一、概述
最近进行人脸识别演示Demo的实现,在测试过程中发现,当底库数量由1W增加至10W级别时,Demo程序的延时非常严重,检查后发现是由于比对函数的耗时增加导致的,为此特对比对函数进行了优化。目前简单使用循环展开+AVX指令加速,速度的提升约有4.5倍。
二、代码展示
#include <immintrin.h>
#define BX 4
#ifdef _MSC_VER /* visual c++ */
# define ALIGN32 __declspec(align(32))
# define ALIGN16 __declspec(align(16))
#else /* gcc or icc */
# define ALIGN32 __attribute__((aligned(32)))
# define ALIGN16 __attribute__((aligned(16)))
#endif
float inline reduce_m128(__m128 r)
{
float ALIGN16 f[4];
_mm_store_ps(f, r); //对齐存储
return (f[0] + f[1]) + (f[2] + f[3]);
}
float inline reduce_m256(__m256 r)
{
__m128 h = _mm256_extractf128_ps(r, 1);
__m128 l = _mm256_extractf128_ps(r, 0);
h = _mm_add_ps(h, l);
return reduce_m128(h);
}
//欧式距离实现
float compare_euclidean_distance(const float* a, const float* b, const int dim)
{
assert(a == nullptr);
assert(b == nullptr);
unsigned int step = dim >> (3 + 2); //dim /(8 * 4)
__m256* one = (__m256*)a;
__m256* two = (__m256*)b;
__m256 result[BX] = { _mm256_setzero_ps() };
for (unsigned int i = 0; i < step; i++)
{
for (unsigned int j = 0; j < BX; j++)
{
__m256 temp = _mm256_sub_ps(one[j + BX * i], two[j + BX * i]);
result[j] = _mm256_fmadd_ps(temp, temp, result[j]);
}
}
for (unsigned int j = 1; j < BX; j++)
{
result[0] = _mm256_add_ps(result[0], result[j]);
}
float r = reduce_m256(result[0]);
for (unsigned int i = (8 * BX * step); i < dim; i++)
{
r += (a[i] - b[i]) * (a[i] - b[i]);
}
return sqrt(r);
}
//余弦相似度
float compare_cosine_distance(const float* a, const float* b, const int dim)
{
assert(a == nullptr);
assert(b == nullptr);
unsigned int step = dim / (8 * BX); //dim /(8 * 4)
__m256* one = (__m256*)a;
__m256* two = (__m256*)b;
__m256 mult_add_ab_m256[BX] = { _mm256_setzero_ps() };
__m256 norm_a_m256[BX] = { _mm256_setzero_ps() };
__m256 norm_b_m256[BX] = { _mm256_setzero_ps()};
for (int i = 0; i < step; i++)
{
for (int j = 0; j < BX; j++)
{
mult_add_ab_m256[j] = _mm256_fmadd_ps(one[j + BX * i], two[j + BX * i], mult_add_ab_m256[j]); //乘加
norm_a_m256[j] = _mm256_fmadd_ps(one[j + BX * i], one[j + BX * i], norm_a_m256[j]); //乘加
norm_b_m256[j] = _mm256_fmadd_ps(two[j + BX * i], two[j + BX * i], norm_b_m256[j]); //乘加
}
}
for (int j = 1; j < BX; j++)
{
mult_add_ab_m256[0] = _mm256_add_ps(mult_add_ab_m256[0], mult_add_ab_m256[j]);
norm_a_m256[0] = _mm256_add_ps(norm_a_m256[0], norm_a_m256[j]);
norm_b_m256[0] = _mm256_add_ps(norm_b_m256[0], norm_b_m256[j]);
}
float mult_add_ab = reduce_m256(mult_add_ab_m256[0]);
float norm_a = reduce_m256(norm_a_m256[0]);
float norm_b = reduce_m256(norm_b_m256[0]);
for (int i = (8 *BX * step); i < dim; i++)
{
mult_add_ab += a[i] * b[i];
norm_a += a[i] * a[i];
norm_b += b[i] * b[i];
}
return mult_add_ab / sqrt(norm_a * norm_b) + FLT_MIN;
}
三、结果展示
测试环境:QT 底库:10W 特征:512维
硬件为:笔记本I7-9750H CPU@2.6GHz 2.59GHz
(1)未优化结果截图
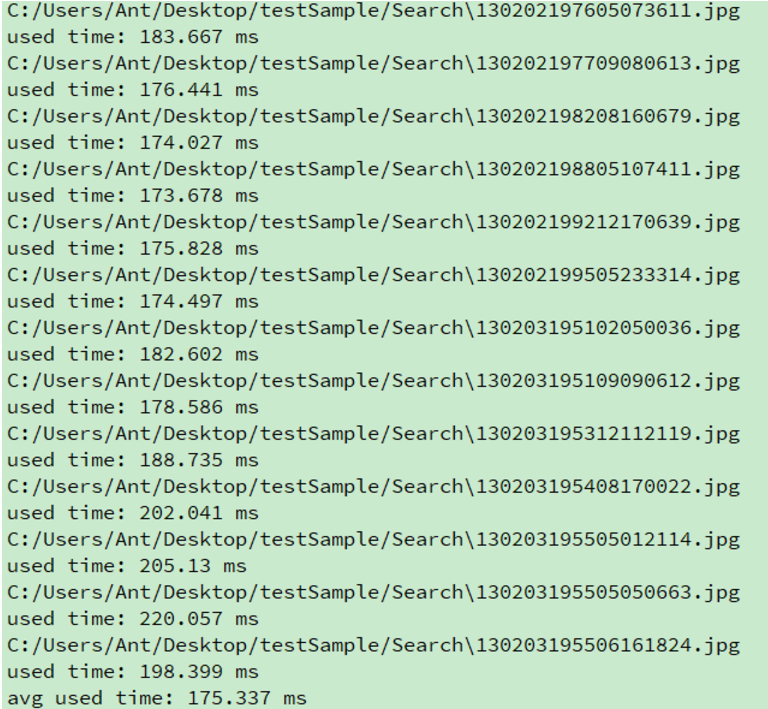 由上图可知,平均耗时约为175.337ms。
由上图可知,平均耗时约为175.337ms。
(2)使用以上代码优化后
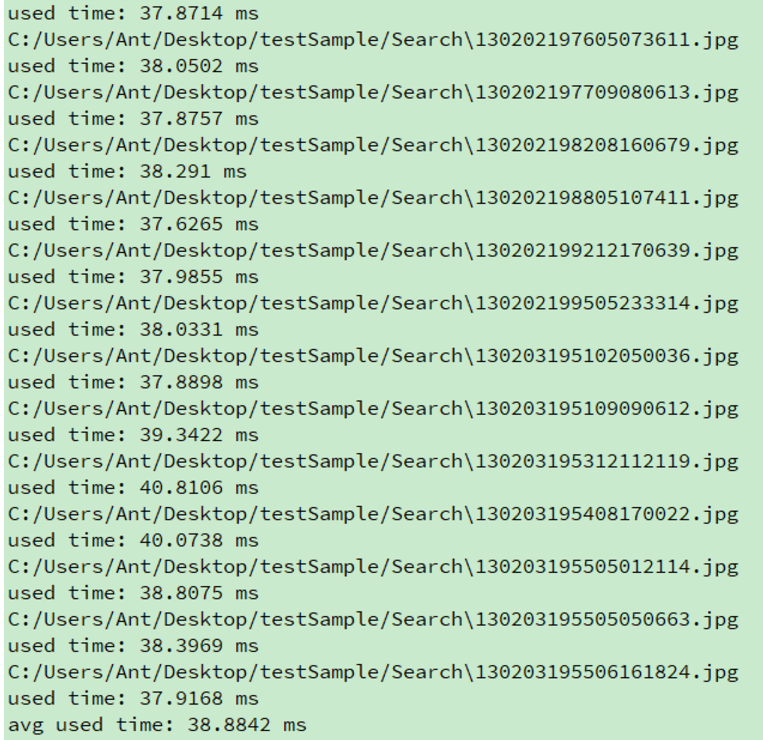
由上图可知,平均执行时间为38.8842ms。
加速比约为:4.5倍
四、小结
(1) 本次实验仅仅在Windows下完成,Linux和Arm端的优化,后续会继续优化并进行详细测试。
(2) 4.5倍的提升远不是极限,还有很多的优化策略没有应用。由于本人也刚刚开始学习,没有添加上,同时本人也尝试了openmp的并行优化,但可能本人的水平有限,在windows下进行粗粒度并行优化,并没有带来速度的提升,反而耗时比没优化前略有增加,后续本人将继续尝试如何提升,并及时和大家分享。
最后
以上就是和谐丝袜最近收集整理的关于人脸识别系列之特征比对优化记录(一)的全部内容,更多相关人脸识别系列之特征比对优化记录(一)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复