目录
- LSH简介
- LSH算法过程
LSH简介
LSH全称Locality Sensitive Hashing,即局部敏感度哈希,是一种常用的数据挖掘算法,LSH让海量且高维的数据检索变得高效;普通哈希的目标是避开碰撞,比如Python的dict,Java的HashMap,给一个样本,找一个位置,不同的样本落到不同的位置,只有两个样本相同,才会落到同一位置;而LSH在普通哈希的基础上,弱化了普通哈希避开碰撞的目标,重点是需要保证高维空间相近的样本在低维空间也具有很高的相近概率;
先粗略地描述,假设数据为3张图像,每张图像展开为向量后是4096维,通过哈希可以将每张图像的向量压缩(编码)成128个bit(注意,是位,每个位仅可取0或1);普通哈希只要能够确保图像的编码不碰撞即可,而LSH需要保证两张相似的图像,其128bits的编码也相近;两种哈希的做法可以描述为下图:

在图像检索的工程应用中,人们的想法一般是输入一张图像,用卷积网络提取特征,将特征编码成固定长度的bits(一般是32bits或128bits),数据库中保存的是大量图像以及其经过卷积提取到特征对应的bits,通过对比bits,能够快速返回和输入相似的图像;
比较bits的接近程度使用汉明距离:
A为 10001001;
B为 10110001;
不同的位数为3,汉明距离就是3;汉明距离就是两个码不同的位的个数;
机器最擅长的就是位运算,因此,这比计算特征的欧式距离快很多;
同样的,LSH算法分为两个步骤:
- 1.映射,建立索引;
- 2.查询,query;
LSH属于近邻算法,工程上常用的近邻算法还有KD树(回顾:机器学习笔记本-第三课K近邻算法)
LSH算法过程
首先,把原始的样本映射成长度为
N
N
N的2进制串;其中每个位可以理解为在空间中取了一个超平面进行划分:
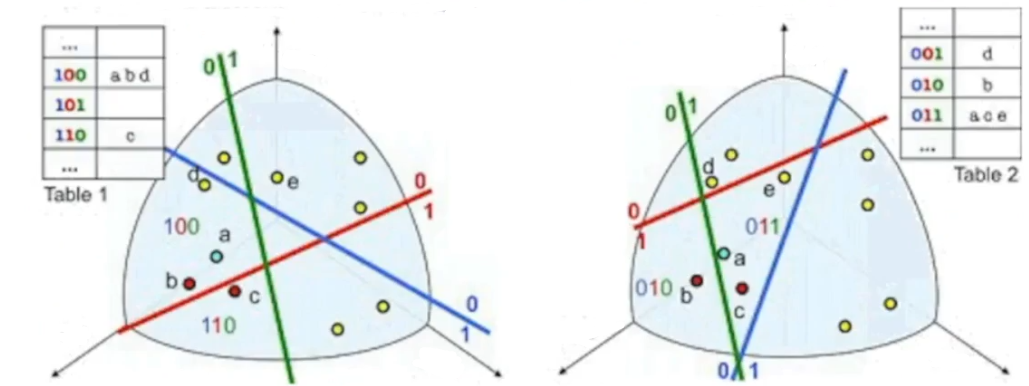
如上图所示,样本有3个特征,以散点形式可视化在三维空间中,现在想要用定长的bits编码,比如长度为3,所以随机生成3个平面(如果样本特征为二维,则划分的平面为直线;如果样本特征维度更高,划分的平面就递进到超平面),样本在平面一侧时,该平面对应的位即记为0,若在另一侧,则记为1;左图和右图分别是两种随机平面下的编码,不同的划分方式会产生不同的编码结果;
可以看出,LSH是允许碰撞的,比如左图样本 a , b , d a,b,d a,b,d均被编码为100;形象地,把Table中的一个个区域称作桶bucket,比如 ( 100 , a , b , d ) (100,a,b,d) (100,a,b,d),100即为桶的编号;
假设现在输入图像,特征对应在空间中的点c,需要返回3张相似图像,编码选择左图,检索过程为:
- 对点c使用同一超平面集合进行编码,得到110;
- 在110对应的桶内查找数据库样本,本例中110没有样本,所以计算其他桶编号与110的汉明距离,先选择最小距离的桶,取出其中的样本,直接与点c计算特征的欧式距离,返回前3个最小欧式距离的样本;
为了提高样本划分的精度,可以增加划分超平面的数量,这会使编号长度增加,对应的就会增加检索的计算时间;同理,如果对划分精度不高,可以减少超平面数量,这样可以增加每个桶中样本的数量,从而降低计算bucket间汉明距离的可能性,直接在桶中计算特征欧式距离。
最后
以上就是高贵胡萝卜最近收集整理的关于其他算法-LSH局部敏感度哈希LSH简介LSH算法过程的全部内容,更多相关其他算法-LSH局部敏感度哈希LSH简介LSH算法过程内容请搜索靠谱客的其他文章。








发表评论 取消回复