你好,我是小黄,一名独角兽企业的Java开发工程师。
校招收获数十个offer,年薪均20W~40W。
感谢茫茫人海中我们能够相遇,
俗话说:当你的才华和能力,不足以支撑你的梦想的时候,请静下心来学习,
希望优秀的你可以和我一起学习,一起努力,实现属于自己的梦想。
一、什么是并查集
并查集被很多OIer认为是最简洁而优雅的数据结构之一,主要用于处理一些不相交集合的合并问题,并支持两种操作:
- 合并(Union):把两个不相交的集合合并为一个集合。
- 查询(Find):查询两个元素是否在同一个集合中。
当然,这样的定义让人感觉摸不着头脑,我们来一个样例进行分析。
二、深入理解并查集
在遥远的江湖,有一群武侠人,他们各自为战,守护着自己该守护的东西。
- 1号:擅长刀、武力值98
- 2号:擅长剑、武力值95
- 3号:擅长棍、武力值93
- 4号:擅长枪、武力值90
突然有一天,一个不速之客(小黄)来到了这个江湖,想要称霸江湖,一场腥风血雨的战斗即将拉开序幕。
- 小黄:擅长机关枪、武力值100、宝物:并查集
江湖的局面被五人分割,如下图所示:
- 箭头的含义:自己的大哥(比如2号的箭头指向自己,那2号的大哥就是他自己)

小黄看到其余4人的资料后,使用宝物并查集查询了一下4号和其余几人的关系,发现4号是孤胆一人, 决定从4号先入手。
在一个月黑风高的晚上,小黄拿着机关枪,使用宝物并查集的合并,把4号进行收服,成为其小弟。
1号、2号、3号听闻昨夜4号被收服,立刻举行会议商讨合作的事情,1号由于身高气傲,不想要与另外两人合作,2号、3号只好进行合作。
于是,江湖的局面又发生了变化。
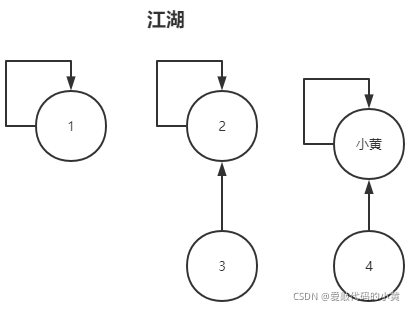
小黄的野心可是称霸江湖,于是使用宝物并查集分别查询了1号、2号、3号的目前状态,得知:1号还是独胆一人,而2、3号已经结盟。
小黄又在一个夜黑风高的晚上与1号大战一夜,最终使用宝物并查集的合并,收服了1号。
至此,江湖只存在两个派系,2号派系、小黄派系。
2号察觉到了目前小黄的势力,主动摆宴,希望江湖不在打打杀杀,能够平安无事。
在宴上,由于2号派系的人数小于小黄派系的人数,于是,2号派系正式被小黄派系吞噬,江湖正式统一。

三、实现并查集
并查集的初始化:
class UnionAndFind() {
// 自己的大哥是谁
private int[] parent;
// 自己的队伍有多少人
private int[] size;
// 江湖还有几个派系
int sets;
// 初始化
// 每个人的大哥都是自己
// 每个队伍的人数都为1
public UnionAndFind(int N) {
parent = new int[N];
size = new int[N];
help = new int[N];
sets = N;
for (int i = 0; i < N; i++) {
parent[i] = i;
size[i] = 1;
}
}
}
并查集的 查询(Find) 方法:这里的时间复杂度可以降低到O(1)级别,不敢相信吧,那就往下看吧。
// 查询a和b在不在一个阵营中
public boolean isSameSet(int a, int b) {
return find(a) == find(b);
}
// 看一下你的最终大哥是谁
public int find(int i){
while(i != parent[i]){
i = parent[i];
}
return i;
}
并查集的 合并(Union)方法:先去找到两个参数的最终大哥,小弟少的大哥跟着小弟多的大哥混
public void union(int a, int b) {
int A = find(a);
int B = find(b);
if (A != B) {
if (size[A] >= size[B]) {
size[A] += size[B];
parent[B] = A;
} else {
size[B] += size[A];
parent[A] = B;
}
sets--;
}
}
四、真题训练
547. 省份数量
初始化数组,拷贝上述并查集即可
public int findCircleNum(int[][] isConnected) {
int N = isConnected.length;
UnionAndFind unionFind = new UnionAndFind(N);
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
if (isConnected[i][j] == 1 && i != j) {
unionFind.union(i, j);
}
}
}
return unionFind.sets;
}

五、路径压缩优化
我们目前的并查集已经可以解决大部分问题,但是,我们能够对目前的并查集版本进行路径压缩优化。
我们可以发现,在我们 find() 方法时,我们会进行一个 while() 循环的查找大哥的操作,这种操作十分的浪费时间,有没有什么办法可以进行下优化呢?
如下所示:

我们可以看到对于6、5、3之类来说,每次进行 find 查询的时候,都需要经过2~3次的循环才能够找到1。
如果我们在进行查找的时候,保存一下值,然后重新挂到1的上面,比如:
我要查询下6,肯定会查询找5、3,这个时候,我们把6、5、3保存到临时数组中,在查询完毕后,将这些数组直接挂到1的下面,这样的话,下次查询会降低循环的次数。

当我们查询的次数远远大于我们的数据量时,这个时候 find() 的操作就已经变成了一个O(1)级别的查询时间。
public int find(int i) {
int h = 0;
while (i != parent[i]) {
help[h++] = i;
i = parent[i];
}
for (h--; h >= 0; h--) {
parent[help[h]] = i;
}
return i;
}
六、总结
并查集算法通常用在处理一些不交集(Disjoint Sets)的合并及查询问题
力扣也有并查集的 tag 专栏:并查集
大家可以好好体会一下路径压缩的奇妙,通过不断的路径压缩,可以将我们的时间复杂度降低到O(1)
这里可能有小伙伴有疑问,为啥是O(1),你就算挂在1的下面,不也得查询两次嘛
对于时间复杂度来说,只要是常数的次数都可以认定为O(1)的时间复杂度,况且,你也可以使用HashMap来进行存储。
以上就是java并查集算法带你领略热血江湖的详细内容,更多关于java并查集算法的资料请关注靠谱客其它相关文章!
最后
以上就是忧心硬币最近收集整理的关于java并查集算法带你领略热血江湖的全部内容,更多相关java并查集算法带你领略热血江湖内容请搜索靠谱客的其他文章。








发表评论 取消回复