XML解析,我们可以通过我们常用的以下代码作为入口

也许,我们习惯使用第一种加载方式,但是以前也存在 第二种加载,并且这两种加载也有差别,下面再来分析。
先分析 第二种 使用 BeanFactory 加载方式
进入到 XMLBeanFactory中看到
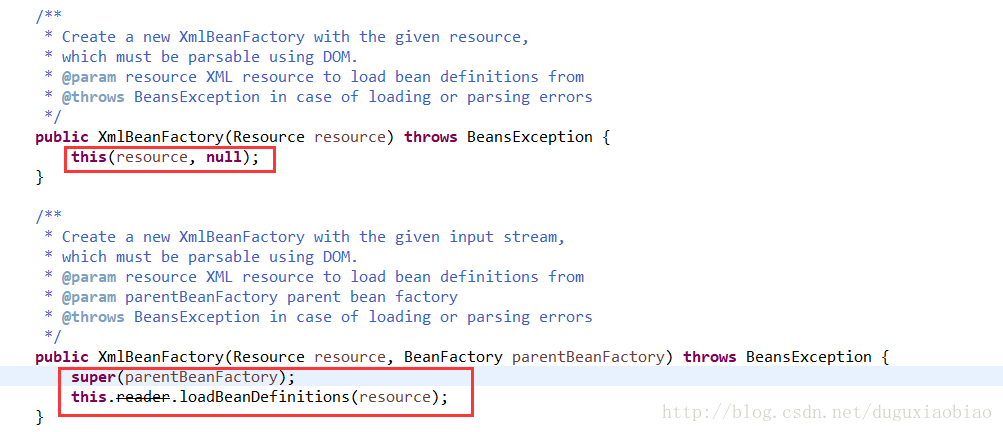
我们到 super(parentBeanFactory); 这个方法中,可以看到有一个操作, ignoreDependencyInterface(.....class)操作
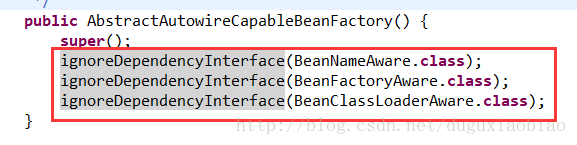
那么 这三个方式是干什么的呢。字面意思来分析是忽略依赖接口,有什么用呢,这里举个例子:当我们有两个类A和B,A中有个属性依赖B,那么在实例化A时,需要B已经实例化,如果没有实例化那么就会开始实例化B,然后在注入到A中,但是如果B在这些忽略依赖接口的集合中的话,此时B就不会实例化。所以一般这些类都是Spring用来特殊处理用的。
跟着主线,再来解析下面的一句 this.reader.loadBeanDefinitions(resource);
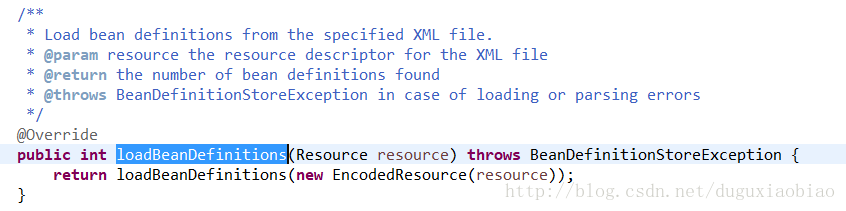
在这里 将Resource对象在封装一下成 EncodeResource对象,在这里可以设置字符集和编码格式,默认为null
下面进入 核心 loadBeanDefinitions方法中
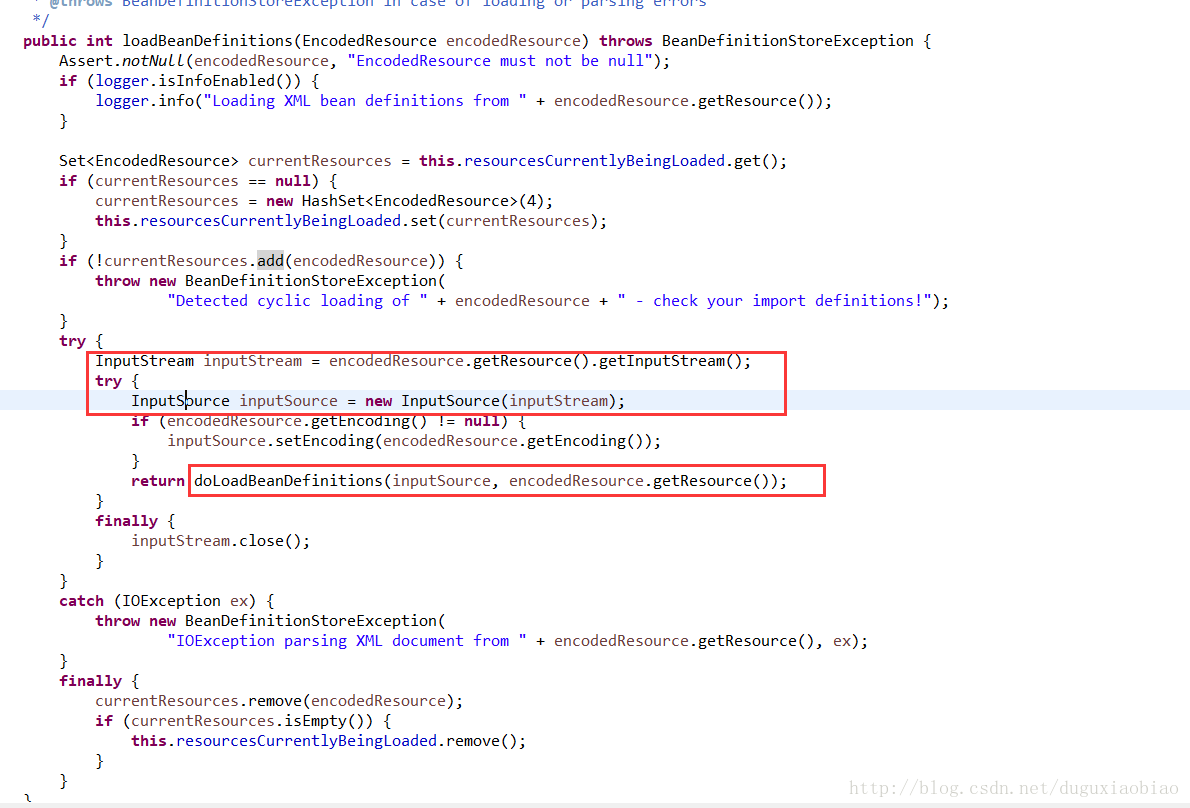
第一步,是将 Resource对象的输入流封装成InputSource对象中的 ByteStream中,以及设置编码。
第二步,是真正开始解析 XML了,下面让我们进入 到 doLoadBeanDefinitions中吧。
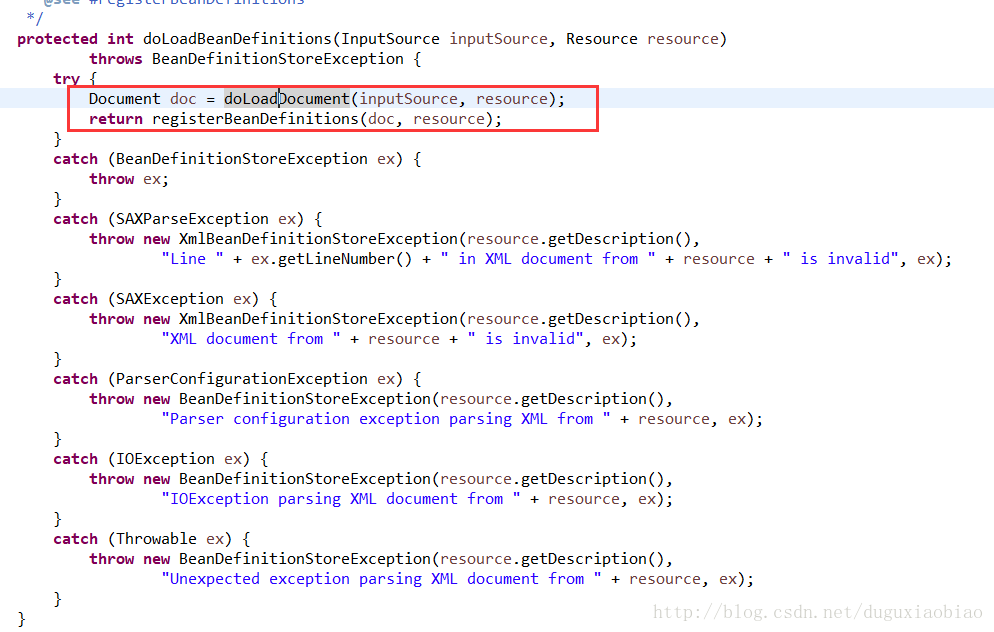
该方法中,涉及到了 两步
第一步,读取流,使用dom4j解析xml,封装成Document对象
第二步,解析xml,注册BeanDefinition对象到工厂中。
现在开始 解析 第一步,进入到 doLoadDocument方法中

在加载xml之前,有一步骤很重要,那就是判断该xml是基于 xsd 还是 dtd 方式,进入到 getValidationModeForResource方法中可以看到
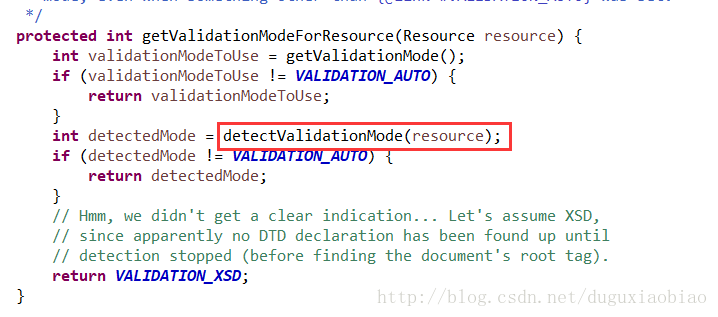
默认的话 通过 getValidationMode()的结果就是 VALIDATION_AUTO,所以进入到我划线方法中
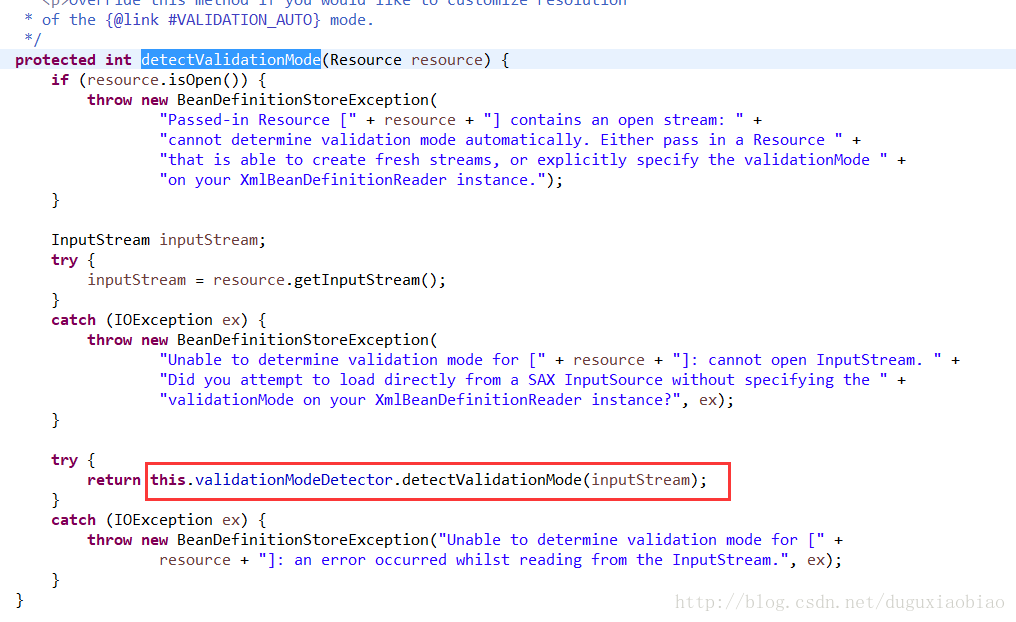
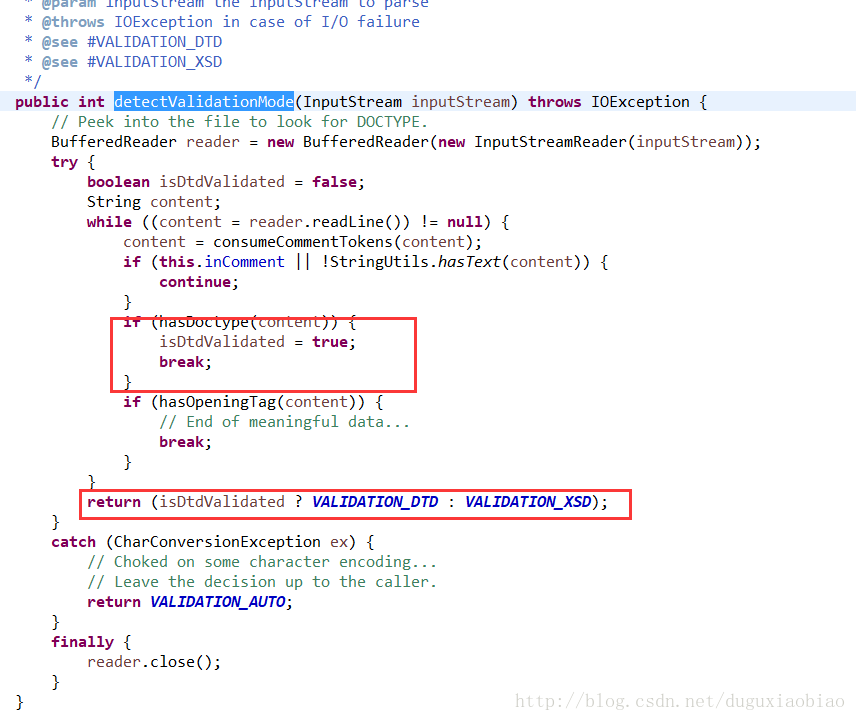
在这个方法中,我们可以看到 如何判断 XML验证是 DTD还是XSD的,说白了就是判断是否是 DOCTYPE 开头的,如果是,那么就用 DTD方式 否则就是 XSD。
当我们获取到了 资源验证模式后,怎个根据不同验证方式来验证呢,我们来分析 getEntityResolver()方法
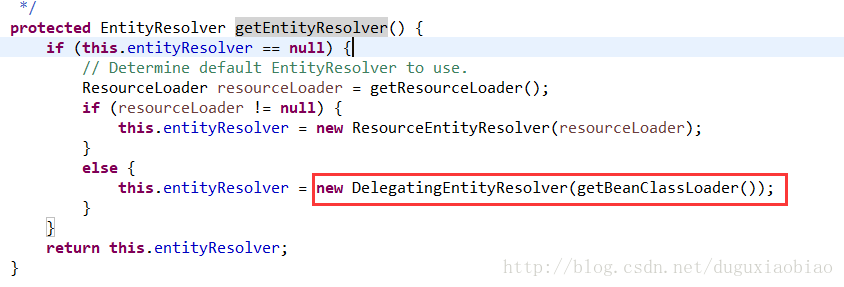
那么EntityResolver这个类作用是什么呢。通过一下例子讲讲

假如是以上声明,我们可以知道不是 <!DOCTYPE>开头,应该使用XSD解析,解析的时候可以获得两个参数 publicId和SystemId,分别是
publicId: null
SystemId: http://www.springframework.org/schema/beans/spring-beans.xsd

假如是以上的声明,应该使用DTD解析,解析的时候可以获取两个参数分别是
publicId: -//Spring//DTD BEAN 2.0//EN
systemId:http://www.springframework.org/dtd/spring-beans-2.0.dtd
我们进入到DelegatingEntityResolver类中查看 resolveEntity()方法
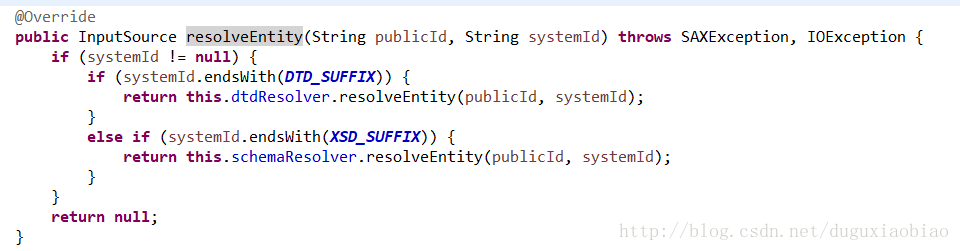
根据systemId的文件后缀来分别使用不同解析器来解析,
如果是dtd解析,则去当前目录下的去找
比如在源码中就存在下面
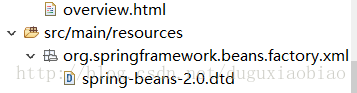
如果是XSD,则会调用 PluggableSchemaResolver类的 resolveEntity()方法来解析,我们可以看到解析过程如下
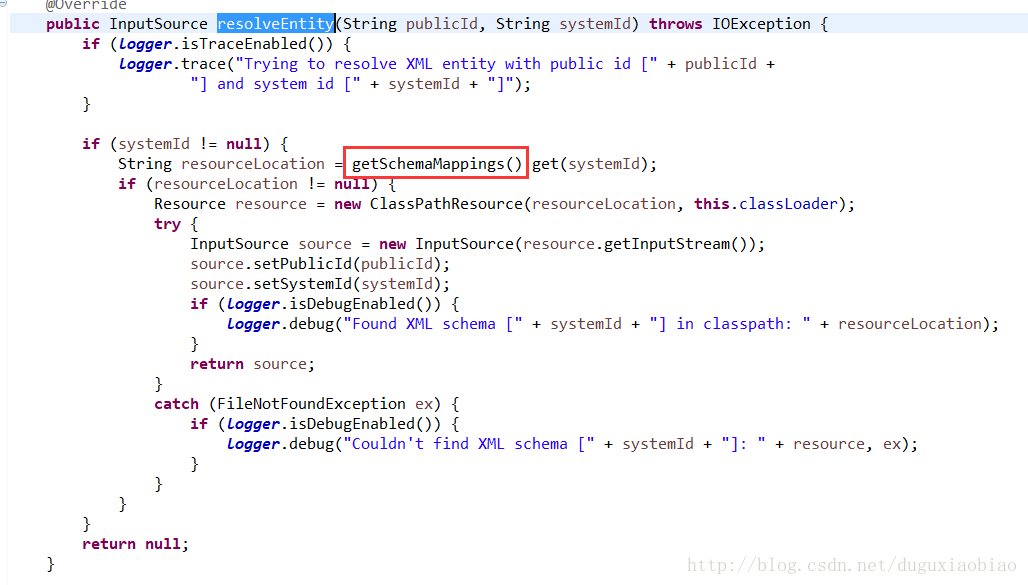
首先看这个方法前,要先看看 这个类有个构造方法如下
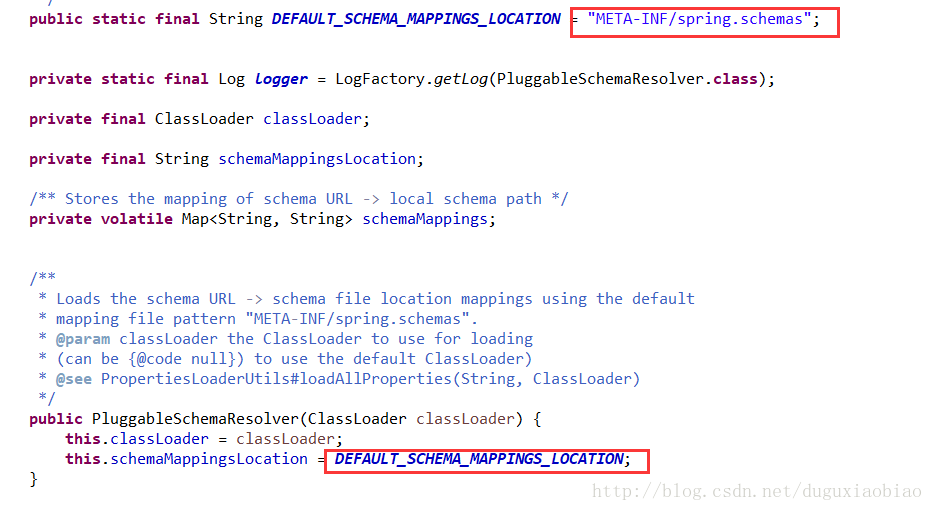
注意这里的路径,然后我们去看 getSchemaMappings()方法
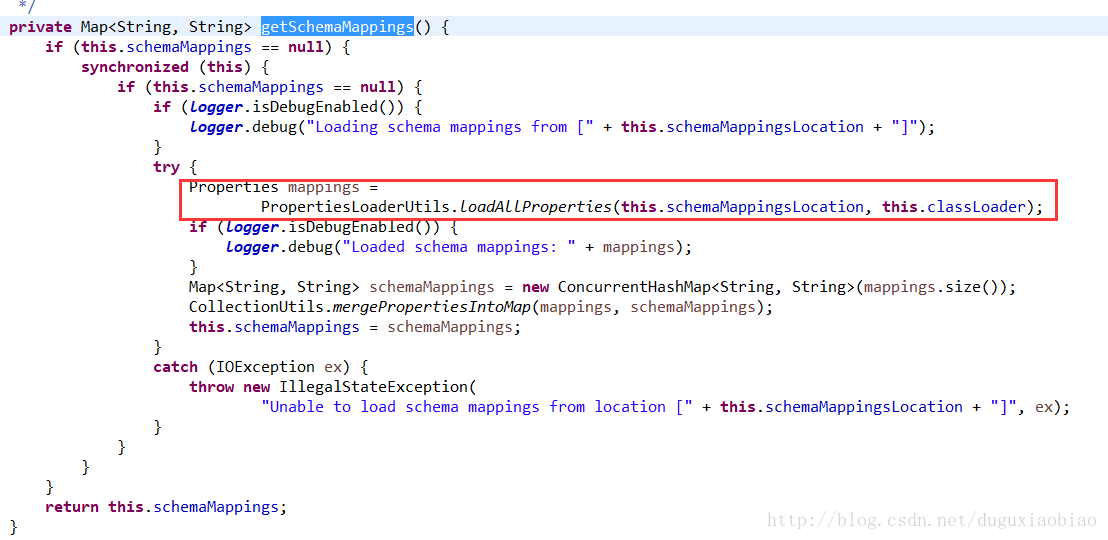
这个方法将 读取 上面的那个路径 META-INF/spring.schemas 下的内容封装成 Properties,然后根据systemId当作key,来返回xsd文件的路径,这种设计真的很精妙,避免的每次都是通过网络来远程访问,避免网络容易中断带来的文件找不到的影响,我们可以看看 spring.schemas文件的内容,都是通过systemId来返回一个路径,这个路径也在resource目录下,可以看到
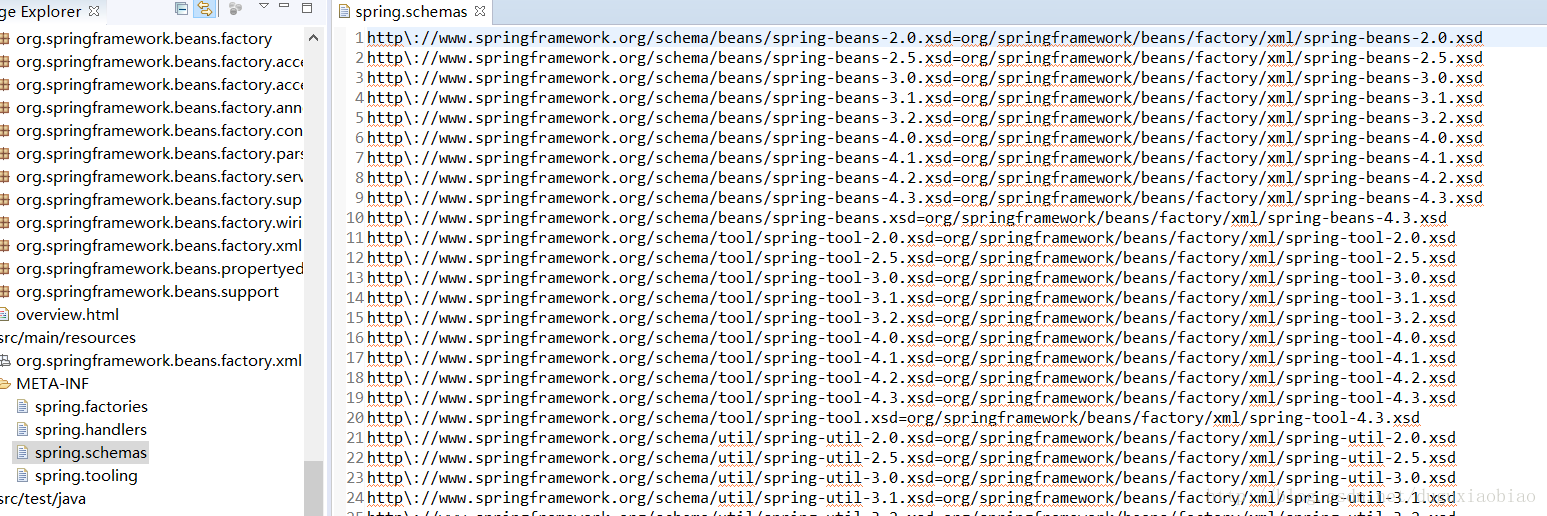
自此,xml的验证就到这里。
回到主线,开始加载xml ,进入到 loadDocument方法中
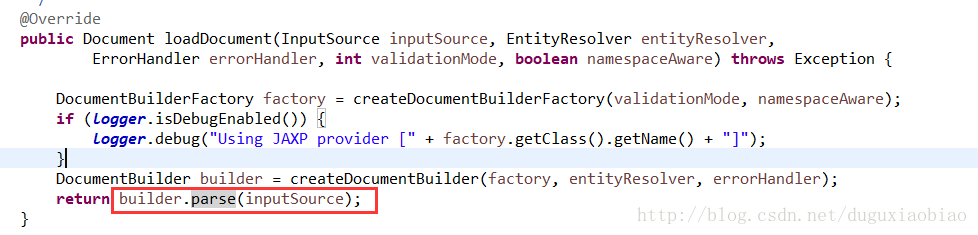
这里用的是 jdk的 dom解析,想深究的就自己看看,这里我们将xml文件解析成了 Document对象,下面就开始解析Document中的每个元素了。
回到主线,进入 registerBeanDefinitions方法中

这个方法中主要做了以下几件事
第一,创建了一个 文档阅读器
第二,解析之前,记录已存在的 BeanDefinition个数
第三,开始解析,注册BeanDefinition
第四,获取最新的BeanDefinition个数,减去之前记录的,就是本次加载xml注册的BeanDefinition的个数了
下面,进入 registerBeanDefinitions方法中
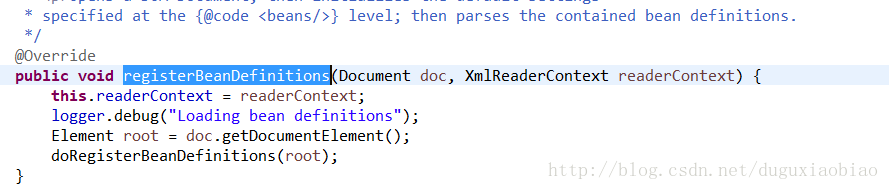
这里首先获取跟节点,也就是 beans节点,然后继续 看下去
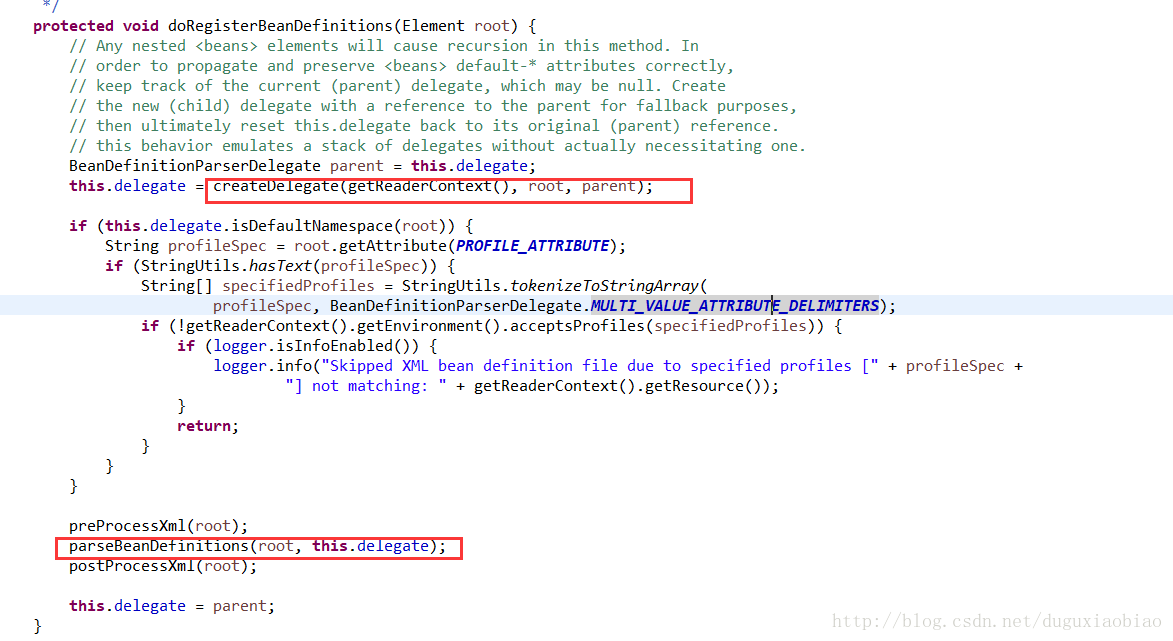
在这个方法中,分析下
第一,创建 BeanDefinitionParserDelegate对象,在 createDelegate()方法中,先创建了对象,然后初始化,那么初始化什么内容呢,起始就是初始化一些 beans标签的一些属性封装到 BeanDefinitionParseDelegate对象中,我们可以去看看
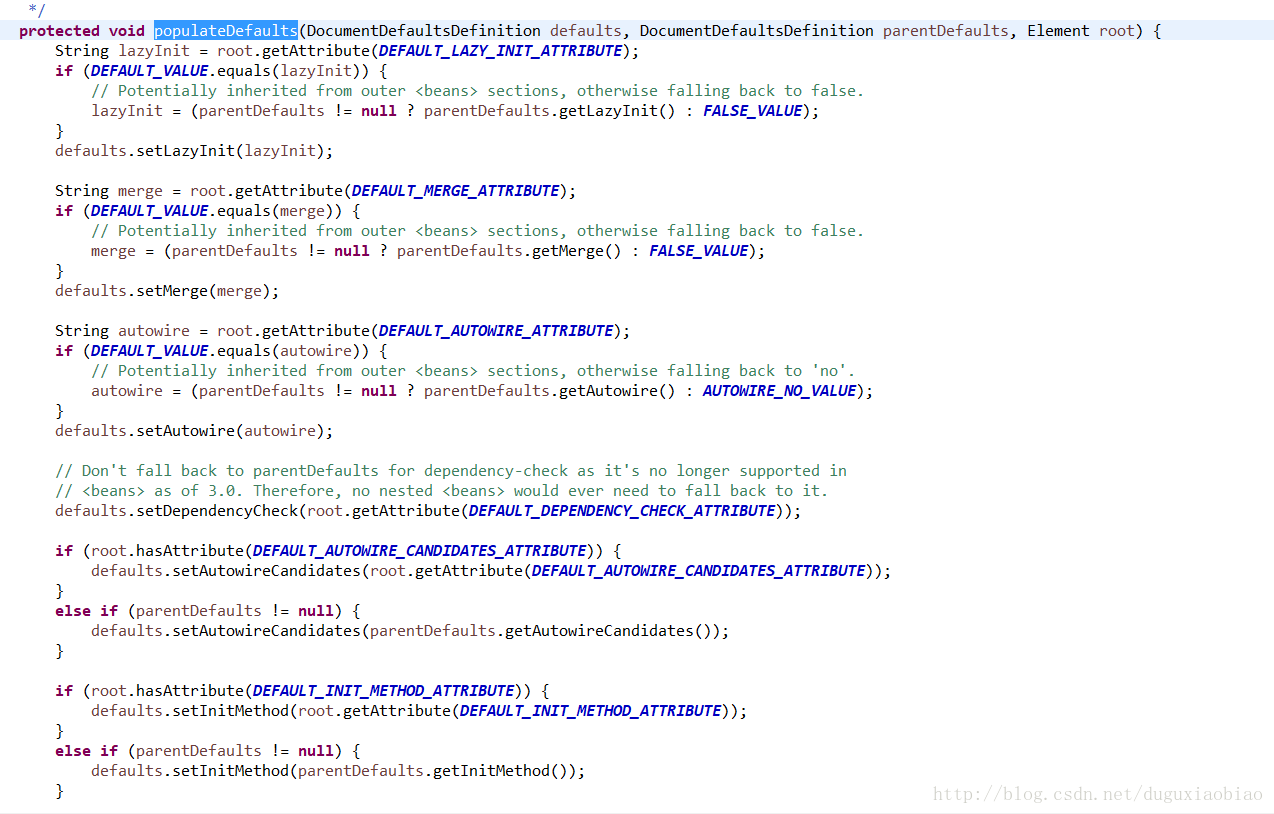
第二,判断是否有 profile属性,这个属性就是为了区别测试和开发环境等类似用法,有兴趣研究的可以看看
第三,开始解析 beanDefinitions了,在其上和下有个两个方法,但是都是空实现,可能是为了以后扩展准备。
下面跟着进入 parseBeanDefinitions()方法中
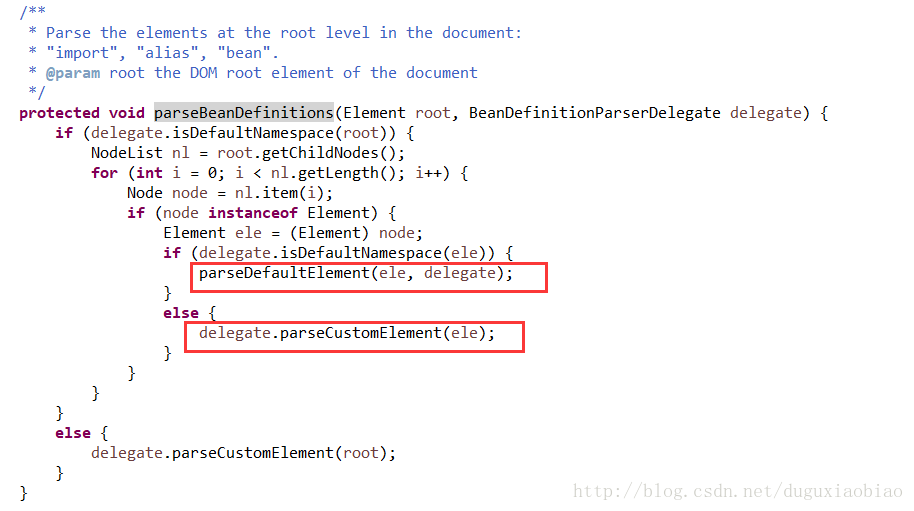
该方法将获取 beans下的所有元素,遍历,判断是否是默认标签元素,默认标签元素有:import、alias、bean、beans等,如果是默认元素,则调用 parseDefaultElement()方法,否则调用自定义元素的解析方法即 parseCustomElement()。下面对默认元素解析以 bean元素解析作为解析,其他大同小异
进入到 parseDefaultElement方法中
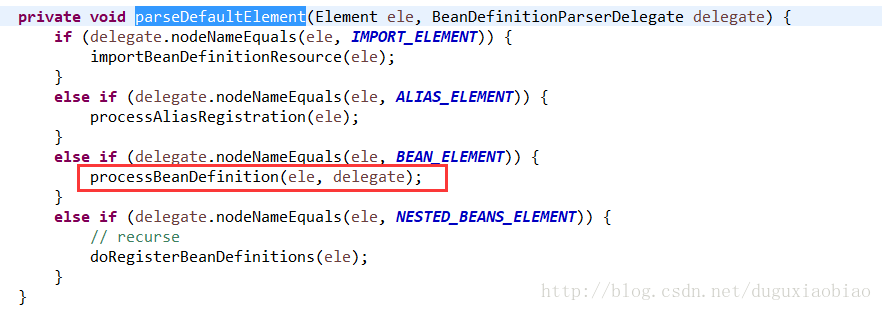
针对bean标签解析,进入 processBeanDefinition中
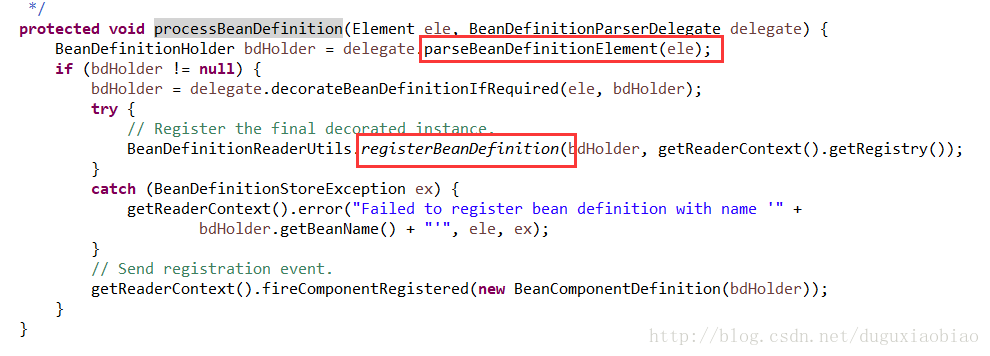
该方法主线有两个方法
第一个,解析bean标签将属性和参数封装成 BeanDefinitionHolder对象
第二个,注册到BeanDefinitionRegistry中
下面先进入 parseBeanDefinitionElement方法中
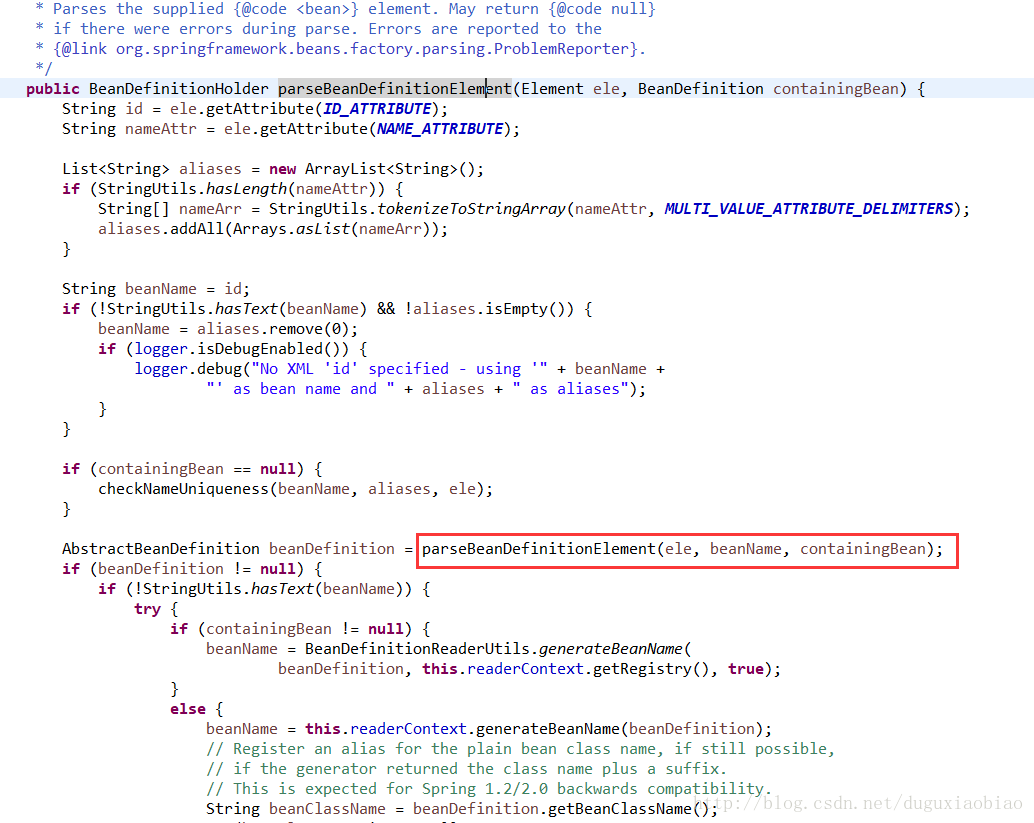
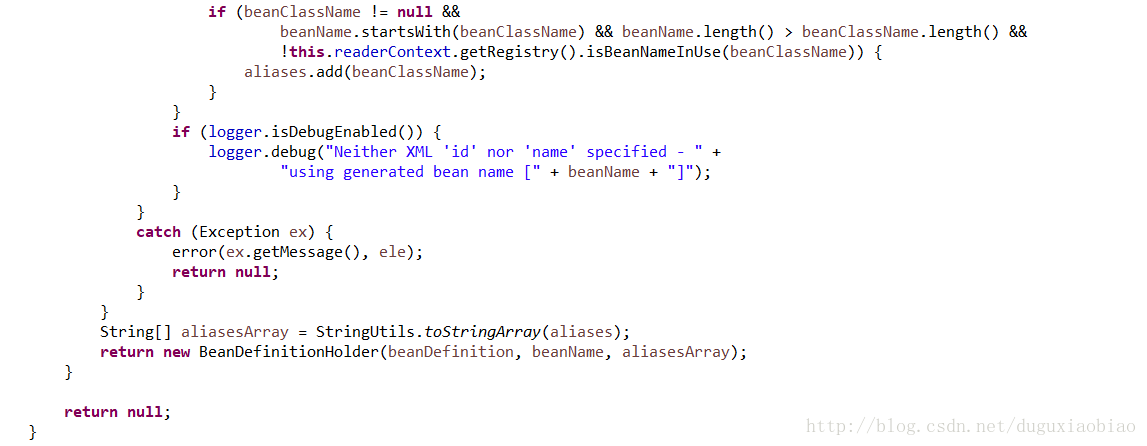
该方法比较长,大致写下实现了什么
第一,获取id和name属性,如果存在id,则 beanName = id,否则没有id只有name的话,就用beanName=别名中的第一个。
第二,验证 beanName是否重复
第三,解析 bean标签内容,包括属性,以及bean标签内的例如 propertiey、list、set、map、构造方法等元素的解析都封装到beanDefinition中
第四,如果该bean没有定义id和name,那么根据spring的规则来自动生成beanName
第五,封装成 BeanDefinitionHolder中
由于解析 篇幅太长,这里就写下主线和思路,各位大佬想更多了解可以输入到 parseBeanDefinitionElement()方法中查看。
回到主线再来看看 registerBeanDefinition()方法
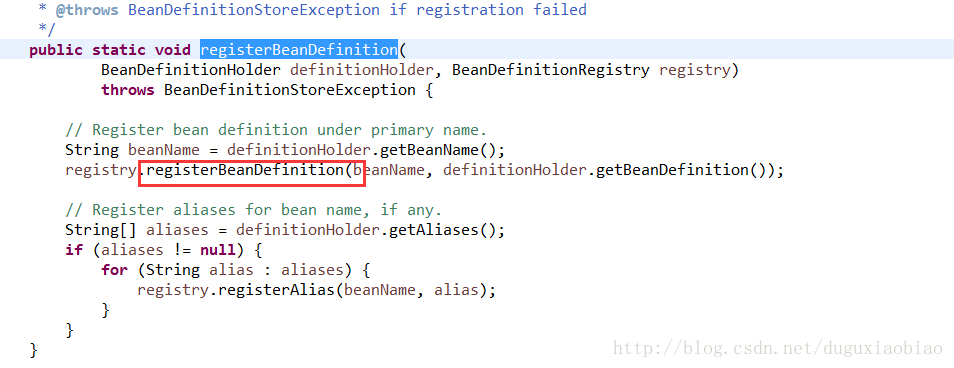
这里就是将 beanDefinition注册到 registry中,以beanName为key存储。
自此,bean标签就解析成了 be'anDefinition对象注册到了 registry中,bean标签解析结束,下面写下自定义元素解析。
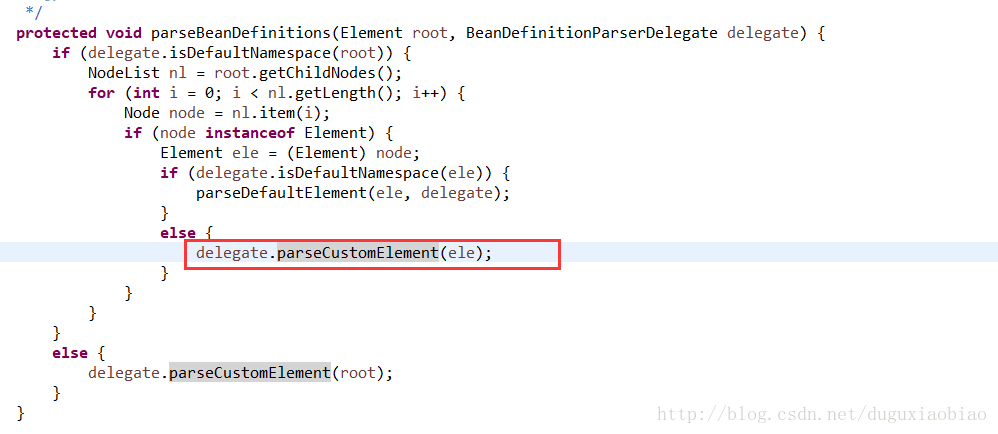
回到这主线来,进入该方法中

可以看到虽然这方法看起来很简单,但是每行代码都很关键,分析下有如下步骤
第一,获取当前标签的对应的 NameSpaceUri,什么意思呢,比如如下解析 context标签时,获取 uri

第二,根据这个Uri获取解析类,这里也很有意思,和获取XSD验证方式类似,进入 resolve方法
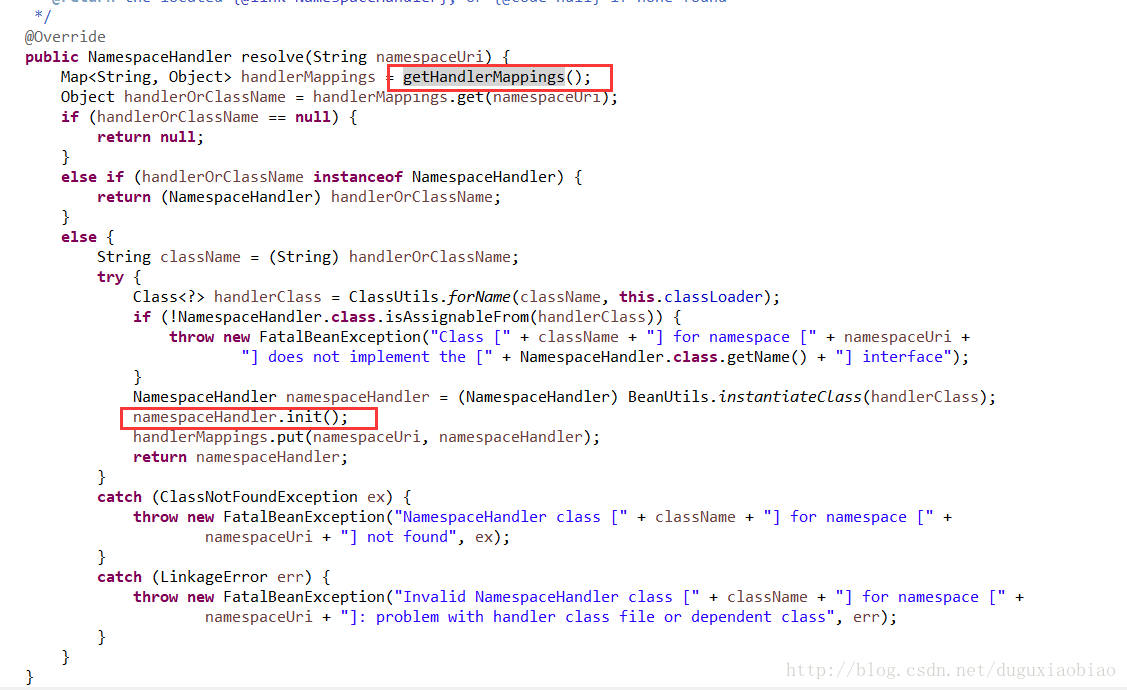
在看这个方法前,同样看看该类的构造
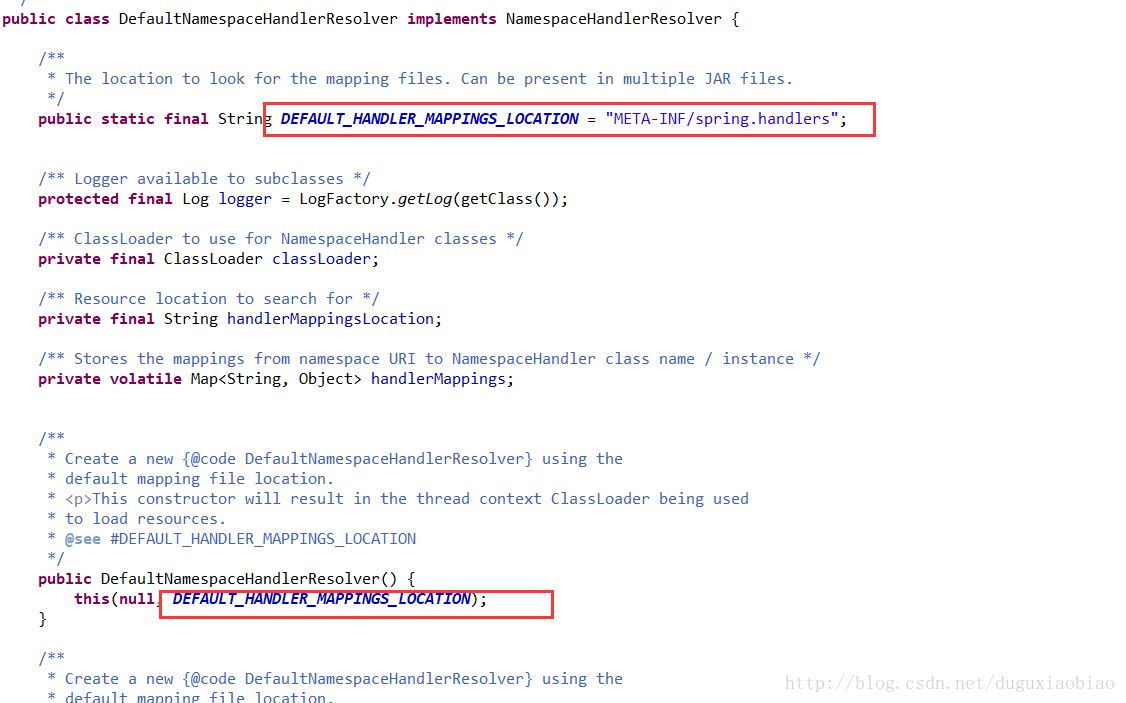
看起来是不是和 上面的 META-INF/spring.schemas很像,对 思路大致一样
同样的在 getHandlerMappings()中会读取 META-INF/spring.handlers 文件,然后根据NameSpaceUri为key获取解析类路径,我们去看看 spring.handlers文件内容,以 <context:component-scan base-package="xx"></context:component-scan>为例,我们解析 context标签,就会去 context工程下得 META-INF下找 spring.schemas文件,文件内容如下:
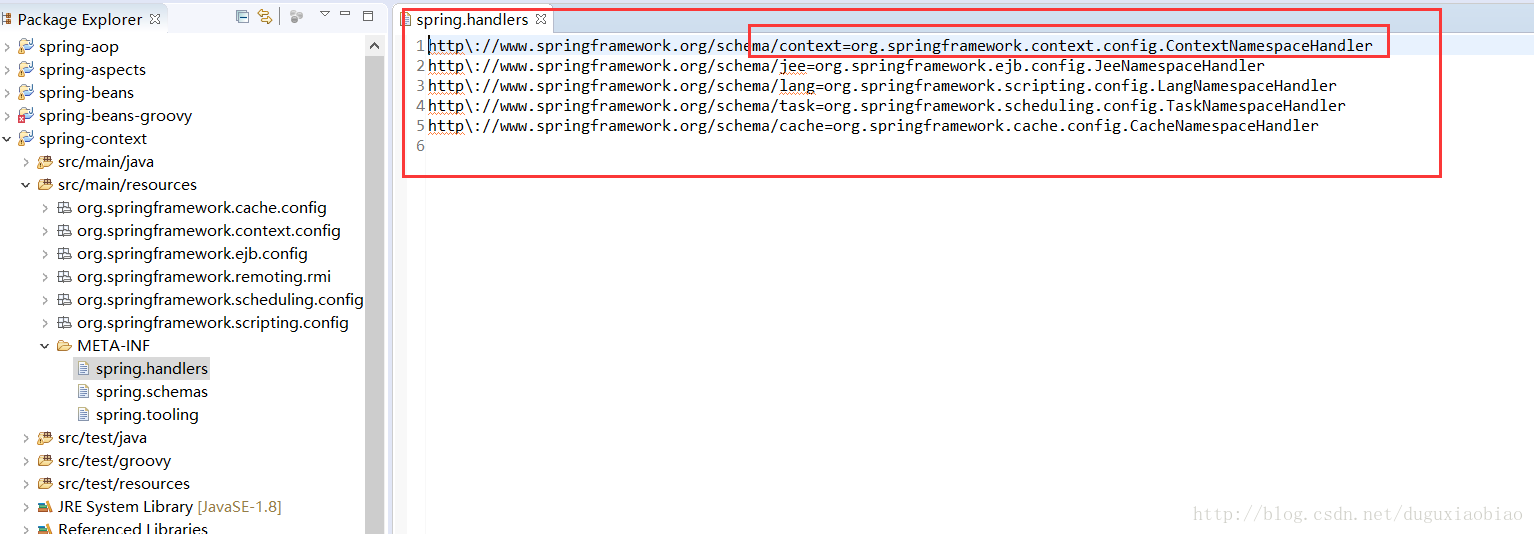
然后通过 context标签对应的uri找到 ContextNamespaceHandler类,这个类中只有一个方法 init(),那么该方法什么时候调用呢,我们继续看,下面的代码中调用了 init()方法,所以 我们看 ContextNamespaceHandler类中的 init()方法。
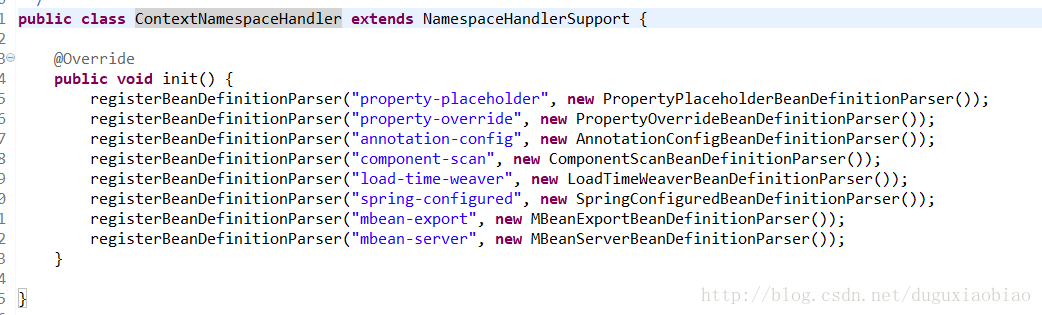
在这个方法中,注册了多个解析器,可以看到,这些key跟我们的熟悉的标签一致。
回到主线,
第三,调用handler的parse方法,进入该方法,
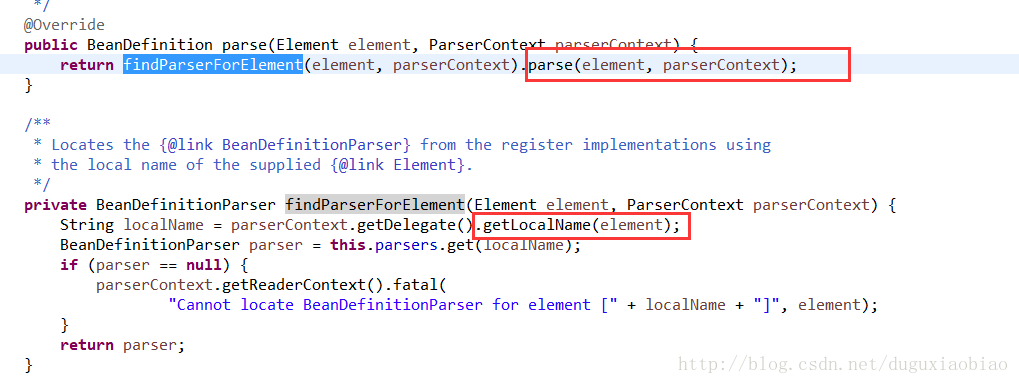
刚才我们通过init方法注入了多个解析器,但是 对于 context:component-scan这个标签有自己的解析器,怎么找到这个解析器呢,就通过以上方法,根据 getLocalName方法获取到 component-scan,然后根据这个key找到 解析器

然后 调用该解析器的 parse方法来解析,至于 对于 这个标签的解析设计到 Annotation注解的注入,我们下个文章讲解,这里主要是说下怎么找到对应的解析器。
那么 对于 第二种加载方式 的解析 就到这里,总结一下,其实只有一个方法:loadBeanDefinitions();
下面来介绍下 第一种 也是最常用的 加载方式 使用 ApplicationContext,下面我们进入到 ClassPathXmlApplicationContext类中看看

这里主要的就是 refresh()方法,进入看看
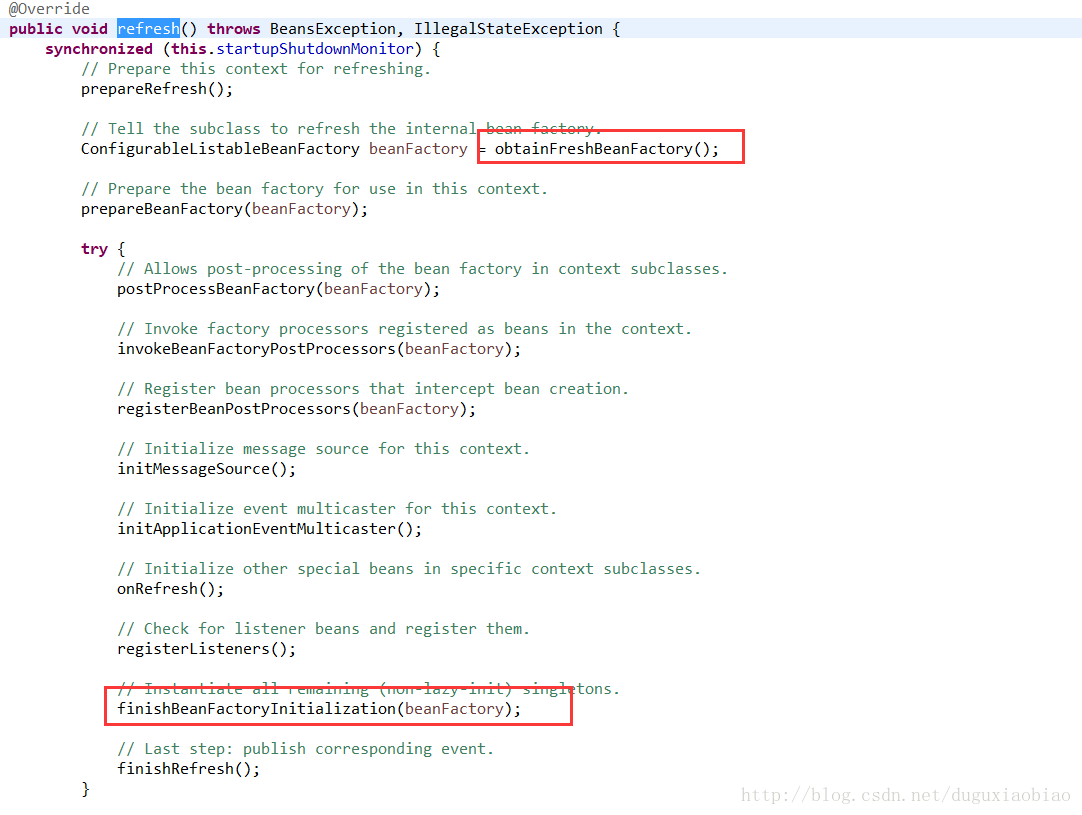
以上方法大致分析如下:
第一,初始化前的准备工作,例如对系统变量或环境变量进行准备和验证
我们进入到 prepareRefresh()方法中
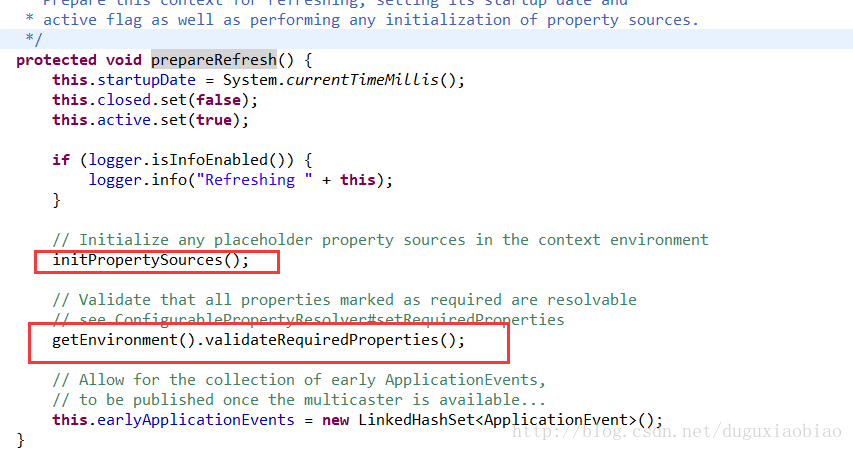
这两个方法看起来没有什么实现,应该这是一个spring的扩展,这里主要是验证环境变量是否存在,我们可以自定义一个ApplicationContext,集成ApplicationContext,重写 initPropertySources()方法,在其中我们可以要求必须存在某个环境变量,然后下一步验证的时候如果缺少某个环境变量时暴露异常。举个例子
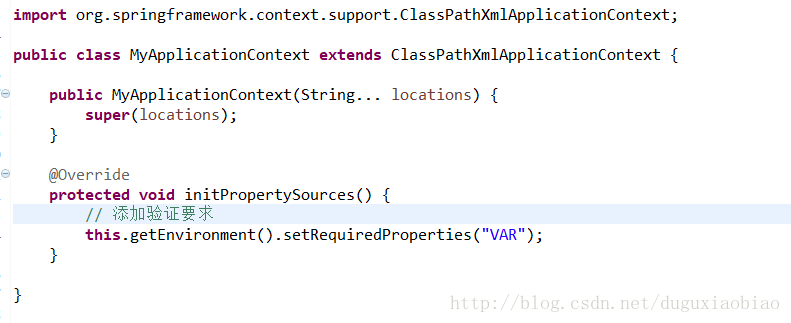
在这个方法里要求必须验证 存在 VAR这个系统变量,如果不存在,则会在 validateRequiredProperties()方法中提示异常。
第二,初始化BeanFactory,加载xml文件解析注册到registry中
我们进入obtainFreshBeanFactory()方法中看看

这里主要是 刷新bean工厂,进入该方法中可以看到我们熟悉的一幕
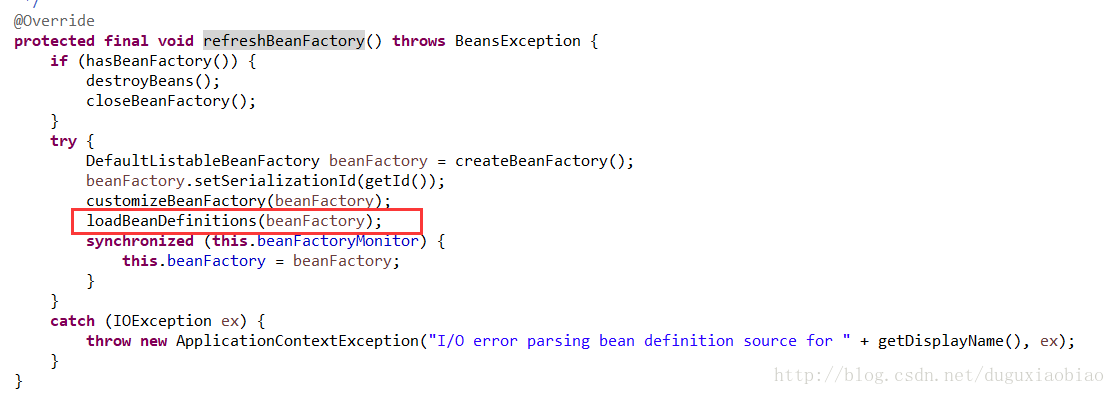
在这里开始加载 xml,解析bean
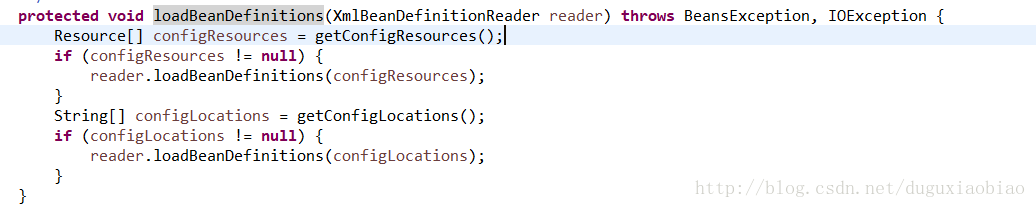
下面的步骤和上面解析xml步骤一致,就不多说了,经过这步后,已经将baen注册到工厂中
第三,xml解析完成,下面就是ApplicationContext中对Spring扩展的支持。
进入到 prepareBeanFactory()方法中
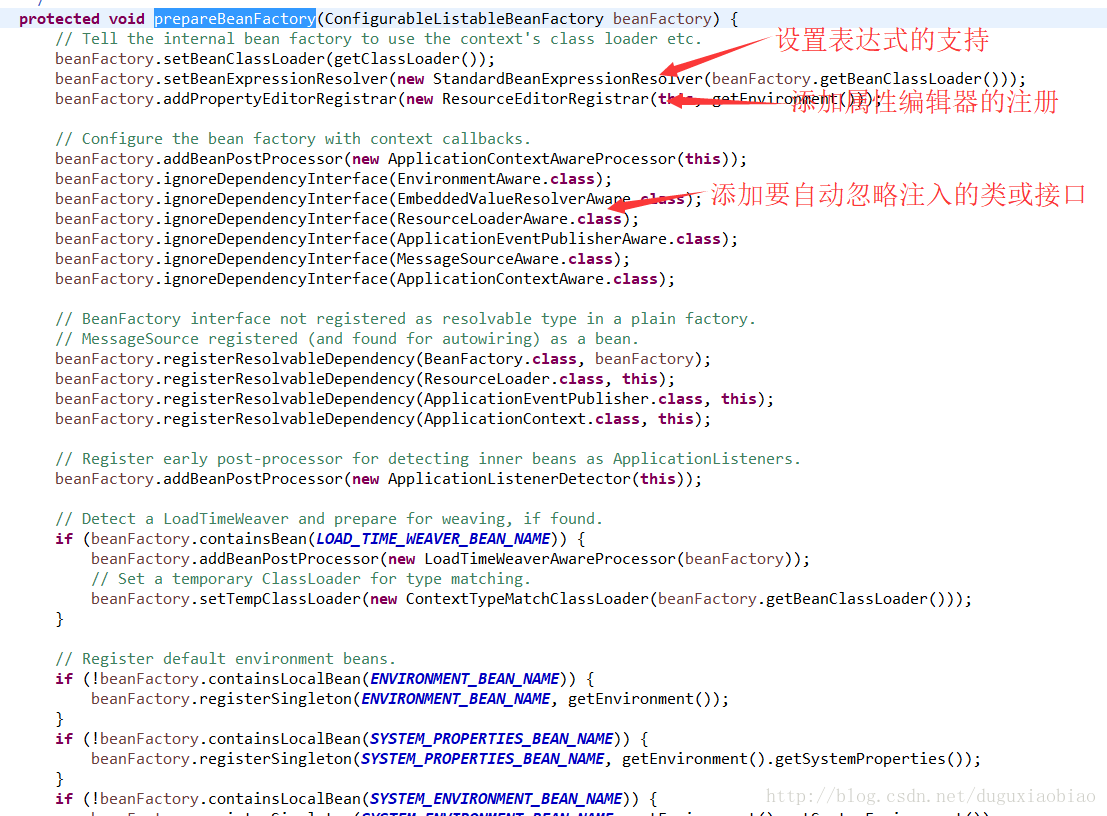
这些扩展在这里不细写了,想了解的可以研究下
第四,激活各种beanFactory处理器
第五,注册拦截bean创建的bean处理器,这里只是注册
第六,为上下文初始化Message源,即国际化处理
第七,初始化应用消息广播器
第八,在所有bean中,找到Listener bean,并将其注册到 消息广播器中
第九,初始化所有非懒加载的bean
我们进入到 finishBeanFactoryInitialization()方法中,核心方法是 beanFactory.preInstantiateSingletons(); 这句代码,这句代码是开始初始化单例bean的入口,我们进去看看
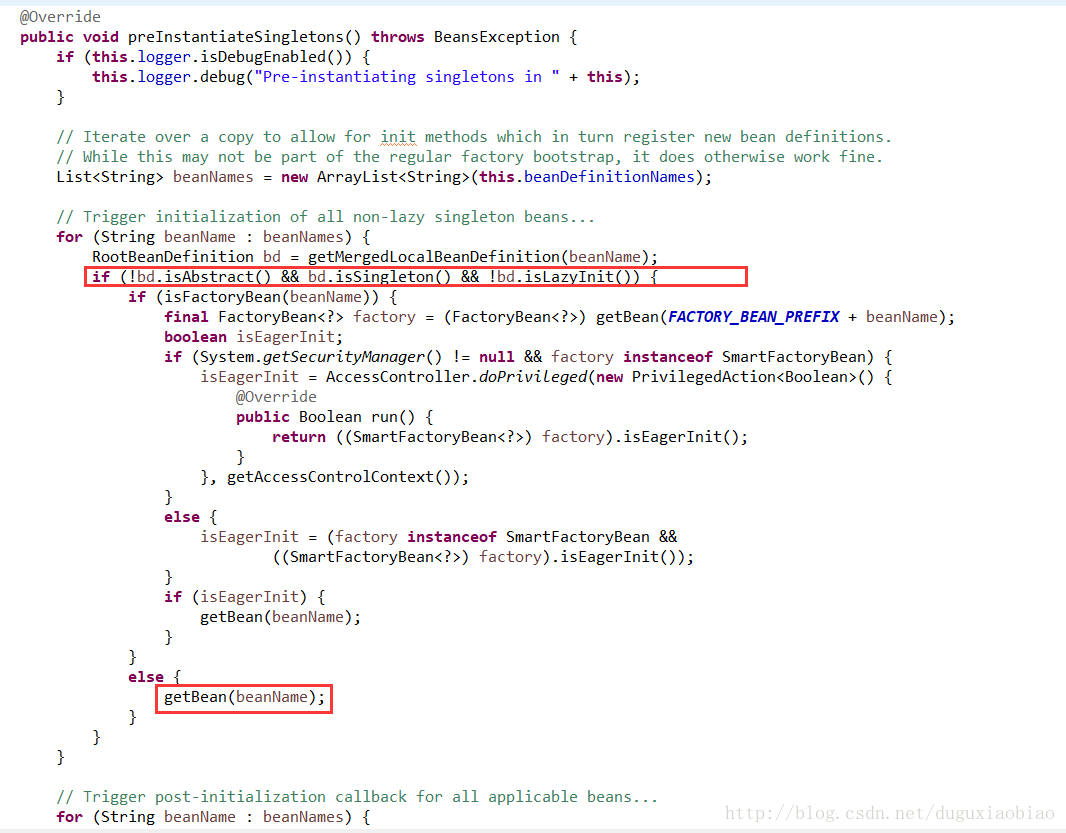
这里可以分析下,步骤如下
一,获取所有beanName,循环,然后根据beanName获得对应的bean
二,判断bean是否是抽象的、单例的、非懒加载的,如果满足这三个条件,则提供初始化工作
三,满足初始化条件的情况下,还判断了是否是 FactoryBean类型,如果是FactoryBean类型,如果要获取 FactoryBean对象的话需要在 beanName前面加上 “&”,为什么要这么做,可以去看看有关博客---即 BeanFactory和FactoryBean的区别
四,获取bean,这一步是核心,我们进去看看
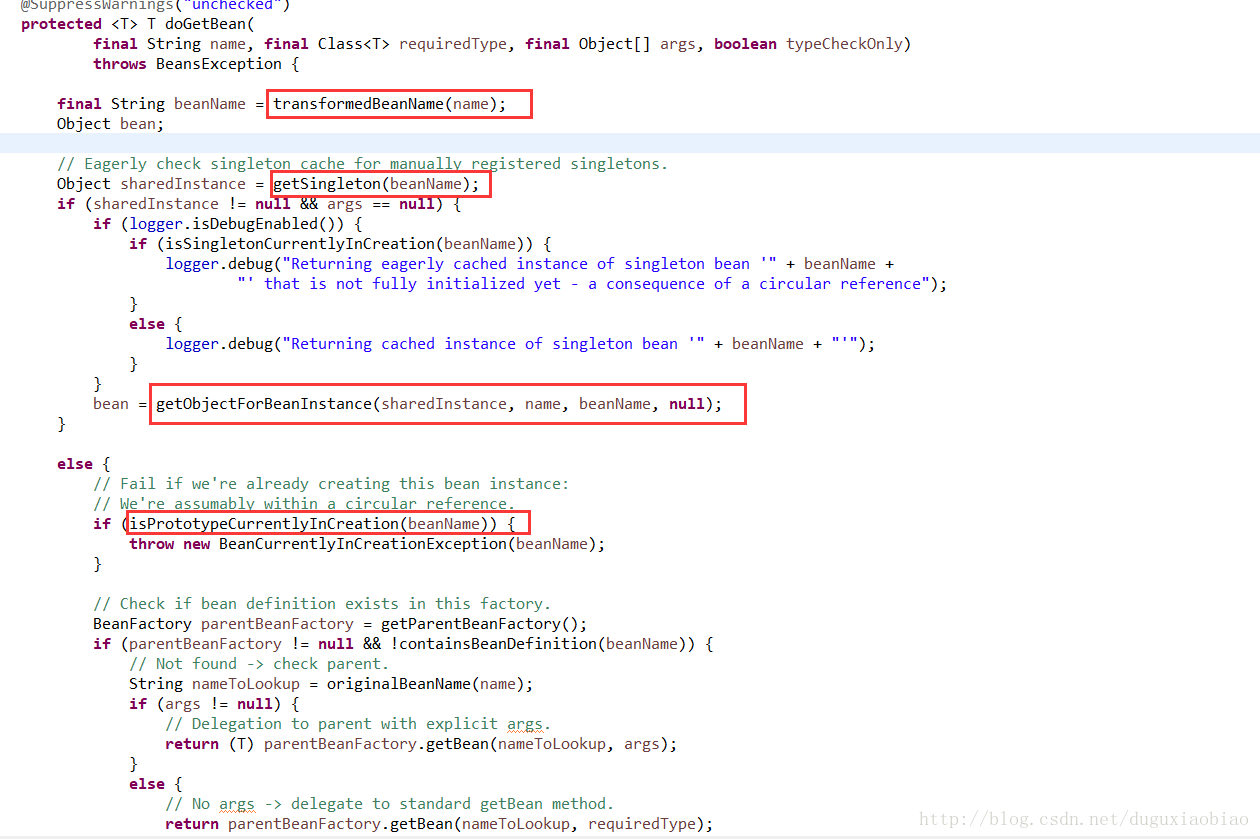
这里的步骤有很多,大致分析下
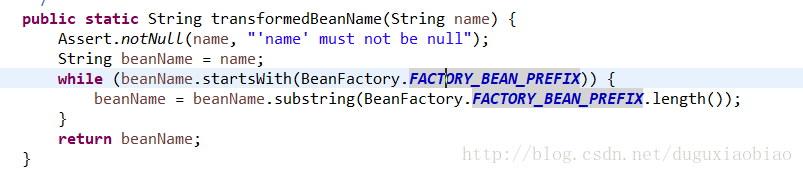
(1)转化beanName,这是什么意思呢,可以通过下图源码中看到如果是 以 “&”开头的要截取掉,这就是当如果我们的bean是FactoryBean类型的bean的情况下做得准备。前面也说了如果是FactoryBean类型的bean获取时需要添加 &。
(2)尝试从缓存中以及singletonFactories中获取 bean对象,我们进入 getSingleton()方法中看看
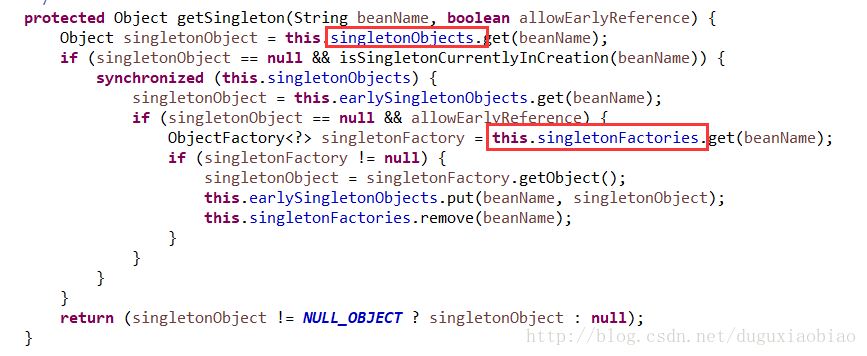
可以很清楚的看到 显示在 单例的缓存中尝试获取,获取不到就可能在FactoryBean的缓存中,再次获取,如果获取到了通过getObject()方法获取对象,获取不到,则返回null
(3)继续看,如果从缓存中获取到了bean,此时的bean还是最原始的bean,需要通过getObjectForBeanInstance()来解析,这方法中包含了多个步骤,主要还是为了 FactoryBean类型的bean类型验证以及解析工作,获取真正我们需要的对象,这里就不细看了,不是很关键
(4)如果在缓存中不存在bean,所以是第一次创建,那么,首先会判断是否存在 循环依赖问题,那么什么是循环依赖呢,简单介绍下,有两个类A和B,如果A中有个属性是B,B中有属性为A,此时相互依赖,当实例化A时,发现存在属性B,此时又需要先实例化B,转到实例化B时,发现有属性A,又转到需要实例化A,这样就会形成一个循环,无法完成实例化任何一个,此时就会抛出异常。这就是 isPrototypeCurrentlyInCreation()方法的作用
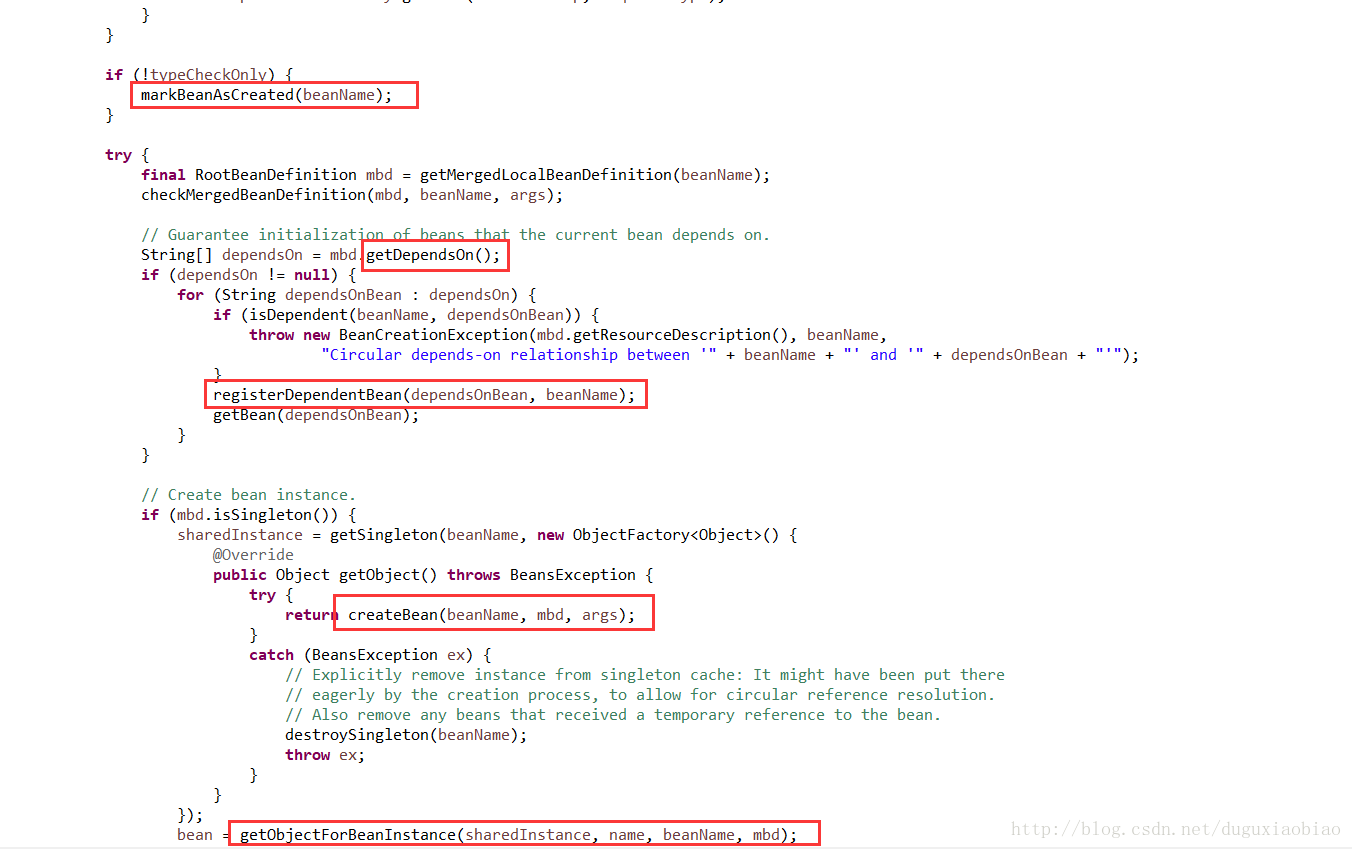
(5)spring实例化bean前有个特点,也是为了解决循环依赖的,那就是在实例化bean前会提前将该对象暴露,添加到一个缓存中,即即将实例化的map中。这就是 markBeanAsCreated()方法的作用
(6)下面就是获取当前要实例化的bean的所有依赖,然后递归创建依赖的bean
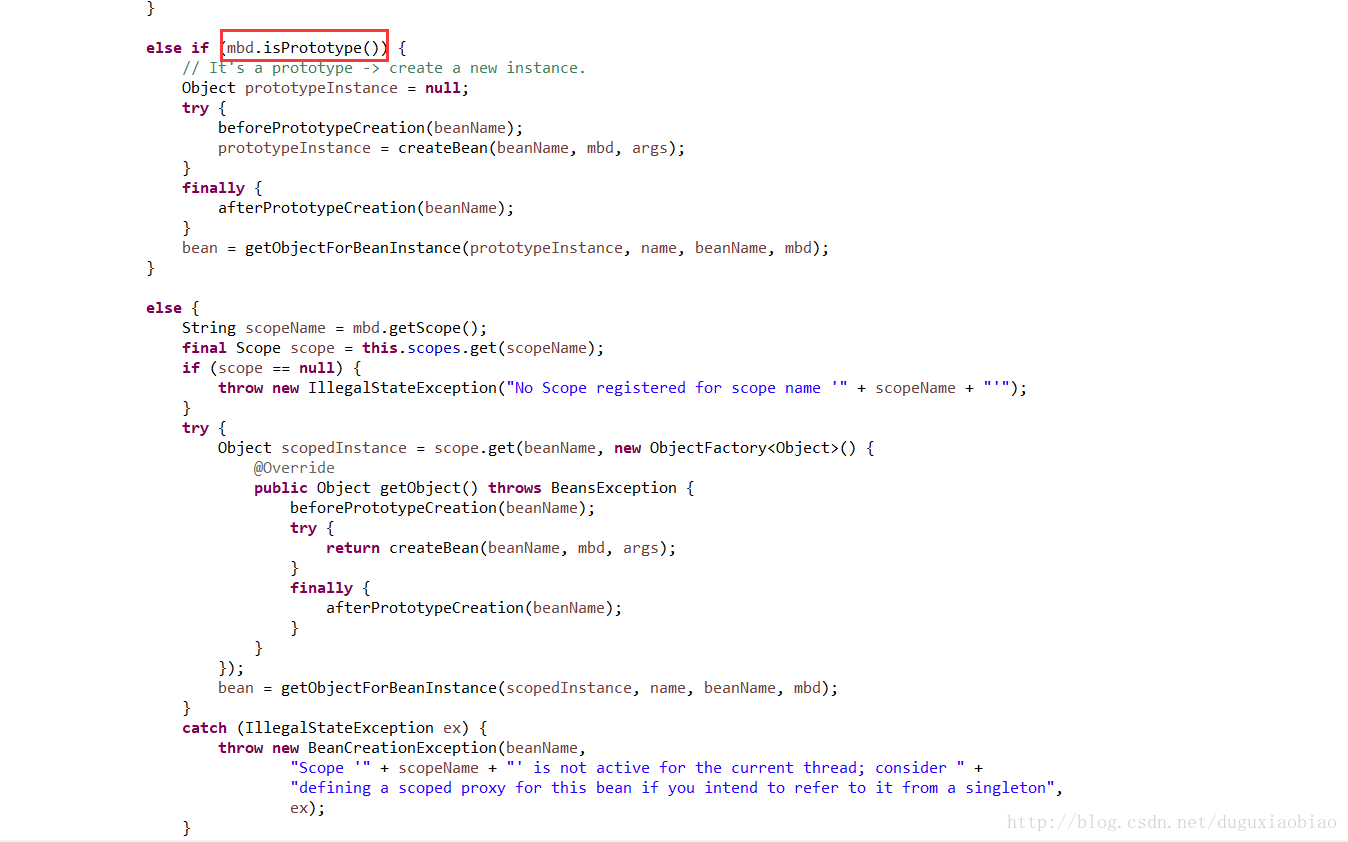
(7)最后,判断是否是单例的,还是prototype的,或者看scope,这里主要介绍单例的bean创建过程
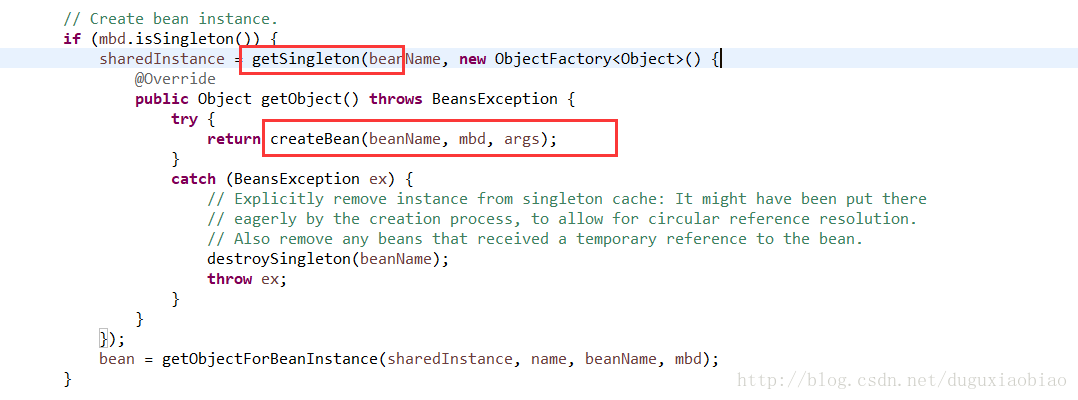
我们进入到 getSingleton()方法中,可以看到
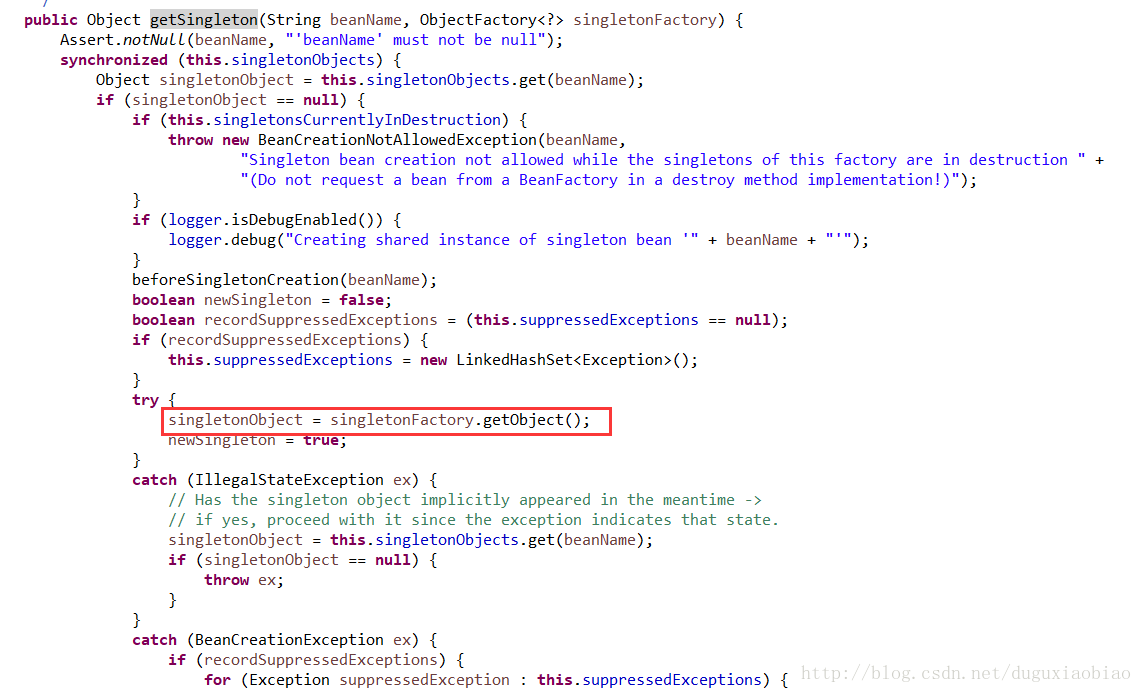
在这个方法里,其实就在创建的之前记录一下,在beforeSingletonCreation()方法中体现,然后就是调用 singletonFacetory的回调方法 getObject(),来创建bean,我们可以去看到该方法中只有一个createBean()方法
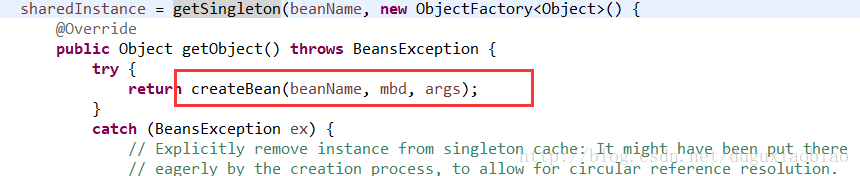
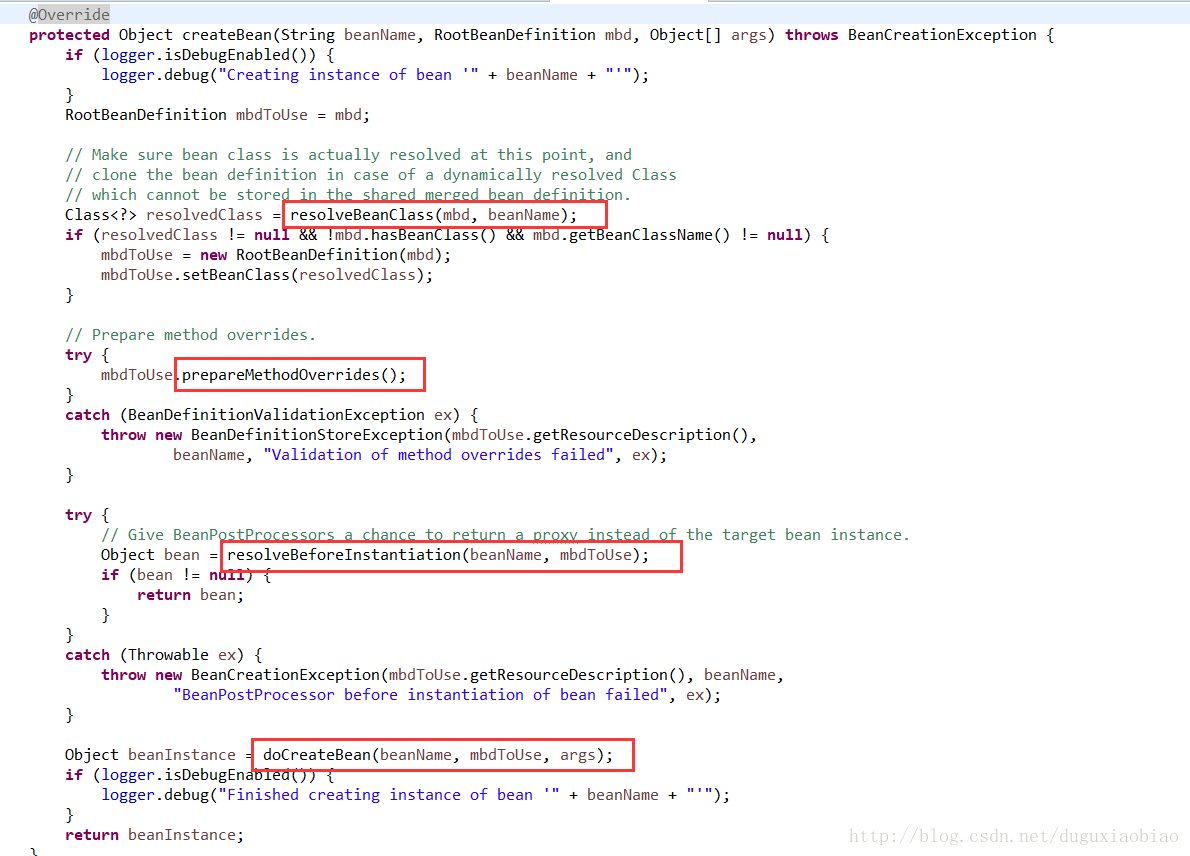
上图中圈了四个方法,分别介绍作用
(1)Class<?> resolvedClass = resolveBeanClass(mbd, beanName);
该方法主要是根据beanName获取对应bean的Class对象
(2)mbdToUse.prepareMethodOverrides();
该方法主要是针对哪些在spring配置中存在lookup-method和replace-method等配置,这两个配置的加载起始就是将配置同意存放在BeanDefiniton中的methodOverrides属性里,而这个函数也是为了针对这两个配置的
(3)Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
这方法主要针对aop存在的,有关aop后面的文章中会介绍到,这里主要说下,我们在创建bean的时候可能不是获取真实的实例的,可能通过aop方式,创建基于jdk或cglib代理的代理对象,这个方法就是如果通过aop创建了一个队里对象的话,就不会继续执行下去,直接返回代理对象,否则继续执行第四步
(4)Object beanInstance = doCreateBean(beanName, mbdToUse, args);
第十,完成刷新过程
最后
以上就是清新黑猫最近收集整理的关于Spring之XML解析的全部内容,更多相关Spring之XML解析内容请搜索靠谱客的其他文章。








发表评论 取消回复