目录
XmlBeanFactory
XmlBeanDefinitionReader
DefaultBeanDefinitionDoucmentReader
doRegisterBeanDefinitions
BeanDefinitionParserDelegate
BeanDefinitionHolder
DefaultListableBeanFactory
早期我们使用Spring框架做开发时,经常会用到xml去配置bean,这些bean首先在xml文件里配置好,然后由Spring管理初始化,我们就可以拿来使用,那Spring框架是如何加载xml里的bean? 本篇文章将解析xml中的bean注册原理。
首先我们可以新建一个maven project,引入bean 的jar包,spring的版本就用5.3.14
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>${spring.version}</version>
</dependency>如果使用ClassPathXmlApplicationContext,那么需要引入spring-context依赖:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>${spring.version}</version>
</dependency>
采用xml的方式配置一个bean, 定义的xml文件中需要包含beans的命名空间声明,其中 "http://www.springframework.org/schema/beans" 是bean默认的命名空间地址,一定不能缺少,否则在getBean的时候会出现报错没有声明beans的问题, Spring-beans.xml文件配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="UserBean" class="com.example.User"></bean>
</beans>
新建一个User类:
package com.example;
public class User {
public void read(){
System.out.println("学习..");
}
}
由于User类已经在xml文件中配置,因此我们可以拿到User这个bean了, 可以使用的XmlBeanFactory来获取bean, 但是现在已经过时, 不推荐使用, XmlBeanFactory继承了DefaultListableBeanFactory类。
package com.example;
import org.springframework.beans.factory.xml.XmlBeanFactory;
import org.springframework.context.ApplicationContext;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.core.io.ClassPathResource;
public class Main {
public static void main(String[] args) {
/*============================================读取xml形式========================================================*/
// 方式一: 采用XmlBeanFactory加载xml配置,不推荐已过时
XmlBeanFactory beanFactory = new XmlBeanFactory(new ClassPathResource("spring-beans.xml"));
User user = beanFactory.getBean("UserBean", User.class);
user.read();
// 方式二: 采用XmlClassPathApplicationContext加载
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring-beans.xml");
User user1 = applicationContext.getBean("UserBean", User.class);
user1.read();
// /*============================================无需xml,注解形式========================================================*/
// // 方式三: 不采用xml形式,采用扫描注解的形式来注册bean, 需要注册配置类BeanConfig
// ApplicationContext annotationConfigApplicationContext = new AnnotationConfigApplicationContext(BeanConfig.class);
// User user2 = annotationConfigApplicationContext.getBean("getUser", User.class);
// user2.read();
//
// // 方式四, 配置扫描包,需要给配置类加上注解@configuration
// ApplicationContext scanApplicationContext = new AnnotationConfigApplicationContext("com.example");
// User user3 = scanApplicationContext.getBean("getUser", User.class);
// user3.read();
}
}
执行查看打印结果:
学习..
学习..
由结果可知,能拿到User类的对象,说明Spring容器启动成功,我们只需要用getBean方法就能拿到指定的bean, 其实这二行代码内部做了非常多的事情,总结下来就是两件事情:
1. 初始化bean工厂,注册bean。
2. 从bean工厂里拿到bean。
两件事情看似简单,实际上包含了很多复杂的逻辑,本篇文章主要以研究第一步看bean工厂是怎么初始化的,而XmlBeanFactory的构造方法里包含了Spring注册bean的所有流程。
XmlBeanFactory
XmlBeanFactory包含了一个final属性XmlBeanDefinitionReader, 该属性用来加载xml文件中配置的所有的bean,其中最核心的方法是this.reader.loadBeanDefinitions(resource), 其实这一行代码里包含了bean注册到Spring里的所有流程。
@Deprecated
public class XmlBeanFactory extends DefaultListableBeanFactory {
private final XmlBeanDefinitionReader reader;
public XmlBeanFactory(Resource resource) throws BeansException {
this(resource, (BeanFactory)null);
}
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
super(parentBeanFactory);
// 初始化XmlBeanDefinitionReader
this.reader = new XmlBeanDefinitionReader(this);
// 注册bean
this.reader.loadBeanDefinitions(resource);
}
}
我们可以看到这里调用了super(parentBeanFactory) ,因为XmlBeanFactory是BeanFactory的子类,因此需要先初始化父类的构造函数,我们可以在DefaultListableBeanFactory的构造方法里看到parentBeanFactory是允许为null的。
public DefaultListableBeanFactory(@Nullable BeanFactory parentBeanFactory) {
super(parentBeanFactory);
this.autowireCandidateResolver = SimpleAutowireCandidateResolver.INSTANCE;
this.resolvableDependencies = new ConcurrentHashMap(16);
// 存放bean的map
this.beanDefinitionMap = new ConcurrentHashMap(256);
this.mergedBeanDefinitionHolders = new ConcurrentHashMap(256);
this.allBeanNamesByType = new ConcurrentHashMap(64);
this.singletonBeanNamesByType = new ConcurrentHashMap(64);
this.beanDefinitionNames = new ArrayList(256);
this.manualSingletonNames = new LinkedHashSet(16);
}
然后DefaultListableBeanFactory执行了一系列的初始化操作,为注册bean做准备工作, 其中包含初始化beanDefinition容器, 我们配置的所有bean最后都是以BeanDefinition的形式存放到该map里。
private final Map<String, BeanDefinition> beanDefinitionMap;
XmlBeanDefinitionReader
接着看XmlBeanDefinitionReader类里的LoadBeanDefinitions方法做了啥事:
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
return this.loadBeanDefinitions(new EncodedResource(resource));
}使用EncodedResource封装了resource对象,该对象时对resouce对象指定编码生成一个encodedResouce对象,doLoadBeanDefinitions()方法执行bean注册。
/**
* Load bean definitions from the specified XML file.
*
* @param encodedResource the resource descriptor for the XML file,
* allowing to specify an encoding to use for parsing the file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
// 将已经加载的资源给获取出来, resourcesCurrentlyBeingLoaded是一个ThreadLocal,封装了set集合
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
// 如果已经存在,那么就不能重新导入
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
// doLoadBeanDefinitions方法是正式注册bean的逻辑
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
} finally {
inputStream.close();
}
} catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
} finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}doLoadBeanDefinitions()方法中主要包含2个步骤,第一步根据inputSource和resource获取到一个Document对象,我们知道xml文档可以解析成一个document树,其中最外层标签就是root元素,子标签就是一个个的叶子node,具体的解析成Document对象的过程不用过于纠结,Spring提供了详细实现, 第二步就是讲document对象注册到Spring容器里,而resouce参数用来选择XmlReaderContext
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
// 将InputSource和编码后的resource解析为document对象。
Document doc = doLoadDocument(inputSource, resource);
// 注册bean
return registerBeanDefinitions(doc, resource);
} catch (BeanDefinitionStoreException ex) {
throw ex;
} catch (SAXParseException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"Line " + ex.getLineNumber() + " in XML document from " + resource + " is invalid", ex);
} catch (SAXException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"XML document from " + resource + " is invalid", ex);
} catch (ParserConfigurationException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Parser configuration exception parsing XML from " + resource, ex);
} catch (IOException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"IOException parsing XML document from " + resource, ex);
} catch (Throwable ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Unexpected exception parsing XML document from " + resource, ex);
}
}接着看registerBeanDefinitions(doc, resource)方法:
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
// 获取到解析document对象里的beanDefinition的工具reader
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
// 注册bean
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
// 返回注册的个数
return getRegistry().getBeanDefinitionCount() - countBefore;
}
此方法主要做了3件事:
- 获取到默认的文档解析器BeanDefinitionDocumentReader。
- registerBeanDefinitions(Document doc, XmlReaderContext readerContext),读取Document对象里的bean, 并实现注册。
- 返回注册成功的bean个数。
我们接着看BeanDefinitionDocumentReader接口里的registerBeanDefinitions(Document doc,XmlReaderContext context)方法的实现。
DefaultBeanDefinitionDoucmentReader
DefaultBeanDefinitionDoucmentReader是BeanDefinitionDocumentReader接口的一个默认实现,简单地讲就是用来解析Document对象里的beanDefinition, 其中regsiterBeanDefinitions(Document doc, XmlReaderContext readerContext)方法是注册bean的入口方法:
@Override
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
Element root = doc.getDocumentElement();
doRegisterBeanDefinitions(root);
}doRegisterBeanDefinitions
protected void doRegisterBeanDefinitions(Element root) {
// Any nested <beans> elements will cause recursion in this method. In
// order to propagate and preserve <beans> default-* attributes correctly,
// keep track of the current (parent) delegate, which may be null. Create
// the new (child) delegate with a reference to the parent for fallback purposes,
// then ultimately reset this.delegate back to its original (parent) reference.
// this behavior emulates a stack of delegates without actually necessitating one.
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
// 如果指定了profile,那么校验
if (this.delegate.isDefaultNamespace(root)) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isInfoEnabled()) {
logger.info("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
// 准备解析
preProcessXml(root);
// 解析beanDefinition
parseBeanDefinitions(root, this.delegate);
// 解析完后
postProcessXml(root);
this.delegate = parent;
}看到了这里,我们就可以发现Spring解析xml中的bean方法和原理,然后该类定义了一个常量
public static final String BEAN_ELEMENT = BeanDefinitionParserDelegate.BEAN_ELEMENT;
BeanDefinitionParserDelegate
BeanDefinitionParseDelegate类里定义很多xml文档里用到的属性,例如bean标签, scope属性,lazy-init等,只要是在bean中用到的属性在BeanDefinitionParseDeletgae类里就有定义, 后续解析的时候会用到该类的定义的属性进行比较,每一个属性对应地做不同的事情:
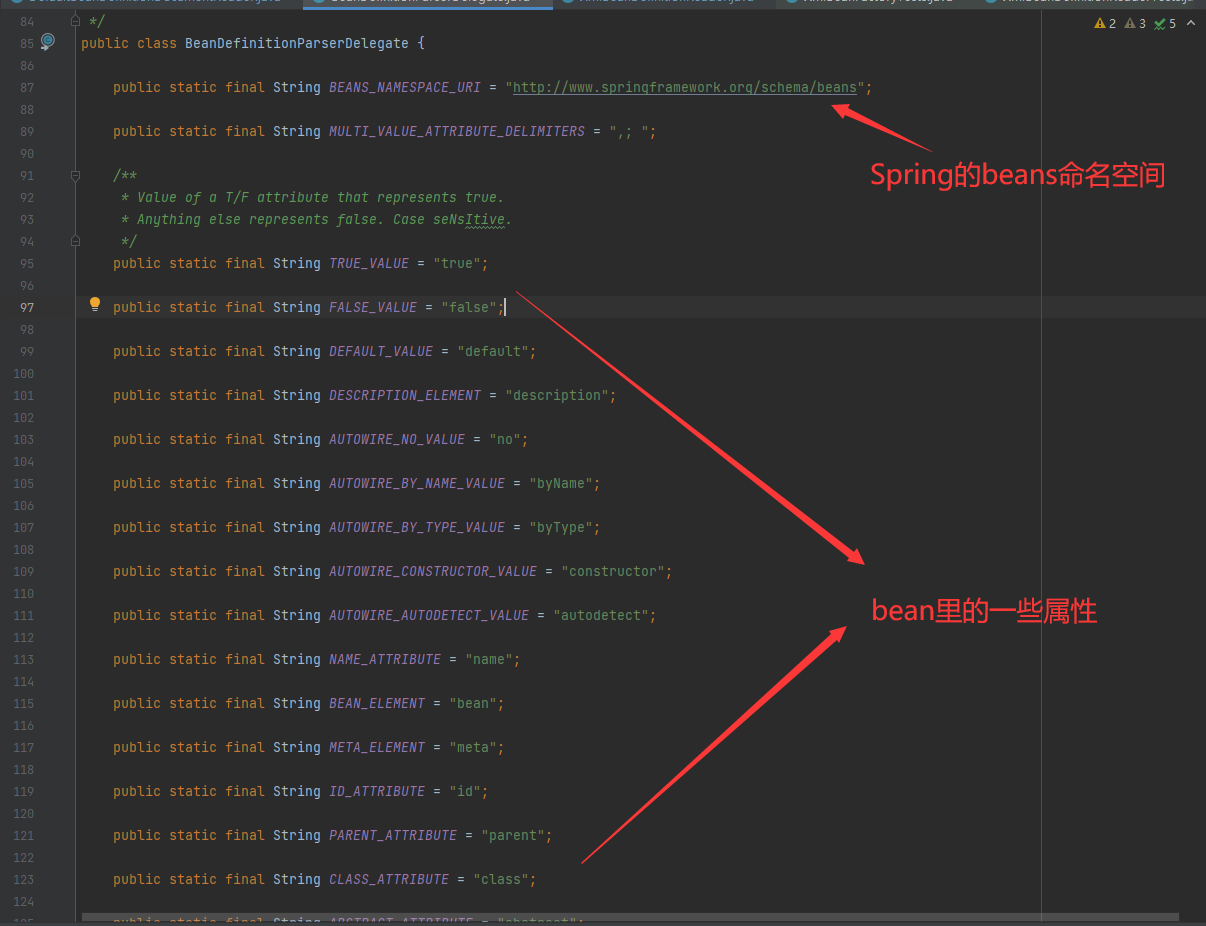
进入到parseBeanDefinitions方法里后,可以发现deletegate支持两种解析方式,一种是默认的namespace的解析,另外一种是自定义的命名空间方式,两者都是在xml文件的标签头部声明的,默认用到的我们可以在xml文件里看到的http://www.springframework.org/schema/beans。
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
else {
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}所以默认会走defaultNameSpace的条件分支,进入到parseDefaultElement方法后,找到 processBeanDefinition方法:
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
// 如果是import形式的注解
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
// 如果给了alias,那么此处需要和将node和alias一起注册
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
// 解析beanDefinition
processBeanDefinition(ele, delegate);
}
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
} protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// Register the final decorated instance.
// 注册bean
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// Send registration event.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
BeanDefinitionHolder
delegate最终把解析到的一个个的bean对象放在BeanDefinitionHolder对象里,BeanDefinitionHolder可以看到我们梦寐以求的beanDefinition属性,这也是最终需要放在beanDefinitionMap里的属性。
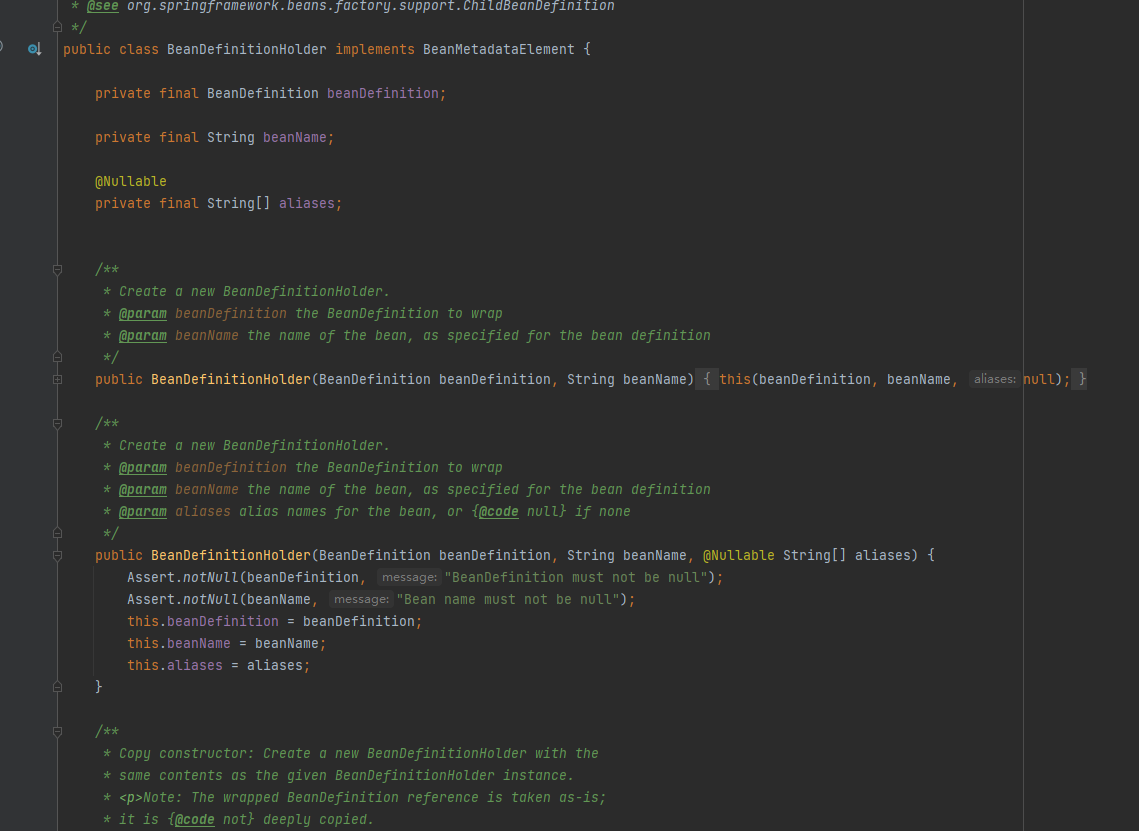
可以在BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry()找到注册bean的逻辑:
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
// 拿到bean的名称
String beanName = definitionHolder.getBeanName();
// 使用BeanDefinitionRegistry注册beanDefinition
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// 如果含有别名,那么也要注册bean的别名
// Register aliases for bean name, if any.
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}看到这里基本可以看清XmlBeanFactory的整个注册Bean逻辑的庐山真面目, 而注册逻辑的实现是在DefaultListableBeanFactory里。
DefaultListableBeanFactory
DefaultListableBeanFactory实现了BeanDefinitionRegistry接口的registerBeanDefinition(String beanName, BeanDefinition beanDefinition)方法, 其中包含了所有的注册逻辑。
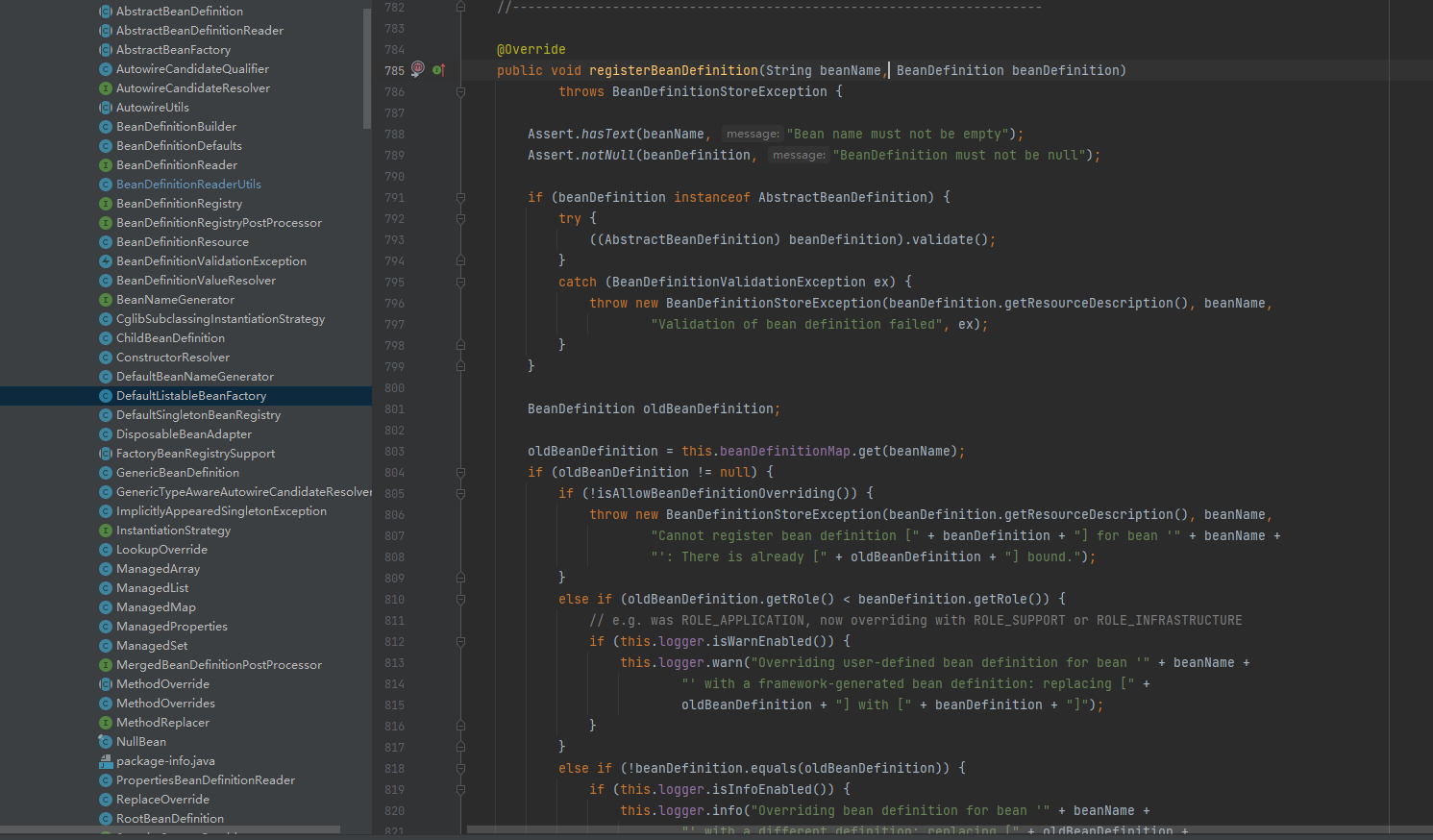 最终将beanName和beanDefinition放入到beanDefinitionMap里, 为后续getBean()方法做流程上的准备。
最终将beanName和beanDefinition放入到beanDefinitionMap里, 为后续getBean()方法做流程上的准备。
最后
以上就是机灵月饼最近收集整理的关于Spring框架源码(一) 如何加载并解析spring.xml配置文件?XmlBeanFactory的全部内容,更多相关Spring框架源码(一)内容请搜索靠谱客的其他文章。








发表评论 取消回复