比较新的论文,2019.12的,来自Facebook AI。
Task是表情迁移,借鉴了styleGAN中的生成器,能得到更自然的large scale图像。创新主要在生成器的使用方式上,避免了训练中对pair data的需求,一是能保证更充足的数据,二是对于新数据不用重新训练。
表情是一种更为抽象深层的特征,且通常附着于人脸特征上,很难单独提取,会受到个体面部特征差异的影响,通常要考虑如何解耦合。本文利用了styleGAN中的生成器实现:
styleGAN中对输入的latent code产生的不同level的特征进行了解耦合,以实现多种level上对图像生成进行控制,task是更细致地生成图像;
本文目的是通过迭代训练得到输入图像中解耦合的表情特征,然后进行特征的交换实现表情迁移。本文的解耦合实现思路是和以往的方法相反的,通常做法是用CNN从图像中提取特征,通过训练CNN改变网络中的参数调整特征的性质;本文则是直接初始化特征向量,输入styleGAN中预训练的生成器得到复原图像(即我们想要解耦合出表情特征的图像),通过设计目标函数,使得输入的特征向量在训练中不断更新靠近目标图像中的表情特征,这期间生成器参数是固定的,训练的不是网络而是特征向量。
具体步骤和分析如下:
1. 利用检测的landmarks对图像中的人脸区域进行crop和normalize;
2. 初始化style vectors (想要从图像
中提取的特征),输入到预训练好的styleGAN中的生成器model
,使得生成器产生图像
。该生成过程中,生成器model
参数保持不变,改变的是style vectors
,迫使该变化的是目标函数:
上式中,是产生的图像,
是想要生成的图像,
表示距离度量,文中实验表明用一个预训练的VGG效果最好,因为VGG提取特征进行度量相当于在比较perceptual similarity,不单是pixel-level。实验结果是采用VGG的第九层生成的结果最理想:

style vectors 通过多次迭代更新后可以变为目标图像中的特征,度量函数
随着迭代次数的变化如下图所示:
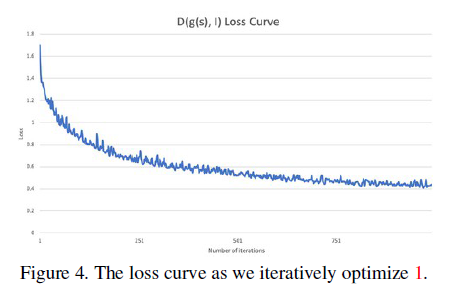
可以看到随着迭代次数的增加,由style vectors 生成的图像越来越接近图像
。这个过程中,由
生成的图像可视化结果如下:

生成的图像是越来越接近我们的图像的,iter=0时生成的图像是由初始化的
生成的,是一张随机的图片。
3. 得到提取出的style vectors 后,需要进行一张图像到另一张的迁移。当进行图像迁移任务时,有两张图像,一张提供人脸外貌基本特征appearance的图像
,一张提供表情特征expression的图像
,迁移的目的是将后者的表情迁移到前者的人脸上,从特征层面看,就是将两者的特征进行融合,目标函数如下:
![]()
其中度量的是人脸外貌特征,
度量的是表情特征,它们使用相同的生成器
生成图像,但是度量函数的不同导致style vectors
向两个方向改变:前者向图像
中的外貌靠拢,后者向图像
中的表情靠拢,最后使得目标函数最小的
即为平衡了两者的特征向量
。实验中
采用L2 loss,
采用基于gram matrix的style loss。但是该优化过程导致结果中存在很多artifacts,本文采取了线性组合的方法:
![]()
这表示,每一层的都是一个线性组合,优化就变成了一个线性规划问题,其中
是0-1矩阵,
。其实就是每一层,两种特征向量取其中一个。在第i层若是取了
就表示该层主要影响生成图像中的外貌特征,而不是表情特征,这就是特征融合的过程。实验表明,第4-5层使用表情特征效果最好。
4. 最后用融合特征生成人脸图像,然后warp复原为带有背景的正常图像。
一些结果如下:

本文中的解耦合,一方面是通过styleGAN中生成器的特性实现的,可以看styleGAN论文;另一方面它不需要成对的数据来训练提取表情特征,它的提取过程是:利用初始化的特征向量不断生成靠近自身图像的图像,也就是说训练过程只要自己本身一张图像即可。给定一张图像,即可迭代得到其中的特征向量,主要代价都在迭代上,不过关于这里的性能还没有研究。
最后
以上就是整齐母鸡最近收集整理的关于人脸表情系列:论文阅读——Unconstrained Facial Expression Transfer using Style-based Generator的全部内容,更多相关人脸表情系列:论文阅读——Unconstrained内容请搜索靠谱客的其他文章。








发表评论 取消回复