一、背景
最近事情比较多,一个多月没写CSDN了,最近打算做一做satrGAN。
starGAN是Yunjey Choi等人于17年11月提出的一个模型[1]。该模型可以实现人脸的属性修改,原理上来说就是域迁移,之前cycleGAN本质上也是域迁移,不过cycyleGAN是单个域,而starGAN则是多个域。
本实验所采用的数据集为CelebA(原论文中作者还使用了数据集RaFD),之前也介绍过,本文用尽量简短的代码实现该模型。
[1]文章链接:https://arxiv.org/pdf/1711.09020.pdf
[2]参考代码:https://github.com/taki0112/StarGAN-Tensorflow
二、starGAN原理
这个模型是2018年CVPR的一篇oral,网上的解读还蛮多的,网上找了几篇还不错的:
[3]StarGAN论文及代码理解
[4]starGAN 论文学习
先来看一下作者的效果图:

上图最左边一列和第第6列是输入图像,右边以此是按照:金发,性别,年龄,苍白肤色,生气,高兴,害怕,等属性进行修改后的结果。
文章的摘要部分:
Recent studies have shown remarkable success in image-to-image translation for two domains. However, existing approaches have limited scalability and robustness in handling more than two domains, since different models should be built independently for every pair of image domains. To address this limitation, we propose StarGAN, a novel and scalable approach that can perform image-to-image translations for multiple domains using only a single model. Such a unified model architecture of StarGAN allows simultaneous training of multiple datasets with different domains within a single network. This leads to StarGAN’s superior quality of translated images compared to existing models as well as the novel capability of flexibly translating an input image to any desired target domain. We empirically demonstrate the effectiveness of our approach on a facial attribute transfer and a facial expression synthesis tasks.
摘要里也说的很明确,starGAN的最大优势是可以在一个模型中进行多个域迁移,这在其他模型中是没有的,它提高了图像域迁移的可拓展性和鲁棒性。如果用一张图来表示传统GAN在域迁移中的做法和starGAN的做法的区别,如:
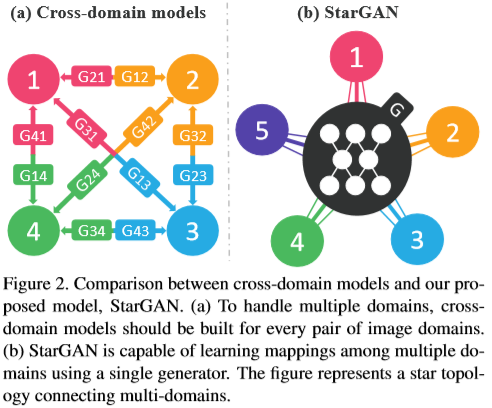
左边是传统的GAN,右边是starGAN,传统的域迁移需要对不同的两个域之间相互进行特征提取,这样就导致只有k个域的情况下却要k(k-1)个生成器。而starGAN则解决了这个问题,自始至终只需要一个生成器。
作者这篇论文的主要贡献在于:
• We propose StarGAN, a novel generative adversarial network that learns the mappings among multiple domains using only a single generator and a discriminator, training effectively from images of all domains. (提出了starGAN,只用一个生成器和判别器来学习多个域之间的映射关系。)
• We demonstrate how we can successfully learn multi domain image translation between multiple datasets by utilizing a mask vector method that enables StarGAN to control all available domain labels. (使用掩膜矢量法让starGAN控制所有域的标签)
• We provide both qualitative and quantitative results on facial attribute transfer and facial expression synthesis tasks using StarGAN, showing its superiority over baseline models. (在人脸上的表现要远远优于其他模型)
在starGAN之前,也有很多GAN模型可以用于image-to-image,比如pix2pix(需要影像成对输入),UNIT(本质上是coGAN),cycleGAN和DiscoGAN。那么starGAN模型结构又如何呢:
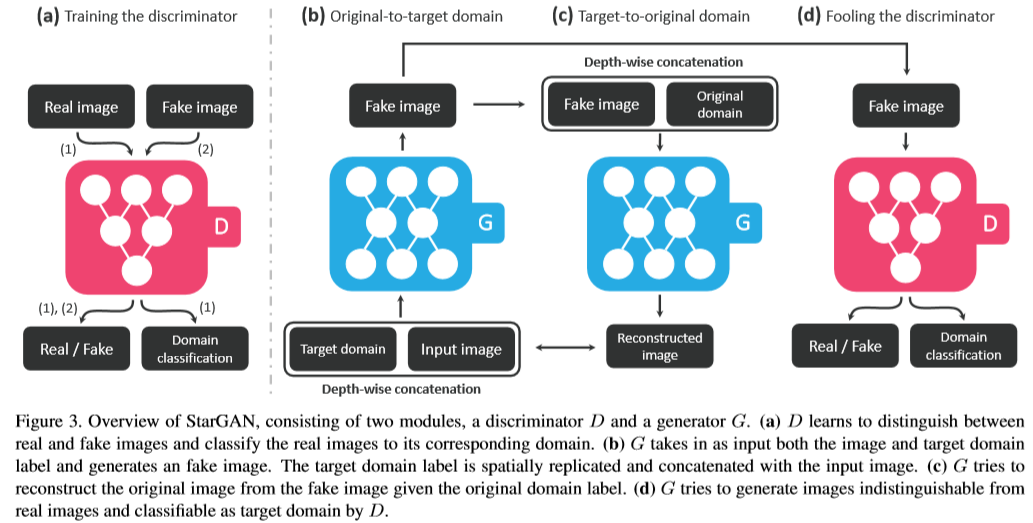
starGAN的模型结构中,生成器包含2个卷积层(下采样的步长设置为2),6个残差层,2个反卷积层(上采样的步长设置为2),生成器中还使用了归一化(instance normalization)。判别器则采用PatchGAN的结构,但没有使用归一化层。
starGAN的模型结构参考了DIAT(仅用了 adversarial loss 来映射域之间的关系),cycleGAN( 用adversarial loss和 cycle consistency losses来映射域之间的关系 )和IcGAN(cGAN的改进版),同时为了防止模型倒塌,作者还借鉴了WGAN的思想,并对 adversarial loss (对抗损失)进行了改进。
然后再看一下一些参数的描述。这里我们用x表示输入影像,y表示输出影像,c表示标签,G表示判别器,D表示生成器。那么一些关键的loss函数则可以如下设置:
(1)Adversarial Loss(对抗损失)
对抗损失一般只有由生成器和判别器来构建的损失函数,starGAN中的对抗损失由两部分组成,一部分是输入x到判别器中产生的损失,另一部分是(1-输入生成器生成的图像到判别器中):

(2)Domain Classification Loss(域分类损失)
starGAN对不同的域引入了标签c,在判别器的顶部就是一个复杂的分类器。在同时优化G和D的同时,可以定义一个域分类损失:

(3)Reconstruction Loss (重构损失)
在最小化上述两种loss并不能保证与目标域无关的内容发生变化,为了保留这些无关的内容,模型中的生成器引入了重构损失:

(4)Full Objective(总损失)
最后就是所有用到的损失函数了,判别器由两部分loss组成:对抗损失和域分类损失,生成器的损失由三部分构成:对抗损失和域分类损失和重构损失,另外,对于域分类损失的权重系数设置为1,重构损失的权重系数设置为10。

前面也提到过,模型中是需要输入标签c的,实际上作者在做的时候,标签c是以one-hot编码表示的,作者将此输入称为mask vector。最后来看一下训练中的一些关键参数的设置:

简单的说一下,作者对数据集做了数据增强,以0.5的概率进行水平随机裁剪,每次训练包含1次生成器和5次判别器的训练,batch_size设置为16,学习率在前10个epochs为0.0001,在后10个epochs衰减到0。
值得一提的是,starGAN不仅能做单属性转换,多属性转换也能够很好的完成:

下面关于starGAN的实现,原作者用的pytorch,不过幸运的是网上可以找到tensorflow版本的代码,我主要参考了[2]的代码:
[2]参考代码:https://github.com/taki0112/StarGAN-Tensorflow
三、starGAN实现
1. 文件结构
所有文件结构为:
-- dataset # 训练数据,需要自己准备
|------ celebA
|------ test # 这个是自己的测试数据,随便放自己想测试的图
|------ test.jpg
|------ train # 这个是celebA数据集,需要自己下载并简单处理
|------ 000001.jpg
|------ 000002.jpg
|------ ......
|------ list_attr_celeba.txt
-- png2jpg.py
-- ops.py
-- starGAN.py
-- main.py
-- utils.py2.数据准备
我们需要准备的数据有两个,一个是celebA图像,一个是txt文本。
(1)celebA图像
关于celebA图像,在之前的文章中也介绍过,可以直接看这里:对抗生成网络学习(六)——BEGAN实现不同人脸的生成(tensorflow实现),这篇文章中我就不在多做介绍了。需要做的就是从网上下载好数据集并解压,做好之后是这个样子:

但这不能直接用在实验中,因为txt文件中的所有图像记录都是jpg,因此我们需要将其转换为jpg格式。
下面直接给出转换代码png2jpg.py文件,虽然精度可能会有所损失,但是影响不大:
import os
from skimage import io
def png2jpg(input_path, output_path):
"""
函数功能:将input_path路径下的所有png格式的图像以jpg格式保存至output_path
"""
if not os.path.exists(output_path):
os.makedirs(output_path)
images = os.listdir(input_path)
for i in images:
img = io.imread(os.path.join(input_path, i))
filename = os.path.splitext(i)[0]
io.imsave(output_path+filename+'.jpg', img)
if __name__ == '__main__':
input_path = './dataset/celebA/train_png/'
output_path = './dataset/celebA/train_jpg/'
png2jpg(input_path, output_path)
做好之后的效果如下:

把这些图放到前面提到的路径'./dataset/celebA/train/'文件下即可。
(2)list_attr_celeba.txt文本
starGAN实验还需要一个list_attr_celeba.txt文本,这个文本可以从官网或者链接[2]中下载。下面会详细介绍。
如果是从官网下载,可以直接打开百度云链接:https://pan.baidu.com/s/1eSNpdRG#list/path=%2Fsharelink2785600790-938296576863897%2FCelebA%2FAnno&parentPath=%2Fsharelink2785600790-938296576863897,然后找到下面的文件下载就可以了:
如果是从链接[2]中下载,那么打开这个链接https://github.com/taki0112/StarGAN-Tensorflow/tree/master/dataset/celebA,然后找到这个txt文件就可以了。
这个txt文本的内容是这样的:

第一行是所有图片的数量,然后第二行是所有属性,从第三行开始,每一行都是一张图片,这张图片拥有的属性用1标注出,没有的属性用-1标注。这里需要注意的是所有图片的格式后缀都是jpg,这也是为什么刚才我们要把png格式的图片转换为jpg了,就是为了和这个文件对应起来,以便能够直接使用数据集里面的特征。
下载好这个txt文本之后,别忘了放在正确的路径下。
准备好这些数据之后,便可以开始编写实验文件了。
3. 操作文件utils.py
这里主要都是对image的一些操作,所有代码我没有修改,直接放上来:
import scipy.misc
import numpy as np
import os
from scipy import misc
import tensorflow as tf
import tensorflow.contrib.slim as slim
import random
class ImageData:
def __init__(self, load_size, channels, data_path, selected_attrs, augment_flag=False):
self.load_size = load_size
self.channels = channels
self.augment_flag = augment_flag
self.selected_attrs = selected_attrs
self.data_path = os.path.join(data_path, 'train')
check_folder(self.data_path)
self.lines = open(os.path.join(data_path, 'list_attr_celeba.txt'), 'r').readlines()
self.train_dataset = []
self.train_dataset_label = []
self.train_dataset_fix_label = []
self.test_dataset = []
self.test_dataset_label = []
self.test_dataset_fix_label = []
self.attr2idx = {}
self.idx2attr = {}
def image_processing(self, filename, label, fix_label):
x = tf.read_file(filename)
x_decode = tf.image.decode_jpeg(x, channels=self.channels)
img = tf.image.resize_images(x_decode, [self.load_size, self.load_size])
img = tf.cast(img, tf.float32) / 127.5 - 1
if self.augment_flag :
augment_size = self.load_size + (30 if self.load_size == 256 else 15)
p = random.random()
if p > 0.5 :
img = augmentation(img, augment_size)
return img, label, fix_label
def preprocess(self) :
all_attr_names = self.lines[1].split()
for i, attr_name in enumerate(all_attr_names) :
self.attr2idx[attr_name] = i
self.idx2attr[i] = attr_name
lines = self.lines[2:]
random.seed(1234)
random.shuffle(lines)
for i, line in enumerate(lines) :
split = line.split()
filename = os.path.join(self.data_path, split[0])
values = split[1:]
label = []
for attr_name in self.selected_attrs :
idx = self.attr2idx[attr_name]
if values[idx] == '1' :
label.append(1.0)
else :
label.append(0.0)
if i < 2000 :
self.test_dataset.append(filename)
self.test_dataset_label.append(label)
else :
self.train_dataset.append(filename)
self.train_dataset_label.append(label)
# ['./dataset/celebA/train/019932.jpg', [1, 0, 0, 0, 1]]
self.test_dataset_fix_label = create_labels(self.test_dataset_label, self.selected_attrs)
self.train_dataset_fix_label = create_labels(self.train_dataset_label, self.selected_attrs)
print('n Finished preprocessing the CelebA dataset...')
def load_test_data(image_path, size=128):
img = misc.imread(image_path, mode='RGB')
img = misc.imresize(img, [size, size])
img = np.expand_dims(img, axis=0)
img = normalize(img)
return img
def augmentation(image, aug_size):
seed = random.randint(0, 2 ** 31 - 1)
ori_image_shape = tf.shape(image)
image = tf.image.random_flip_left_right(image, seed=seed)
image = tf.image.resize_images(image, [aug_size, aug_size])
image = tf.random_crop(image, ori_image_shape, seed=seed)
return image
def normalize(x) :
return x/127.5 - 1
def save_images(images, size, image_path):
return imsave(inverse_transform(images), size, image_path)
def merge(images, size):
h, w = images.shape[1], images.shape[2]
if (images.shape[3] in (3,4)):
c = images.shape[3]
img = np.zeros((h * size[0], w * size[1], c))
for idx, image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
img[j * h:j * h + h, i * w:i * w + w, :] = image
return img
elif images.shape[3] == 1:
img = np.zeros((h * size[0], w * size[1]))
for idx, image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
img[j * h:j * h + h, i * w:i * w + w] = image[:, :, 0]
return img
else:
raise ValueError('in merge(images,size) images parameter ''must have dimensions: HxW or HxWx3 or HxWx4')
def imsave(images, size, path):
return scipy.misc.imsave(path, merge(images, size))
def inverse_transform(images):
return (images+1.)/2.
def check_folder(log_dir):
if not os.path.exists(log_dir):
os.makedirs(log_dir)
return log_dir
def show_all_variables():
model_vars = tf.trainable_variables()
slim.model_analyzer.analyze_vars(model_vars, print_info=True)
def str2bool(x):
return x.lower() in ('true')
def create_labels(c_org, selected_attrs=None):
"""Generate target domain labels for debugging and testing."""
# Get hair color indices.
c_org = np.asarray(c_org)
hair_color_indices = []
for i, attr_name in enumerate(selected_attrs):
if attr_name in ['Black_Hair', 'Blond_Hair', 'Brown_Hair', 'Gray_Hair']:
hair_color_indices.append(i)
c_trg_list = []
for i in range(len(selected_attrs)):
c_trg = c_org.copy()
if i in hair_color_indices: # Set one hair color to 1 and the rest to 0.
c_trg[:, i] = 1.0
for j in hair_color_indices:
if j != i:
c_trg[:, j] = 0.0
else:
c_trg[:, i] = (c_trg[:, i] == 0) # Reverse attribute value.
c_trg_list.append(c_trg)
c_trg_list = np.transpose(c_trg_list, axes=[1, 0, 2]) # [c_dim, bs, ch]
return c_trg_list4. 图层文件ops.py
这里定义了一些网络模型中常用的层,代码我也直接给出:
import tensorflow as tf
import tensorflow.contrib as tf_contrib
# Xavier : tf_contrib.layers.xavier_initializer()
# He : tf_contrib.layers.variance_scaling_initializer()
# Normal : tf.random_normal_initializer(mean=0.0, stddev=0.02)
# l2_decay : tf_contrib.layers.l2_regularizer(0.0001)
weight_init = tf_contrib.layers.xavier_initializer()
weight_regularizer = None
##################################################################################
# Layer
##################################################################################
def conv(x, channels, kernel=4, stride=2, pad=0, pad_type='zero', use_bias=True, scope='conv_0'):
with tf.variable_scope(scope):
if pad_type == 'zero' :
x = tf.pad(x, [[0, 0], [pad, pad], [pad, pad], [0, 0]])
if pad_type == 'reflect' :
x = tf.pad(x, [[0, 0], [pad, pad], [pad, pad], [0, 0]], mode='REFLECT')
x = tf.layers.conv2d(inputs=x, filters=channels,
kernel_size=kernel, kernel_initializer=weight_init,
kernel_regularizer=weight_regularizer,
strides=stride, use_bias=use_bias)
return x
def deconv(x, channels, kernel=4, stride=2, use_bias=True, scope='deconv_0'):
with tf.variable_scope(scope):
x = tf.layers.conv2d_transpose(inputs=x, filters=channels,
kernel_size=kernel, kernel_initializer=weight_init, kernel_regularizer=weight_regularizer,
strides=stride, padding='SAME', use_bias=use_bias)
return x
def flatten(x) :
return tf.layers.flatten(x)
##################################################################################
# Residual-block
##################################################################################
def resblock(x_init, channels, use_bias=True, scope='resblock'):
with tf.variable_scope(scope):
with tf.variable_scope('res1'):
x = conv(x_init, channels, kernel=3, stride=1, pad=1, use_bias=use_bias)
x = instance_norm(x)
x = relu(x)
with tf.variable_scope('res2'):
x = conv(x, channels, kernel=3, stride=1, pad=1, use_bias=use_bias)
x = instance_norm(x)
return x + x_init
##################################################################################
# Activation function
##################################################################################
def lrelu(x, alpha=0.2):
return tf.nn.leaky_relu(x, alpha)
def relu(x):
return tf.nn.relu(x)
def tanh(x):
return tf.tanh(x)
##################################################################################
# Normalization function
##################################################################################
def instance_norm(x, scope='instance_norm'):
return tf_contrib.layers.instance_norm(x,
epsilon=1e-05,
center=True, scale=True,
scope=scope)
##################################################################################
# Loss function
##################################################################################
def discriminator_loss(loss_func, real, fake):
real_loss = 0
fake_loss = 0
if loss_func.__contains__('wgan') :
real_loss = -tf.reduce_mean(real)
fake_loss = tf.reduce_mean(fake)
if loss_func == 'lsgan' :
real_loss = tf.reduce_mean(tf.squared_difference(real, 1.0))
fake_loss = tf.reduce_mean(tf.square(fake))
if loss_func == 'gan' or loss_func == 'dragan' :
real_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=tf.ones_like(real), logits=real))
fake_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=tf.zeros_like(fake), logits=fake))
if loss_func == 'hinge' :
real_loss = tf.reduce_mean(relu(1.0 - real))
fake_loss = tf.reduce_mean(relu(1.0 + fake))
loss = real_loss + fake_loss
return loss
def generator_loss(loss_func, fake):
fake_loss = 0
if loss_func.__contains__('wgan') :
fake_loss = -tf.reduce_mean(fake)
if loss_func == 'lsgan' :
fake_loss = tf.reduce_mean(tf.squared_difference(fake, 1.0))
if loss_func == 'gan' or loss_func == 'dragan' :
fake_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=tf.ones_like(fake), logits=fake))
if loss_func == 'hinge' :
fake_loss = -tf.reduce_mean(fake)
loss = fake_loss
return loss
def classification_loss(logit, label) :
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=label, logits=logit))
return loss
def L1_loss(x, y):
loss = tf.reduce_mean(tf.abs(x - y))
return loss5. 模型文件starGAN.py
这个文件就是最关键的模型文件了,先给出代码:
from ops import *
from utils import *
import time
from tensorflow.contrib.data import prefetch_to_device, shuffle_and_repeat, map_and_batch
import numpy as np
from glob import glob
class StarGAN(object) :
def __init__(self, sess, args):
self.model_name = 'StarGAN'
self.sess = sess
self.checkpoint_dir = args.checkpoint_dir
self.sample_dir = args.sample_dir
self.result_dir = args.result_dir
self.log_dir = args.log_dir
self.dataset_name = args.dataset
self.dataset_path = os.path.join('./dataset', self.dataset_name)
self.augment_flag = args.augment_flag
self.epoch = args.epoch
self.iteration = args.iteration
self.decay_flag = args.decay_flag
self.decay_epoch = args.decay_epoch
self.gan_type = args.gan_type
self.batch_size = args.batch_size
self.print_freq = args.print_freq
self.save_freq = args.save_freq
self.init_lr = args.lr
self.ch = args.ch
self.selected_attrs = args.selected_attrs
self.custom_label = np.expand_dims(args.custom_label, axis=0)
self.c_dim = len(self.selected_attrs)
""" Weight """
self.adv_weight = args.adv_weight
self.rec_weight = args.rec_weight
self.cls_weight = args.cls_weight
self.ld = args.ld
""" Generator """
self.n_res = args.n_res
""" Discriminator """
self.n_dis = args.n_dis
self.n_critic = args.n_critic
self.img_size = args.img_size
self.img_ch = args.img_ch
print()
print("##### Information #####")
print("# gan type : ", self.gan_type)
print("# selected_attrs : ", self.selected_attrs)
print("# dataset : ", self.dataset_name)
print("# batch_size : ", self.batch_size)
print("# epoch : ", self.epoch)
print("# iteration per epoch : ", self.iteration)
print()
print("##### Generator #####")
print("# residual blocks : ", self.n_res)
print()
print("##### Discriminator #####")
print("# discriminator layer : ", self.n_dis)
print("# the number of critic : ", self.n_critic)
##################################################################################
# Generator
##################################################################################
def generator(self, x_init, c, reuse=False, scope="generator"):
channel = self.ch
c = tf.cast(tf.reshape(c, shape=[-1, 1, 1, c.shape[-1]]), tf.float32)
c = tf.tile(c, [1, x_init.shape[1], x_init.shape[2], 1])
x = tf.concat([x_init, c], axis=-1)
with tf.variable_scope(scope, reuse=reuse):
x = conv(x, channel, kernel=7, stride=1, pad=3, use_bias=False, scope='conv')
x = instance_norm(x, scope='ins_norm')
x = relu(x)
# Down-Sampling
for i in range(2) :
x = conv(x, channel*2, kernel=4, stride=2, pad=1, use_bias=False, scope='conv_'+str(i))
x = instance_norm(x, scope='down_ins_norm_'+str(i))
x = relu(x)
channel = channel * 2
# Bottleneck
for i in range(self.n_res):
x = resblock(x, channel, use_bias=False, scope='resblock_' + str(i))
# Up-Sampling
for i in range(2) :
x = deconv(x, channel//2, kernel=4, stride=2, use_bias=False, scope='deconv_'+str(i))
x = instance_norm(x, scope='up_ins_norm'+str(i))
x = relu(x)
channel = channel // 2
x = conv(x, channels=3, kernel=7, stride=1, pad=3, use_bias=False, scope='G_logit')
x = tanh(x)
return x
##################################################################################
# Discriminator
##################################################################################
def discriminator(self, x_init, reuse=False, scope="discriminator"):
with tf.variable_scope(scope, reuse=reuse) :
channel = self.ch
x = conv(x_init, channel, kernel=4, stride=2, pad=1, use_bias=True, scope='conv_0')
x = lrelu(x, 0.01)
for i in range(1, self.n_dis):
x = conv(x, channel * 2, kernel=4, stride=2, pad=1, use_bias=True, scope='conv_' + str(i))
x = lrelu(x, 0.01)
channel = channel * 2
c_kernel = int(self.img_size / np.power(2, self.n_dis))
logit = conv(x, channels=1, kernel=3, stride=1, pad=1, use_bias=False, scope='D_logit')
c = conv(x, channels=self.c_dim, kernel=c_kernel, stride=1, use_bias=False, scope='D_label')
c = tf.reshape(c, shape=[-1, self.c_dim])
return logit, c
##################################################################################
# Model
##################################################################################
def gradient_panalty(self, real, fake, scope="discriminator"):
if self.gan_type == 'dragan' :
shape = tf.shape(real)
eps = tf.random_uniform(shape=shape, minval=0., maxval=1.)
x_mean, x_var = tf.nn.moments(real, axes=[0, 1, 2, 3])
x_std = tf.sqrt(x_var) # magnitude of noise decides the size of local region
noise = 0.5 * x_std * eps # delta in paper
# Author suggested U[0,1] in original paper, but he admitted it is bug in github
# (https://github.com/kodalinaveen3/DRAGAN). It should be two-sided.
alpha = tf.random_uniform(shape=[shape[0], 1, 1, 1], minval=-1., maxval=1.)
interpolated = tf.clip_by_value(real + alpha * noise, -1., 1.) # x_hat should be in the space of X
else :
alpha = tf.random_uniform(shape=[self.batch_size, 1, 1, 1], minval=0., maxval=1.)
interpolated = alpha*real + (1. - alpha)*fake
logit, _ = self.discriminator(interpolated, reuse=True, scope=scope)
GP = 0
grad = tf.gradients(logit, interpolated)[0] # gradient of D(interpolated)
grad_norm = tf.norm(flatten(grad), axis=1) # l2 norm
# WGAN - LP
if self.gan_type == 'wgan-lp' :
GP = self.ld * tf.reduce_mean(tf.square(tf.maximum(0.0, grad_norm - 1.)))
elif self.gan_type == 'wgan-gp' or self.gan_type == 'dragan':
GP = self.ld * tf.reduce_mean(tf.square(grad_norm - 1.))
return GP
def build_model(self):
self.lr = tf.placeholder(tf.float32, name='learning_rate')
""" Input Image"""
Image_data_class = ImageData(load_size=self.img_size, channels=self.img_ch, data_path=self.dataset_path, selected_attrs=self.selected_attrs, augment_flag=self.augment_flag)
Image_data_class.preprocess()
train_dataset_num = len(Image_data_class.train_dataset)
test_dataset_num = len(Image_data_class.test_dataset)
train_dataset = tf.data.Dataset.from_tensor_slices((Image_data_class.train_dataset, Image_data_class.train_dataset_label, Image_data_class.train_dataset_fix_label))
test_dataset = tf.data.Dataset.from_tensor_slices((Image_data_class.test_dataset, Image_data_class.test_dataset_label, Image_data_class.test_dataset_fix_label))
gpu_device = '/gpu:0'
train_dataset = train_dataset.
apply(shuffle_and_repeat(train_dataset_num)).
apply(map_and_batch(Image_data_class.image_processing, self.batch_size, num_parallel_batches=8, drop_remainder=True)).
apply(prefetch_to_device(gpu_device, self.batch_size))
test_dataset = test_dataset.
apply(shuffle_and_repeat(test_dataset_num)).
apply(map_and_batch(Image_data_class.image_processing, self.batch_size, num_parallel_batches=8, drop_remainder=True)).
apply(prefetch_to_device(gpu_device, self.batch_size))
train_dataset_iterator = train_dataset.make_one_shot_iterator()
test_dataset_iterator = test_dataset.make_one_shot_iterator()
self.x_real, label_org, label_fix_list = train_dataset_iterator.get_next() # Input image / Original domain labels
label_trg = tf.random_shuffle(label_org) # Target domain labels
label_fix_list = tf.transpose(label_fix_list, perm=[1, 0, 2])
self.x_test, test_label_org, test_label_fix_list = test_dataset_iterator.get_next() # Input image / Original domain labels
test_label_fix_list = tf.transpose(test_label_fix_list, perm=[1, 0, 2])
self.custom_image = tf.placeholder(tf.float32, [1, self.img_size, self.img_size, self.img_ch], name='custom_image') # Custom Image
custom_label_fix_list = tf.transpose(create_labels(self.custom_label, self.selected_attrs), perm=[1, 0, 2])
""" Define Generator, Discriminator """
x_fake = self.generator(self.x_real, label_trg) # real a
x_recon = self.generator(x_fake, label_org, reuse=True) # real b
real_logit, real_cls = self.discriminator(self.x_real)
fake_logit, fake_cls = self.discriminator(x_fake, reuse=True)
""" Define Loss """
if self.gan_type.__contains__('wgan') or self.gan_type == 'dragan' :
GP = self.gradient_panalty(real=self.x_real, fake=x_fake)
else :
GP = 0
g_adv_loss = generator_loss(loss_func=self.gan_type, fake=fake_logit)
g_cls_loss = classification_loss(logit=fake_cls, label=label_trg)
g_rec_loss = L1_loss(self.x_real, x_recon)
d_adv_loss = discriminator_loss(loss_func=self.gan_type, real=real_logit, fake=fake_logit) + GP
d_cls_loss = classification_loss(logit=real_cls, label=label_org)
self.d_loss = self.adv_weight * d_adv_loss + self.cls_weight * d_cls_loss
self.g_loss = self.adv_weight * g_adv_loss + self.cls_weight * g_cls_loss + self.rec_weight * g_rec_loss
""" Result Image """
self.x_fake_list = tf.map_fn(lambda x : self.generator(self.x_real, x, reuse=True), label_fix_list, dtype=tf.float32)
""" Test Image """
self.x_test_fake_list = tf.map_fn(lambda x : self.generator(self.x_test, x, reuse=True), test_label_fix_list, dtype=tf.float32)
self.custom_fake_image = tf.map_fn(lambda x : self.generator(self.custom_image, x, reuse=True), custom_label_fix_list, dtype=tf.float32)
""" Training """
t_vars = tf.trainable_variables()
G_vars = [var for var in t_vars if 'generator' in var.name]
D_vars = [var for var in t_vars if 'discriminator' in var.name]
self.g_optimizer = tf.train.AdamOptimizer(self.lr, beta1=0.5, beta2=0.999).minimize(self.g_loss, var_list=G_vars)
self.d_optimizer = tf.train.AdamOptimizer(self.lr, beta1=0.5, beta2=0.999).minimize(self.d_loss, var_list=D_vars)
"""" Summary """
self.Generator_loss = tf.summary.scalar("Generator_loss", self.g_loss)
self.Discriminator_loss = tf.summary.scalar("Discriminator_loss", self.d_loss)
self.g_adv_loss = tf.summary.scalar("g_adv_loss", g_adv_loss)
self.g_cls_loss = tf.summary.scalar("g_cls_loss", g_cls_loss)
self.g_rec_loss = tf.summary.scalar("g_rec_loss", g_rec_loss)
self.d_adv_loss = tf.summary.scalar("d_adv_loss", d_adv_loss)
self.d_cls_loss = tf.summary.scalar("d_cls_loss", d_cls_loss)
self.g_summary_loss = tf.summary.merge([self.Generator_loss, self.g_adv_loss, self.g_cls_loss, self.g_rec_loss])
self.d_summary_loss = tf.summary.merge([self.Discriminator_loss, self.d_adv_loss, self.d_cls_loss])
def train(self):
# initialize all variables
tf.global_variables_initializer().run()
# saver to save model
self.saver = tf.train.Saver()
# summary writer
self.writer = tf.summary.FileWriter(self.log_dir + '/' + self.model_dir, self.sess.graph)
# restore check-point if it exits
could_load, checkpoint_counter = self.load(self.checkpoint_dir)
if could_load:
start_epoch = (int)(checkpoint_counter / self.iteration)
start_batch_id = checkpoint_counter - start_epoch * self.iteration
counter = checkpoint_counter
print(" [*] Load SUCCESS")
else:
start_epoch = 0
start_batch_id = 0
counter = 1
print(" [!] Load failed...")
self.sample_dir = os.path.join(self.sample_dir, self.model_dir)
check_folder(self.sample_dir)
# loop for epoch
start_time = time.time()
past_g_loss = -1.
lr = self.init_lr
for epoch in range(start_epoch, self.epoch):
if self.decay_flag :
lr = self.init_lr if epoch < self.decay_epoch else self.init_lr * (self.epoch - epoch) / (self.epoch - self.decay_epoch) # linear decay
for idx in range(start_batch_id, self.iteration):
train_feed_dict = {
self.lr : lr
}
# Update D
_, d_loss, summary_str = self.sess.run([self.d_optimizer, self.d_loss, self.d_summary_loss], feed_dict = train_feed_dict)
self.writer.add_summary(summary_str, counter)
# Update G
g_loss = None
if (counter - 1) % self.n_critic == 0 :
real_images, fake_images, _, g_loss, summary_str = self.sess.run([self.x_real, self.x_fake_list, self.g_optimizer, self.g_loss, self.g_summary_loss], feed_dict = train_feed_dict)
self.writer.add_summary(summary_str, counter)
past_g_loss = g_loss
# display training status
counter += 1
if g_loss == None :
g_loss = past_g_loss
print("Epoch: [%2d] [%5d/%5d] time: %4.4f d_loss: %.8f, g_loss: %.8f" % (epoch, idx, self.iteration, time.time() - start_time, d_loss, g_loss))
if np.mod(idx+1, self.print_freq) == 0 :
real_image = np.expand_dims(real_images[0], axis=0)
fake_image = np.transpose(fake_images, axes=[1, 0, 2, 3, 4])[0] # [bs, c_dim, h, w, ch]
save_images(real_image, [1, 1],
'./{}/real_{:03d}_{:05d}.png'.format(self.sample_dir, epoch, idx+1))
save_images(fake_image, [1, self.c_dim],
'./{}/fake_{:03d}_{:05d}.png'.format(self.sample_dir, epoch, idx+1))
if np.mod(idx + 1, self.save_freq) == 0:
self.save(self.checkpoint_dir, counter)
# After an epoch, start_batch_id is set to zero
# non-zero value is only for the first epoch after loading pre-trained model
start_batch_id = 0
# save model for final step
self.save(self.checkpoint_dir, counter)
@property
def model_dir(self):
n_res = str(self.n_res) + 'resblock'
n_dis = str(self.n_dis) + 'dis'
return "{}_{}_{}_{}_{}".format(self.model_name, self.dataset_name,
self.gan_type,
n_res, n_dis)
def save(self, checkpoint_dir, step):
checkpoint_dir = os.path.join(checkpoint_dir, self.model_dir)
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
self.saver.save(self.sess, os.path.join(checkpoint_dir, self.model_name + '.model'), global_step=step)
def load(self, checkpoint_dir):
import re
print(" [*] Reading checkpoints...")
checkpoint_dir = os.path.join(checkpoint_dir, self.model_dir)
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
ckpt_name = os.path.basename(ckpt.model_checkpoint_path)
self.saver.restore(self.sess, os.path.join(checkpoint_dir, ckpt_name))
counter = int(next(re.finditer("(d+)(?!.*d)", ckpt_name)).group(0))
print(" [*] Success to read {}".format(ckpt_name))
return True, counter
else:
print(" [*] Failed to find a checkpoint")
return False, 0
def test(self):
tf.global_variables_initializer().run()
test_path = os.path.join(self.dataset_path, 'test')
check_folder(test_path)
test_files = glob(os.path.join(test_path, '*.*'))
self.saver = tf.train.Saver()
could_load, checkpoint_counter = self.load(self.checkpoint_dir)
self.result_dir = os.path.join(self.result_dir, self.model_dir)
check_folder(self.result_dir)
image_folder = os.path.join(self.result_dir, 'images')
check_folder(image_folder)
if could_load :
print(" [*] Load SUCCESS")
else :
print(" [!] Load failed...")
# write html for visual comparison
index_path = os.path.join(self.result_dir, 'index.html')
index = open(index_path, 'w')
index.write("<html><body><table><tr>")
index.write("<th>name</th><th>input</th><th>output</th></tr>")
# Custom Image
for sample_file in test_files:
print("Processing image: " + sample_file)
sample_image = np.asarray(load_test_data(sample_file, size=self.img_size))
image_path = os.path.join(image_folder, '{}'.format(os.path.basename(sample_file)))
fake_image = self.sess.run(self.custom_fake_image, feed_dict = {self.custom_image : sample_image})
fake_image = np.transpose(fake_image, axes=[1, 0, 2, 3, 4])[0]
save_images(fake_image, [1, self.c_dim], image_path)
index.write("<td>%s</td>" % os.path.basename(image_path))
index.write("<td><img src='%s' width='%d' height='%d'></td>" % (sample_file if os.path.isabs(sample_file) else (
'../..' + os.path.sep + sample_file), self.img_size, self.img_size))
index.write("<td><img src='%s' width='%d' height='%d'></td>" % (image_path if os.path.isabs(image_path) else (
'../..' + os.path.sep + image_path), self.img_size * self.c_dim, self.img_size))
index.write("</tr>")
# CelebA
real_images, fake_images = self.sess.run([self.x_test, self.x_test_fake_list])
fake_images = np.transpose(fake_images, axes=[1, 0, 2, 3, 4])
for i in range(len(real_images)) :
print("{} / {}".format(i, len(real_images)))
real_path = os.path.join(image_folder, 'real_{}.png'.format(i))
fake_path = os.path.join(image_folder, 'fake_{}.png'.format(i))
real_image = np.expand_dims(real_images[i], axis=0)
fake_image = fake_images[i]
save_images(real_image, [1, 1], real_path)
save_images(fake_image, [1, self.c_dim], fake_path)
index.write("<td>%s</td>" % os.path.basename(real_path))
index.write("<td><img src='%s' width='%d' height='%d'></td>" % (real_path if os.path.isabs(real_path) else (
'../..' + os.path.sep + real_path), self.img_size, self.img_size))
index.write("<td><img src='%s' width='%d' height='%d'></td>" % (fake_path if os.path.isabs(fake_path) else (
'../..' + os.path.sep + fake_path), self.img_size * self.c_dim, self.img_size))
index.write("</tr>")
index.close()6. 主文件main.py
主文件主要是来设置参数和运行程序的,代码为:
from StarGAN import StarGAN
import argparse
from utils import *
"""parsing and configuration"""
def parse_args():
desc = "Tensorflow implementation of StarGAN"
parser = argparse.ArgumentParser(description=desc)
parser.add_argument('--phase', type=str, default='test', help='train or test ?')
parser.add_argument('--dataset', type=str, default='celebA', help='dataset_name')
parser.add_argument('--epoch', type=int, default=20, help='The number of epochs to run')
parser.add_argument('--iteration', type=int, default=10000, help='The number of training iterations')
parser.add_argument('--batch_size', type=int, default=16, help='The size of batch size')
parser.add_argument('--print_freq', type=int, default=1000, help='The number of image_print_freq')
parser.add_argument('--save_freq', type=int, default=1000, help='The number of ckpt_save_freq')
parser.add_argument('--decay_flag', type=str2bool, default=True, help='The decay_flag')
parser.add_argument('--decay_epoch', type=int, default=10, help='decay epoch')
parser.add_argument('--lr', type=float, default=0.0001, help='The learning rate')
parser.add_argument('--ld', type=float, default=10.0, help='The gradient penalty lambda')
parser.add_argument('--adv_weight', type=float, default=1, help='Weight about GAN')
parser.add_argument('--rec_weight', type=float, default=10, help='Weight about Reconstruction')
parser.add_argument('--cls_weight', type=float, default=10, help='Weight about Classification')
parser.add_argument('--gan_type', type=str, default='wgan-gp', help='gan / lsgan / wgan-gp / wgan-lp / dragan / hinge')
parser.add_argument('--selected_attrs', type=str, nargs='+', help='selected attributes for the CelebA dataset',
default=['Black_Hair', 'Blond_Hair', 'Brown_Hair', 'Male', 'Young'])
parser.add_argument('--custom_label', type=int, nargs='+', help='custom label about selected attributes',
default=[1, 0, 0, 0, 0])
# If your image is "Young, Man, Black Hair" = [1, 0, 0, 1, 1]
parser.add_argument('--ch', type=int, default=64, help='base channel number per layer')
parser.add_argument('--n_res', type=int, default=6, help='The number of resblock')
parser.add_argument('--n_dis', type=int, default=6, help='The number of discriminator layer')
parser.add_argument('--n_critic', type=int, default=5, help='The number of critic')
parser.add_argument('--img_size', type=int, default=128, help='The size of image')
parser.add_argument('--img_ch', type=int, default=3, help='The size of image channel')
parser.add_argument('--augment_flag', type=str2bool, default=True, help='Image augmentation use or not')
parser.add_argument('--checkpoint_dir', type=str, default='checkpoint',
help='Directory name to save the checkpoints')
parser.add_argument('--result_dir', type=str, default='results',
help='Directory name to save the generated images')
parser.add_argument('--log_dir', type=str, default='logs',
help='Directory name to save training logs')
parser.add_argument('--sample_dir', type=str, default='samples',
help='Directory name to save the samples on training')
return check_args(parser.parse_args())
"""checking arguments"""
def check_args(args):
# --checkpoint_dir
check_folder(args.checkpoint_dir)
# --result_dir
check_folder(args.result_dir)
# --result_dir
check_folder(args.log_dir)
# --sample_dir
check_folder(args.sample_dir)
# --epoch
try:
assert args.epoch >= 1
except:
print('number of epochs must be larger than or equal to one')
# --batch_size
try:
assert args.batch_size >= 1
except:
print('batch size must be larger than or equal to one')
return args
"""main"""
def main():
# parse arguments
args = parse_args()
if args is None:
exit()
# open session
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True)) as sess:
gan = StarGAN(sess, args)
# build graph
gan.build_model()
# show network architecture
show_all_variables()
if args.phase == 'train':
gan.train()
print(" [*] Training finished!")
if args.phase == 'test':
gan.test()
print(" [*] Test finished!")
if __name__ == '__main__':
main()
四、实验结果
做实验的时候先把状态参数设置为'train',先进行模型的训练,原作者在链接[2]中也给出了自己的训练好的模型,但是需要翻墙下载。
设置好之后就慢慢进入训练,我自己的电脑配置是GTX 1660TI,显存6G,全部训练完的话大概需要1天多,训练一个epoch大概需要2个小时。我训练了一晚上+一下午,共训练了9个epoch,如果训练时loss能够很快下降就说明没问题:
训练完成后就是测试,需要把状态改为'test',然后在'./dataset/celeba/test/'文件夹下放入自己需要测试的图片。下面来看两个例子:
一个是我自己输入的一张图,从左往右依次为[黑发,金发,棕发,男性,年轻]:

另外是一个边训练边测试的例子:
输入的是NBA球星马努年轻时长发飘飘的样子:

输出的是对应的属性【黑发,金发,棕发,异性,年轻】:

最后的训练loss为(我只训练了9个epoch就没训练了):
五、分析
1. 原作者还给出了下载数据集的代码,我没试过,这里也给出:
import os
import zipfile
import argparse
import requests
from tqdm import tqdm
parser = argparse.ArgumentParser(description='Download dataset for StarGAN')
parser.add_argument('dataset', metavar='N', type=str, nargs='+', choices=['celebA'],
help='name of dataset to download [celebA]')
def download_file_from_google_drive(id, destination):
URL = "https://docs.google.com/uc?export=download"
session = requests.Session()
response = session.get(URL, params={'id': id}, stream=True)
token = get_confirm_token(response)
if token:
params = {'id': id, 'confirm': token}
response = session.get(URL, params=params, stream=True)
save_response_content(response, destination)
def get_confirm_token(response):
for key, value in response.cookies.items():
if key.startswith('download_warning'):
return value
return None
def save_response_content(response, destination, chunk_size=32 * 1024):
total_size = int(response.headers.get('content-length', 0))
with open(destination, "wb") as f:
for chunk in tqdm(response.iter_content(chunk_size), total=total_size,
unit='B', unit_scale=True, desc=destination):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
def download_celeb_a(dirpath):
data_dir = 'celebA'
celebA_dir = os.path.join(dirpath, data_dir)
prepare_data_dir(celebA_dir)
file_name, drive_id = "img_align_celeba.zip", "0B7EVK8r0v71pZjFTYXZWM3FlRnM"
txt_name, txt_drive_id = "list_attr_celeba.txt", "0B7EVK8r0v71pblRyaVFSWGxPY0U"
save_path = os.path.join(dirpath, file_name)
txt_save_path = os.path.join(celebA_dir, txt_name)
if os.path.exists(txt_save_path):
print('[*] {} already exists'.format(txt_save_path))
else:
download_file_from_google_drive(drive_id, txt_save_path)
if os.path.exists(save_path):
print('[*] {} already exists'.format(save_path))
else:
download_file_from_google_drive(drive_id, save_path)
with zipfile.ZipFile(save_path) as zf:
zf.extractall(celebA_dir)
# os.remove(save_path)
os.rename(os.path.join(celebA_dir, 'img_align_celeba'), os.path.join(celebA_dir, 'train'))
custom_data_dir = os.path.join(celebA_dir, 'test')
prepare_data_dir(custom_data_dir)
def prepare_data_dir(path='./dataset'):
if not os.path.exists(path):
os.makedirs(path)
if __name__ == '__main__':
args = parser.parse_args()
prepare_data_dir()
if any(name in args.dataset for name in ['CelebA', 'celebA', 'celebA']):
download_celeb_a('./dataset')
2. 我训练的感觉还不够充分,生成的图像质量还是有点模糊,多训练几次应该能够获得较好的结果。
最后
以上就是陶醉白羊最近收集整理的关于对抗生成网络学习(十五)——starGAN实现人脸属性修改(tensorflow实现)一、背景二、starGAN原理三、starGAN实现四、实验结果五、分析的全部内容,更多相关对抗生成网络学习(十五)——starGAN实现人脸属性修改(tensorflow实现)一、背景二、starGAN原理三、starGAN实现四、实验结果五、分析内容请搜索靠谱客的其他文章。








发表评论 取消回复