假设你手上有一些跟你的task没有直接相关的data,那能不能用这些data帮助我们做一些事情。比如现在要做一些分类:

那不相关的data有很多可能,比如input的分布一样,都是动物,但是task的label不一样。也有一些是input不一样,但是task的label是一样的
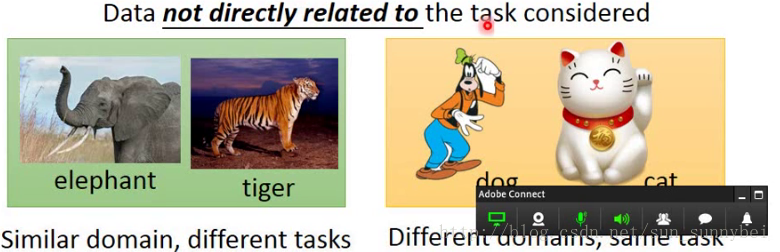
有一些不相干管的data能不能帮助我们呢?
比如想找到台语的语音辨识,但是data很少,可以去扒一些语音,网上有很多。
比如image的识别用于医学辨别肿瘤等,那medical data很少,但是网上可以有很多image的数据,只是不是medical。
比如分析某个法律文献,data很少,但网上有很多data,这些data能不能帮助我们呢?

其实这种情况是有可能,在现实生活中就会有很多transfer Learning。我们可以根据漫画家的生活过程了解到研究生的生活过程。
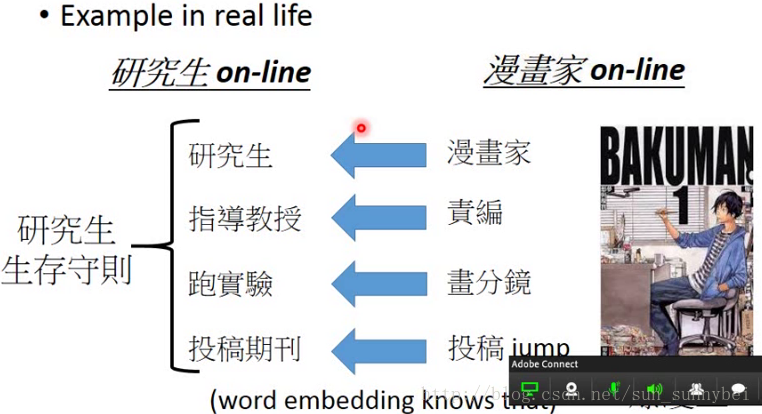
那怎么讲transfer learning呢?不同的文献用的词汇不一样,方法的名称并不统一。
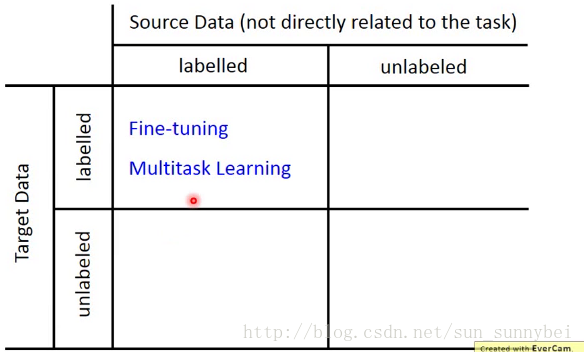
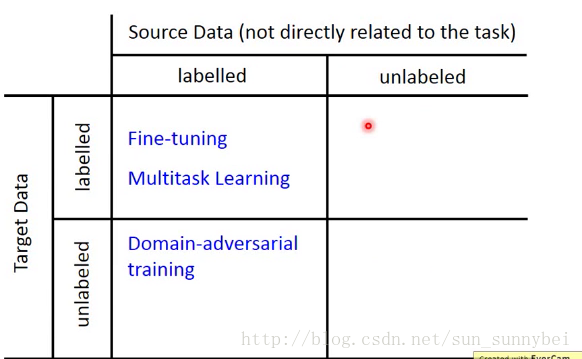
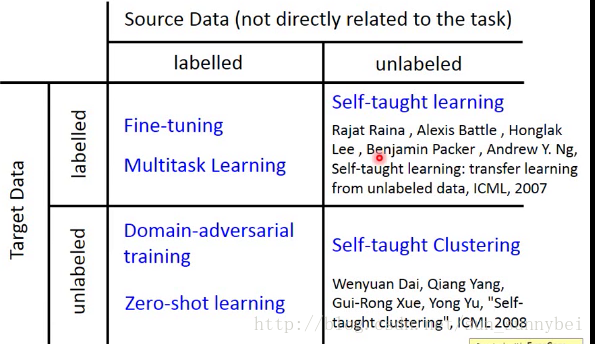
现在我们有一些跟task相关的data,叫做Target Data,有一些跟task无直接关系的data,叫做Source Data。这些Data里可能是有label的,也可能是没有label的。总共有四种可能,那我们从四种可能入手考虑不同的方法
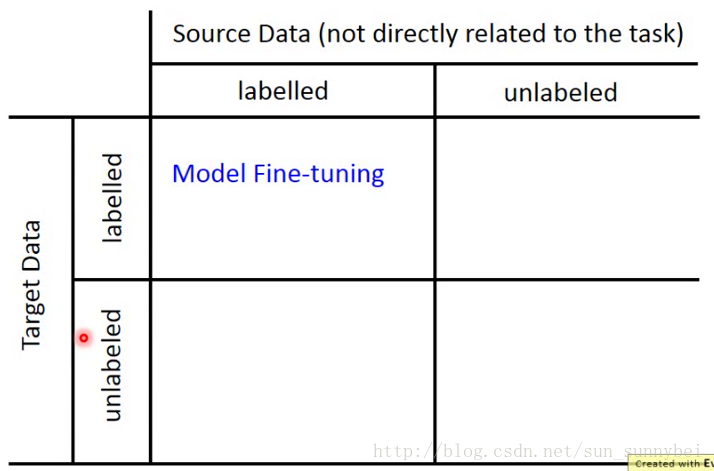
Model Fine-tuning(target和source Data都有label)
前提是假设target Data的量是非常少的。target data非常非常少的话,可以称为 one-shot learning:only a few examples in target domain

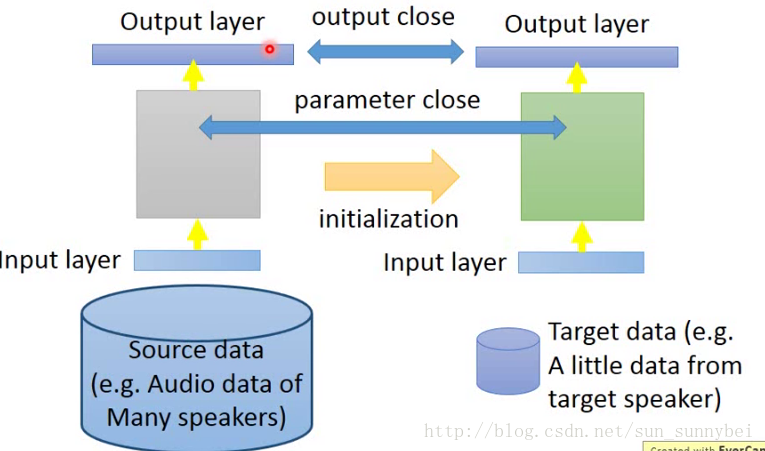
例如在语音上的Speaker adaption,我们要辨识某一个人的声音,但是对于这个人的声音只有少量的data,比如他对机器只说了三句话,只有这三句话的label,但是source data会有很多,有其他人的label data。你不能直接拿target data去train一个model。解决方法就是先用source data去trainmodel,当做初始化参数,然后用target data去fine-tune,去微调。但是target data很少,训练出来的也可能会坏掉。

在训练过程中会有一些技巧:
Model Fine-tuning--Conservative Training
有大量的source data(不同Speaker的声音),然后用它们来train一个神经网络,接下来有少量的targetdata(某个Speaker的声音),那直接用target data去train的话会坏掉。在training的时候,加一个constraint(约束),使得train完之后的新的model和旧的model不要差太多。也就是加一种regularization,使得新旧model在见到同一笔input的时候,它们的结果越接近越好。也可以是加constraint,使得新旧model的参数越接近越好。其实就是使得新旧model的差距不要太大,防止过拟合。
Model Fine-tuning--Layer Transfer
用source data训练出一个model之后,取某几个layer拿出来,直接copy到新的model去,然后用target data,只train那些没有的layer,可以避免overfitting。
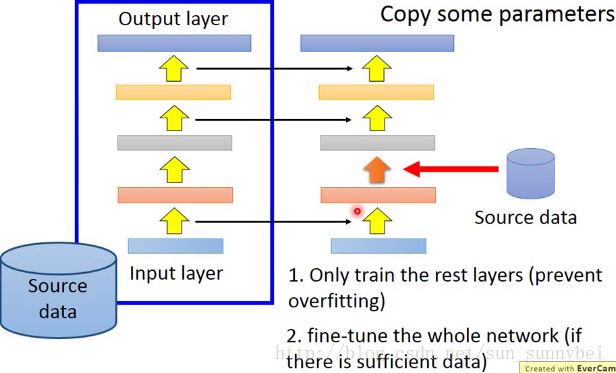
这是一个常见的技巧,那哪些layer应该被Transfer呢?
语音辨识经常会copy最后的output那几层,重新train input那几层,因为在input那几层是要得知语者的发音方式,根据发音方式来识别语句,后面几层是跟语者没有关系的,所以可以被copy。不一样的是从声音到发音方式
image的时候通常copy前面几层,因为在image的时候,前几层就是detect最简单的pattern,比如直线横线等简单图形,所以可以Transfer到其他的task上面。而最后几层的就是比较abstract的东西。
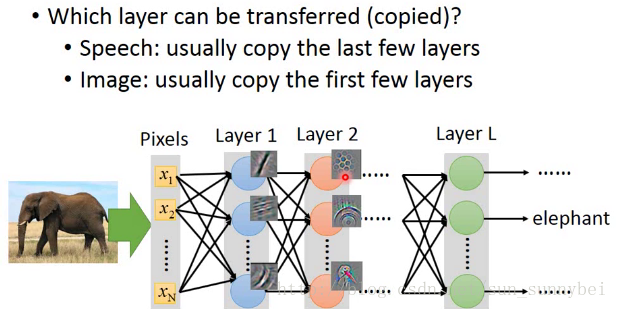
在一些实验中会发现,copy前几个layer,再用target data训练剩下的layer,结果会有一些提升,但是若是copy的太多就会坏掉。也就是说前面的几个layer是可以公用的。用target data训练一个model,fix前面的几个layer,再用target data来训练后几个layer,那结果有的时候就会坏掉,这说明训练过程中前后layer是要前后搭配的。但是你要是fine-tune的话结果就没什么差了。
Multitasking Learning
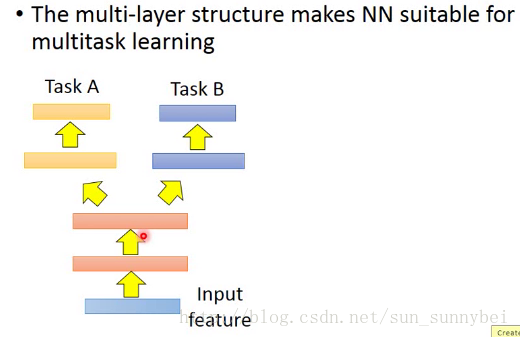
Multitask Learning和Fine-tune的区别是,在fine-tune中关心的是target domain做的好不好,我们在source domain上learn一个modal,然后在target domain上fine-tune,如果在source domain上坏掉了那就算了。而在Multitask Learning上同时考虑sourcedomain和targetdomain,关心的是能不能在这两个domain上同时做好。
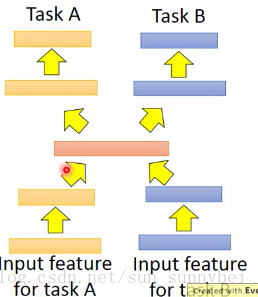
如下图:假设不同的task都用相同的feature,比如影像辨识,只是task不一样,input就是两个task同样的feature,中间的神经元网络分出来一部分处理taskA的一部分处理taskB的,一部分output是A的答案一部分是B的答案。这么做的好处是在前面几个Layer是公用的,前面几个layer就是有很多的数据来训练出来的,可能有比较好的性能。但是你需要确定的是这两个task是不是有共同性,是不是可以公用前面几个layer。
还有一些task 的input都是没有办法share的,但是可以将不同task的不同input用不同的neuron network来transform到同一个domain上去,在同一个domain上apply不同的neuron network,一条路去做taskA,另一条路去做taskB。中间可能有某几个layer是share的,这样子的task上也可以做Transfer Learning。
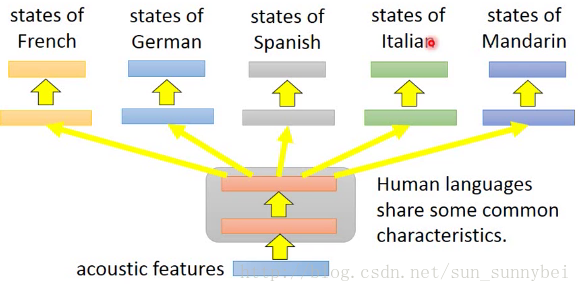
Multitask Learning——Multilingual Speech Recognition
Multitask Learning一个比较成功的例子就是多语言的语音辨识。假设你手上有一大堆不同语言的data,拿在train model的时候,可以train这个model同时辨识五种不同的语言。这个model的前面几个layer可以公用参数,后面几个layer每个语言有自己的参数,这么做是合理的,同样也可以用于translation,比如你既要做中译英和中译法,那你可以将两个model一起训练,都要先把中文的data做process,那这部分的neuron network就可以share。目前发现几乎所有的语言都是可以互相transfer的。
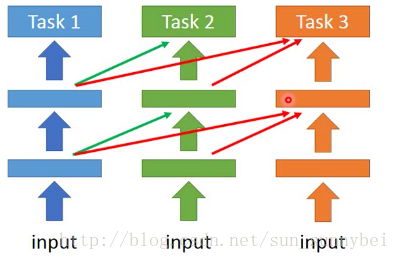
Progressive Neural Network
那如果两个task并没有关联的话,做multitask learning会降低二者的性能。所以有人提出了progressive neural network。
先做task1得到参数fix住,然后训练task2的NN,它的每个hidden layer都回去接前面task1的某个hidden layer的output,好处就是,就算task1和task2不像,task1不受task2 的影响,task2虽然接收task1 的参数,那也可以直接设置成0.这样也不会影响task2的performance。task3也是做同样的事情,从task1和task2同时得到information。
Domain-adversarial training
假设source data是label的而target data是没有label。比如下图中,source data是MNIST的数据是有label的,而target data是MNIST-M的就是有一些奇怪的背景。把source data当做training data,然后target data当做 testing data,两者是完全mismatch的。怎么能在MNIST上train的model在MNIST-M上也能work呢,虽然在后者上面也是要进行数字辨识。但是他们的input是完全不一样的。怎样才能在source data上learn到的model也能apply到target data上呢。

如果直接learn一个model,结果可能是会烂掉的。如果我们把一个neuron network的前面几层看做是在抽取feature,后面几层是在做classification。
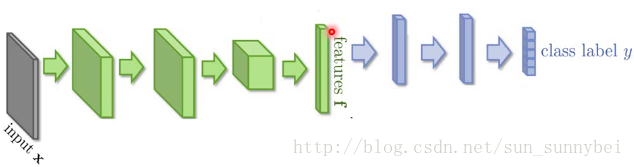
将前面几层看做是抽取feature的话,我们会发现不同domain的feature根本不一样。如下图:把MNIST的image丢进去的话就会分成蓝色的那10群,分别代表了0-9,而另外一群的image丢进去就是红色的一群,你会发现feature抽取出来的根本不在同一个位置上。所以后面的classify虽然能把蓝色的分开,但是对红色的却无能为力。
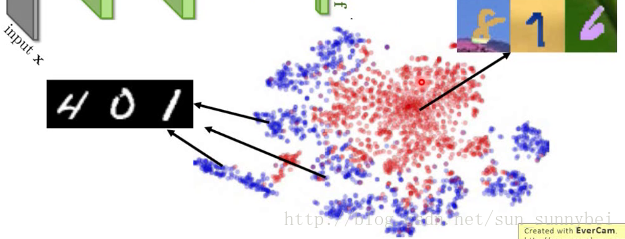
所以现在希望的就是,前面的feature extractor可以把domain的特性去除掉。这就叫做Domain-adversarial training。不是将红色和蓝色的分成两群,而是不同的domain混在一起,把不同的domain的特性都取消掉。
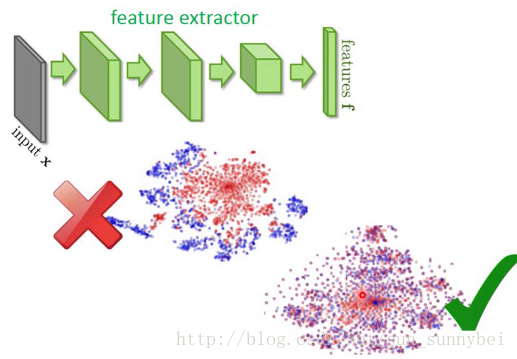
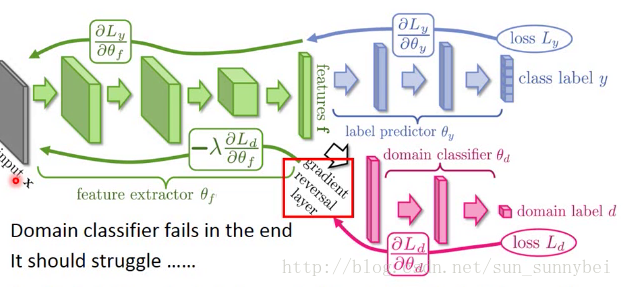
解决方法就是在feature extractor后面加一个domain classifier,能分辨出feature是属于MNIST还是MNIST-M。但是如果只加一个domain classifier是不够的,因为feature extractor可以输出总是0,骗过domain classifier。所以要加上Label predictor使得预测出来的结果就是0-9之间的数字。不止要把domain的特性消掉,还要保留digit的特性。
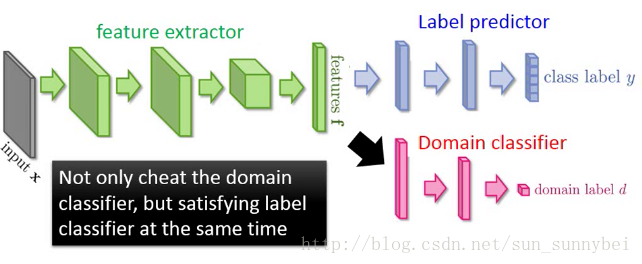
如果将这三个network放在一起,会是一个大型的神经网络。但是不同的部分有不同的目标:
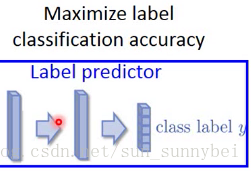 Label predictor是想把分类结果越精确越好
Label predictor是想把分类结果越精确越好
 domain classifier是要正确的区分属于哪个domain
domain classifier是要正确的区分属于哪个domain
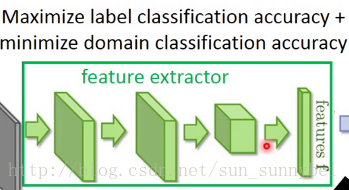 feature extractor是要提高predictor的准确率,同时降低domain classifier的准确率。与domain classifier想做的事情是相反的。
feature extractor是要提高predictor的准确率,同时降低domain classifier的准确率。与domain classifier想做的事情是相反的。
加一个gradient reversal layer,在反向传播时,domain classifier传给feature extractor 的value,feature extractor直接加个负号就好了。又因为domain classifier见不到image,所以最后他肯定是失败了的。但是domain classifier一定要奋力挣扎,把自己的能力发挥到极致,才能把feature extractor的能力逼到极限,才能把特性尽量去除掉
Zero-shot Learning

在zero-shoting learning中,只有source data有label,target data没有Label,而且有一个新的限定条件:source data和target data他们的task是不一样的。比如source data是分辨猫和狗,但是target data是草泥马,而且source data中是从来都没有出现草泥马的。这种task在语音上很早就有Solution了。假如我们把不同的word当做一个class,那在training的时候和在testing的时候就很有可能遇到不同得词汇。语音上做法是,辨识一段声音的单位不要定成word,定成phoneme(理解成音标就好),然后做一个文字和phoneme之间关系的对应表,辨识时只要辨识到phoneme就好,再去查表看这段phoneme对应到哪一个word。这样就算有的word没有出现在training data中,只要在表中出现过,能辨识出属于那个phoneme,就可以处理这个问题。
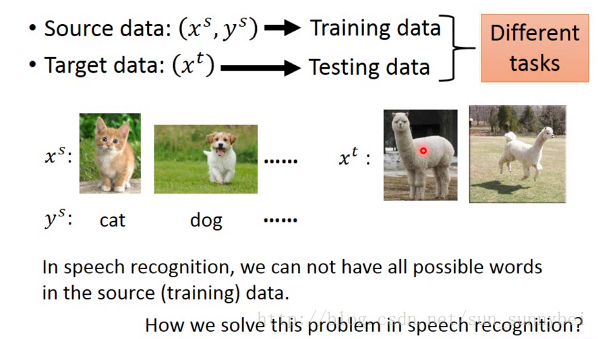
拿在图像中如何处理这个问题呢?
在影像上我们把每个class用它的attribute来表示,也就是说有一个database,有所有不同的object和它的特性,假设你要辨识动物,train和test data不一样,如下:
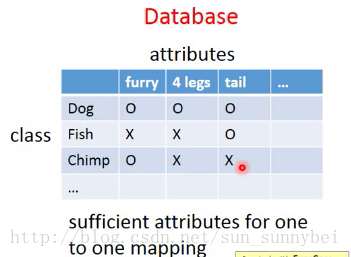
attribute要够丰富,每个class要有独一无的attribute。如果两个class的attribute一样的话model会失败。
辨识的时候不去看每个image属于哪个class,而是看它有哪些的attribute。

所以现在就算来了一个没有见过的动物,也能得到它的属性。然后去查表,但是不一定能有某个动物与他的属性是一模一样的,可以看哪个动物最接近,那个动物就是你想找的。

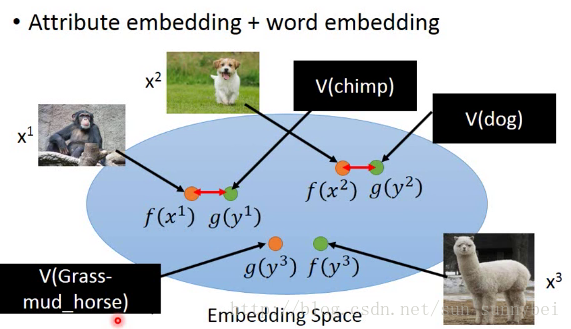
有时候attribute可能非常复杂,甚至可以做attribute embedding(其实也就是一个降维的过程,把image和attribute都降维到同一个空间上)。把每一张image都透过一个transform f变成embedding space上的一个点,然后把所有attribute也通过g变成embedding space上的一个点。g和f可以都是network(二者的降维过程是不一样的所以有不同的network)。然后training的时候希望f和g越接近越好。testing有一张没有见过的image(x3),可以看它的attribute在embedding space上跟哪个attribute最近,那就知道是哪个attribute了。

那如果我们根本没有database呢?我们并不知道每个动物的attribute是什么,那可以借用word vector。word vector的每个dimension都代表了某种attribute。那可以把attribute统统换成wordvector,再做刚才的embedding就结束了:
在zero-learning训练过程中,如果只是minimize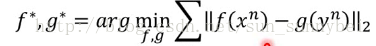 是不行的,他会把所有的x和y都投影到一个点上结束了。
是不行的,他会把所有的x和y都投影到一个点上结束了。
所以要重新设计一下loss function,要考虑如果x和y不是同一个pair那么它们的距离要被拉大:
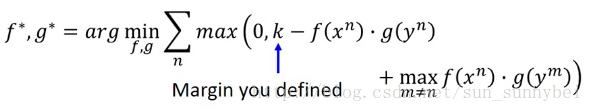
这里面的loss取了一个max,要么是0,要么是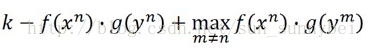 。其中的K是提前定好的值。只有在下面的式子成立是才不存在loss。
。其中的K是提前定好的值。只有在下面的式子成立是才不存在loss。
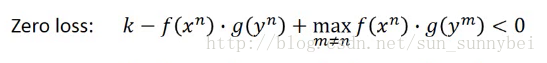
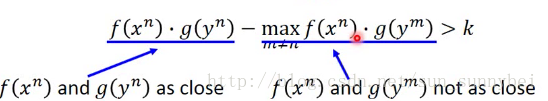 这样子可以看出来,这个式子的含义是,当x和y是pair的时候,他们的f(X^n)和g(y^n)的内积比其他的与x不是pair的但是与x最近的y^m的内积还要大于k的时候,(在所有的不是y^n的y里面找一个最近的,还是要比x^n和y^n大到k)才会是zero-loss。所以这个loss function不仅把成pair的拉近了,还把不成pair的拉远了。
这样子可以看出来,这个式子的含义是,当x和y是pair的时候,他们的f(X^n)和g(y^n)的内积比其他的与x不是pair的但是与x最近的y^m的内积还要大于k的时候,(在所有的不是y^n的y里面找一个最近的,还是要比x^n和y^n大到k)才会是zero-loss。所以这个loss function不仅把成pair的拉近了,还把不成pair的拉远了。
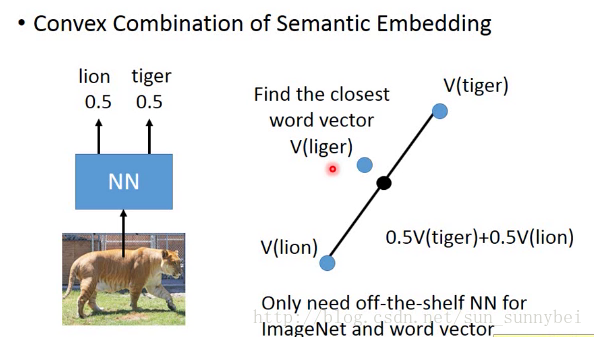
还有一个zero-learning的方法叫做convex combination Semantic Embedding:
不用做learning,有一个语音辨识系统和一个word vector,都可以在网上找,把一张图放到neuron network里去,output给出是0.5几率是tiger和0.5的几率是lion。然后在word vector中构成一个新的vector。找一个word vector与这个新的vector最接近,比如是liger,那这个image就是liger。
最近有一篇文章是说,机器可以英译汉,汉译英,英译韩,韩译英,但是它从来没有汉译韩过,但是机器是可以把汉文翻译成韩文的,这是因为机器会把不同语言的input都投影到同一个space上,这个space是与语言无关的,不同语言的同一个语句会投影在同一个位置或者相近的位置上,所以可以进行翻译。
在source data没有Label的情况下是怎么样的呢?
分别是self-taught learning和self-taught clustering。老师的视频并没有细讲。
最后
以上就是留胡子菠萝最近收集整理的关于Transfer Learning的全部内容,更多相关Transfer内容请搜索靠谱客的其他文章。








发表评论 取消回复