目录
一、压缩格式
Hive 数据压缩的优缺点
Hive 压缩格式对应的Hadoop编码/解码器方式
Hive 常见的压缩格式对应的压缩性能比较
扩展下:怎样对压缩模式进行评价?
二、存储格式
Hive 中的 TEXTFILE 文件存储格式
Hive 中的 SequenceFile 文件存储格式
Hive 中的 RCFILE 文件存储格式
Hive 中的常用文件存储格式 ORCFILE
Hive 中的常用文件存储格式 Parquet
什么是行式存储和列式存储
对于 Hive表文件存储方式的一些建议
Hive中 TEXTFILE 文件存储格式使用场景
Hive中 Parquet 文件存储格式使用场景
Hive中 ORC 文件存储格式使用场景
三、总结
Hive 中 ORC 使用案例
Hive 中 ORC+Snappy 使用案例
Hive 中 Parquet+Snappy 使用案例
实际工作中对于Hive存储格式和压缩方式的使用总结
一、压缩格式
Hadoop所支持的文件压缩格式主要是4种,分别是:gzip、lzo、snappy,bzip2
| 压缩方式 | 压缩比 | 压缩速度 | 解压缩速度 | 是否可分割 |
|---|---|---|---|---|
| gzip | 13.4% | 21 MB/s | 118 MB/s | 否 |
| bzip2 | 13.2% | 2.4MB/s | 9.5MB/s | 是 |
| lzo | 20.5% | 135 MB/s | 410 MB/s | 是 |
| snappy | 22.2% | 172 MB/s | 409 MB/s | 否 |
Hive 数据压缩的优缺点
数据压缩优点
减少存储磁盘空间,降低单节点的磁盘IO。由于压缩后的数据占用的带宽更少,因此可以加快数据在Hadoop集群流动的速度。
数据压缩缺点
Hive做大数据分析运行过程中,需要花费额外的时间/CPU做压缩和解压缩计算。
Hive 压缩格式对应的Hadoop编码/解码器方式
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | org.apache.hadoop.io.compress.GzipCodec |
| BZip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compress.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
Hive 常见的压缩格式对应的压缩性能比较
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
On a single core of a Core i7 processor in 64-bit mode, Snappy compresses at about 250 MB/sec or more and decompresses at about 500 MB/sec or more. http://google.github.io/snappy/
扩展下:怎样对压缩模式进行评价?
-
1、压缩比:压缩比越高,压缩后文件越小,所以压缩比越高越好
-
2、压缩时间:越快越好
-
3、已经压缩的格式文件是否可以再分割:可以分割的格式允许单一文件由多个Mapper程序处理,可以更好的并行化
二、存储格式
Hive支持的存储数据的格式主要有:TEXTFILE 文本格式文件(行式存储)、 SEQUENCEFILE 二进制序列化文件(行式存储)、ORC(列式存储)、PARQUET(列式存储)等。
Hive 中的 TEXTFILE 文件存储格式
TEXTFILE 是 Hive 默认文件存储方式,存储方式为行存储,数据不做压缩,磁盘开销大,数据解析开销大,数据不支持分片,数据加载导入方式可以通过LOAD和INSERT两种方式加载数据。
可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用gzip方式,hive不会对数据进行切分,从而无法对数据进行并行操作,但压缩后的文件不支持split。在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
建表语句是:stored as textfile
Hive 中的 SequenceFile 文件存储格式
Hadoop API提供的一种二进制文件,以key-value的形式序列化到文件中,存储方式为行式存储,sequencefile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,RECORD是默认选项,通常BLOCK会带来较RECORD更好的压缩性能,自身支持切片。Hive中间表以SequenceFile保存,可以节约序列化和反序列化的时间
数据加载导入方式可以通过INSERT方式加载数据,现阶段基本上不用。。。
建表语句是:sorted as sequencefile
Hive 中的 RCFILE 文件存储格式
一种行列存储相结合的存储方式,基本被ORCFILE替代
建表语句是:sorted as rcfile
Hive 中的常用文件存储格式 ORCFILE
ORCFile是RCFile的优化版本,hive特有的数据存储格式,存储方式为行列存储,具体操作是将数据按照行分块,每个块按照列存储,其中每个块都存储有一个索引,自身支持切片,数据加载导入方式可以通过INSERT方式加载数据。
自身支持两种压缩ZLIB和SNAPPY,其中ZLIB压缩率比较高,常用于数据仓库的ODS层,SNAPPY压缩和解压的速度比较快,常用于数据仓库的DW层
相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。
建表语句是:sorted as orc
Hive 中的常用文件存储格式 Parquet
Parquet 是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目。
是一个面向列的二进制文件格式,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。Parquet对于大型查询的类型是高效的。对于扫描特定表格中的特定列的查询,Parquet特别有用。Parquet一般使用Snappy、Gzip压缩,默认是Snappy。
建表语句是:sorted as Parquet
什么是行式存储和列式存储
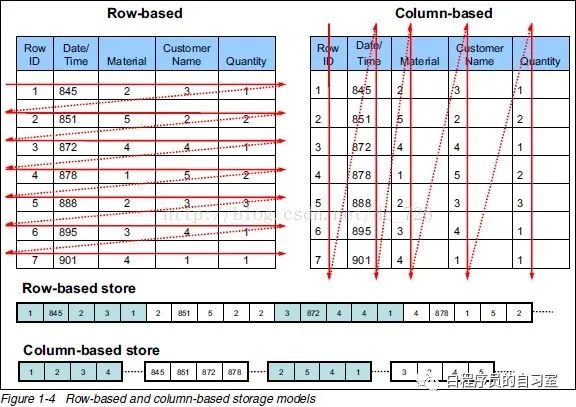
行式存储和列式存储示意图
上图中左边为行存储,右边为列存储:
行存储的特点:查询满足条件的一整行数据时,列式存储则需要去每个聚集的字段找到对应的每列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询数据更快。
列式存储的特点:查询满足条件的一整列数据的时候,行存储则需要去每个聚集的字段找到对应的每个行的值,列存储只需要找到其中一个值,其余的值都在相邻的地方,所以此时列式查询的速度更快。另一方面,每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的压缩算法
行式存储和列式存储的分别使用场景和优缺点
当查询结果为一整行的时候,行存储效率会高一些;当查询表中某几列时,列存储的效率会更高。在对数据的压缩方面,列存储比行存储更有优势,所以列存储占用空间相对小一些
对于 Hive表文件存储方式的一些建议
目前针对存储格式的选择上,主要由TEXTFILE、ORC、Parquet等数据格式。
Hive中 TEXTFILE 文件存储格式使用场景
TEXTFILE主要使用场景在数据贴源层 ODS 或 STG 层,针对需要使用脚本load加载数据到Hive数仓表中的情况。
Hive中 Parquet 文件存储格式使用场景
Parquet 主要使用场景在Impala和Hive共享数据和元数据的场景。
Parquet的核心思想是使用“record shredding and assembly algorithm”来表示复杂的嵌套数据类型,同时辅以按列的高效压缩和编码技术,实现降低存储空间,提高IO效率,降低上层应用延迟。Parquet是语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件。
能够与Parquet配合的组件有:
| 组件类型 | 组件 |
|---|---|
| 查询引擎 | Hive、Impala、Pig |
| 计算框架 | MapReduce、Spark、Cascading |
| 数据模型 | Avro、Thrift、Protocol Buffers、POJOs |
Hive中 ORC 文件存储格式使用场景
ORC文件格式可以提供一种高效的方法来存储Hive数据,运用ORC可以提高Hive的读、写以及处理数据的性能,但如果有以下两种场景可以考虑不使用ORC,文本文件加载到ORC格式的Hive表的场景及Hive表作为计算结果数据。
文本文件加载到ORC格式的Hive表的场景:由于文本格式到ORC,需要耗费较高的CPU计算资源,相比于直接落地成文本格式Hive表而言加载性能会低很多;
Hive表作为计算结果数据,导出给Hadoop之外的外部系统读取使用的场景:ORC格式的结果数据,相比于文本格式的结果数据而言其易读性低很多。
除此之外,其他场景均建议使用ORC作为Hive表的存储格式,作者公司的中台默认存储格式就是ORC.
三、总结
Hive 中 ORC 使用案例
--SQL 建表语句
CREATE TABLE temperature_orc(id string,year string,temperature int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS ORC
TBLPROPERTIES ("orc.compress"="NONE");
--备注:orc.compress不能不设置NONE,因为默认值为ZLIB压缩
-- 加载数据
insert overwrite table temperature_orc
select id,year,temperature from temperature;
Hive 中 ORC+Snappy 使用案例
-- SQL 建表语句
CREATE TABLE temperature_orc_snappy(id string,year string,temperature int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY");
-- 加载数据
insert overwrite table temperature_orc_snappy
select id,year,temperature from temperature;
-- 查看结果
select * from temperature_orc_snappy;
Hive 中 Parquet+Snappy 使用案例
-- SQL 建表语句
CREATE TABLE temperature_parquet_snappy(id string,year string,temperature int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS PARQUET
tblproperties("parquet.compression"="SNAPPY");
-- 配置压缩的另外一种方式:命令行执行set parquet.compression=snappy;
--- 加载数据
insert overwrite table temperature_parquet_snappy
select id,year,temperature from temperature;
-- 查看结果
SELECT * FROM temperature_parquet_snappy;实际工作中对于Hive存储格式和压缩方式的使用总结
实际工作中对于Hive存储格式和压缩方式的使用需要根据场景和需求来定,如果是数据源的话,采用TEXTfile的方式,这样可以很大程度上节省磁盘空间;
而在计算的过程中,为了不影响执行的速度,可以浪费一点磁盘空间,建议采用RCFile+snappy的方式,这样可以整体提升hive的执行速度。针对很多文章中说的lzo的方式,也可以在计算过程中使用,只不过综合考虑(速度和压缩比)的话还是建议snappy。
最后稍作总结,在实际的项目开发当中,hive表的数据存储格式一般选择:orc或parquet。压缩方式一般选择snappy。
但如果文件过大的情况下,使用ORC+SNAPPY会有性能瓶颈:


最后
以上就是清秀野狼最近收集整理的关于Hadoop文件压缩及存储格式的全部内容,更多相关Hadoop文件压缩及存储格式内容请搜索靠谱客的其他文章。








发表评论 取消回复