离线处理流程:
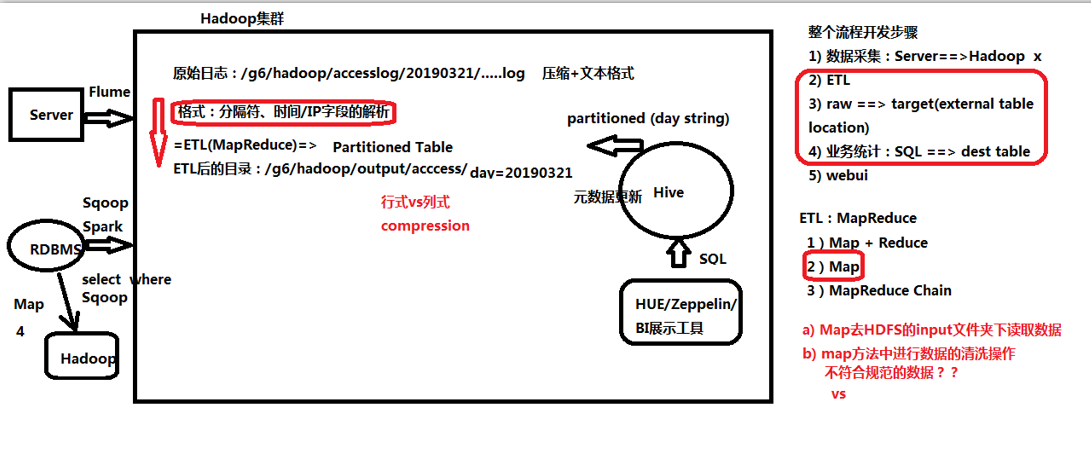
为什么使用压缩
当使用MapReduce经过ETL后落到HDFS上时,若使用普通文本格式TXT ,那一般副本数为三,若一个副本为500T,500*3=1500? 显然是不现实的。
压缩的第一个好处,就是节省我们的磁盘空间,提升磁盘利用率,第二个就是加速我们网络的传输。
缺点:需要占用cpu资源进行压缩与解压,且,压缩与解压需要时间。
!!!所以如果整个集群cpu利用率非常高,不要开压缩;若集群负载不高,强烈建议开压缩。
离线压缩场景
input: Flume Sink HDFS < == Spark/MapReduce ##采用可分片的压缩方式
temp: Sink DISK ## 采用速度快的压缩方式
output: Spark/MapReduce = => Sink Hadoop ## 视情况而定采用
-----------------------
常用压缩格式:
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 | 对应的编码/解码器 |
|---|---|---|---|---|---|
| DEFAULT | 无 | DEFAULT | .deflate | 否 | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | gzip | DEFAULT | .gz | 否 | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | bzip2 | bzip2 | .bz2 | 是 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | lzop | LZO | .lzo | 是(加索引) | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | 无 | LZ4 | .lz4 | 否 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | 无 | Snappy | .snappy | 否 | org.apache.hadoop.io.compress.SnappyCodec |
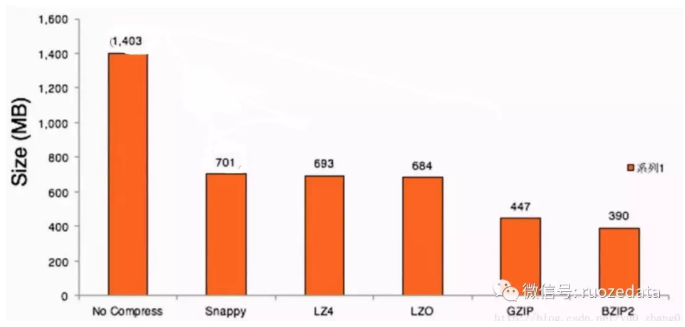
常用压缩格式的压缩比:
压缩时间:
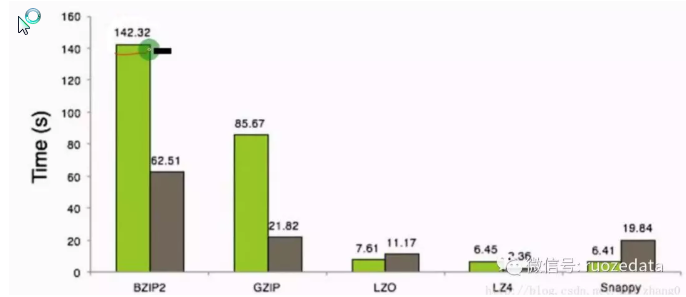
可以看出,压缩比越高,压缩时间越长,压缩比:Snappy<LZ4<LZO<GZIP<BZIP2
a. gzip
优点:
压缩比在四种压缩方式中较高;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;有hadoop native库;大部分linux系统都自带gzip命令,使用方便
缺点:
不支持split
b. lzo
优点:
压缩/解压速度也比较快,合理的压缩率;支持split,是hadoop中最流行的压缩格式;支持hadoop native库;需要在linux系统下自行安装lzop命令,使用方便
缺点:
压缩率比gzip要低;hadoop本身不支持,需要安装;lzo虽然支持split,但需要对lzo文件建索引,否则hadoop也是会把lzo文件看成一个普通文件(为了支持split需要建索引,需要指定inputformat为lzo格式)
c. snappy
优点:
压缩速度快;支持hadoop native库
缺点:
不支持split;压缩比低;hadoop本身不支持,需要安装;linux系统下没有对应的命令
d. bzip2
优点:
支持split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便
缺点:
压缩/解压速度慢;不支持native
配置压缩
core-site.xml
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
<property>##reduce输出采用的压缩
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.BZip2Codec</value>
</property>
<property>##map输出采用的压缩
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
最后
以上就是单身花瓣最近收集整理的关于大数据里常见的几种压缩格式压缩的全部内容,更多相关大数据里常见内容请搜索靠谱客的其他文章。








发表评论 取消回复