
总结:
第一次用markdown 还是很费时间的,以后慢慢熟悉。今天完成mysql 和neo4j 的数据导入 接下来是 格式准换 D2R。
最后
以上就是淡淡棒棒糖最近收集整理的关于知识图谱构建——Mysql 和 neo4j 数据导入(一)的全部内容,更多相关知识图谱构建——Mysql内容请搜索靠谱客的其他文章。








发表评论 取消回复