一 MR 数据压缩
Hadoop三大核心:HDFS(负责存储)、MapReduce(负责计算)、Yarn( 负责调度计算)
Hive基于HDFS存储,Hive计算是将Hql语句转换为MR任务,而MR任务可以对处理的数据进行压缩。所以所谓Hive数据压缩就是MR数据压缩
1、基本含义
MR压缩:通过压缩编码对mapper或者reducer的输出进行压缩,以减少磁盘IO,提高MR程序运行速度,但相应增加了cpu运算负担
压缩特性运用得当能提高性能,但运用不当也可能降低性能。其基本原则是:
- 运算密集型的job,少用压缩
- IO密集型的job,多用压缩
2、压缩编码、算法和对比
MR支持的压缩编码
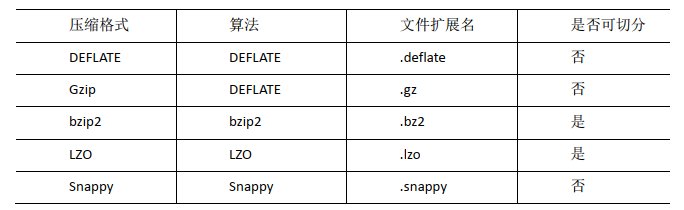
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示:
| 压缩格式 | 对应的编码/解码 |
|---|---|
| DEFAULT | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | org.apache.hadoop.io.compress.GzipCodec |
| Bzip2 | org.apache.hadoop.io.compress.Bzip2Codec |
| LZO | org.hadoop.io.compress.lzo.LzopCodec |
| LZ4 | org.apache.hadoop.io.compress.Lz4pCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩性能的比较:

3、实际操作
map阶段:开启 map 输出阶段压缩可以减少 job 中 map 和 Reduce task 间数据传输量。
-- 开启 hive 中间传输数据压缩功能
set hive.exec.compress.intermediate=true;
-- 开启 mapreduce 中 map 输出压缩功能
set mapreduce.map.output.compress=true;
-- 设置 mapreduce 中 map 输出数据的压缩方式
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;reduce阶段:当Hive将输出写入到表中时,输出内容同样可以进行压缩
-- 开启hive最终输出数据压缩功能
set hive.exec.compress.output=true;
--开启mapreduce最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
--设置mapreduce最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec =org.apache.hadoop.io.compress.SnappyCodec;
--设置mapreduce最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;二、Hive存储数据压缩
1、基本含义
Hive存储格式
texfile:行存储。默认的存储格式。加载速度最快,可采用Gzip进行压缩,压缩后的文件无法split,无法并行处理
sequencefile:行存储。提供的一种二进制存储格式,可以切割,天生压缩。压缩率最低,查询速度一般,将数据存放到sequenceFile格式的hive表中,这时数据就会压缩存储。三种压缩格式NONE,RECORD,BLOCK。是可分割的文件格式
rcfile:行列混合存储,数据按行分块 每块按照列存储。该方式会把相近的行和列数据放在一块儿。压缩率最高,查询速度最快,数据加载最慢
orc:列存储。是rcfile的一种优化存储
parquet:列存储。具有很好的压缩性能,可以指定每一列的压缩方式。同时可以减少大量的表扫描和反序列化的时间
存储效率对比
ORC > Parquet > textFile
更多介绍可参考:
https://www.cnblogs.com/sunpengblog/p/11912958.html
https://blog.csdn.net/qq_35260875/article/details/109196553
2、代码
创建表,存储数据格式为ORC,不设置压缩
create table test(
id int,
content tring
)
row format delimited fields terminated by ','
stored as orc
tblproperties ("orc.compress"="NONE");三 总结
在实际的项目中,hive表的数据存储格式一般选择:orc或parquet。压缩方式一般选择snappy或lzo
创建一个SNAPPY压缩的ORC存储方式
create table log_orc_snappy(
id int,
url string)
row format delimited fields terminated by ','
stored as orc
tblproperties("orc.compress"="SNAPPY");
最后
以上就是聪明吐司最近收集整理的关于Hive数据压缩_MR数据压缩_存储数据压缩的全部内容,更多相关Hive数据压缩_MR数据压缩_存储数据压缩内容请搜索靠谱客的其他文章。








发表评论 取消回复