这块,也可以参考facebook的https://www.jiqizhixin.com/articles/under-the-hood-multilingual-embeddings
关于词向量对齐的历史方法,可以看这里:https://blog.csdn.net/xacecaSK2/article/details/102096256
1. 前言
在公司业务需求背景下,我需要解决来源不同语言语料的NLP问题如多语言(具体是中英日韩)情感分析,翻译(n种语言翻译成英语)。以前的时候总是为每总语言对应训练一个或者多个模型,但是这样难免效率低而且浪费资源。我联想起Alexis等人在18年《Word translation without parallel data》无监督单词翻译一文,特别是里面一句Mikolov first noticed that continuous word embedding spaces exhibit similar structures across languages, even when considering distant language pairs like English and Vietnamese,也就是即使越南语和英语两种差距很远的语言,它们的词向量亦有相似的地方。于是尝试多种预料放在一起共同训练,结合论文词向量对齐方法,最终也拿到不错的结果,在数据多接近一倍的情况下,情感分析跟最好的单语言模型只相差3个百分点。在翻译上,仅需要一个模型就可以翻译翻译多种语言为英语,对于一些港式夹杂英文的中文,例如“我先book个酒店,然后做个gym,再做个facial,今晚还有时间的话,我会send个email通知你。”翻译为"I will book a hotel first, then make a gym and have a facial. If time tonight, I will send you an email to inform you."这些细节在后面我会常说。由于水平限制,主要介绍Word translation without parallel data给我们带来的有监督,无监督(主要)以及CSLS方法解决K近邻问题。最后说一说我自己的一些通过词向量对齐来优化的实践和总结。
2. 通过监督学习对齐
2.1 语言本身的相似性
在Mikolvo的实验中,通过他自己提出的Skip-gram和CBOW模型,训练出多种语言的embedding。在他的论文《Exploiting Similarities among Languages for Machine Translation》中,他以英语和西班牙语为例(下图),左边是英语的一些词向量分布,右边是西班牙语的。这些词向量都通过PCA映射到二维平面上。,并且手动通过一系列的仿射变换:旋转、平移和缩放给读者观察他们之间的相似性。
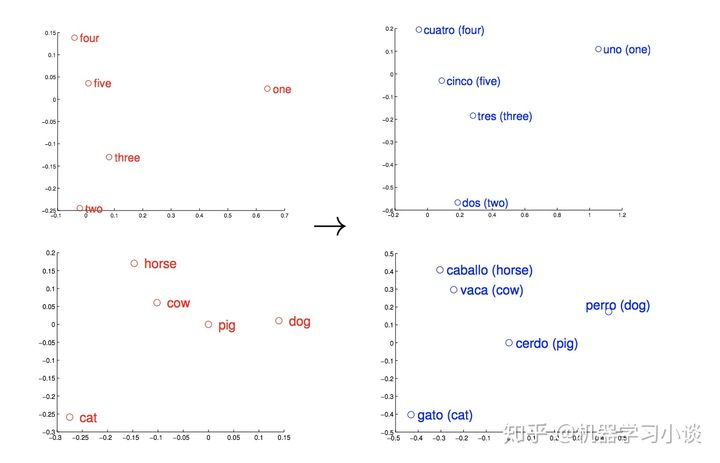
英文-西班牙文PCA映射
因为任何语言,只要在这个星球上,因为都有着非常相似的背景。无论什么语言,在大量样本的条件下,例如猫和狗最容易出现在动物类的语料中,因此它们之间的夹角很小。上图中的one与uno都语其他数字相差很远,甚至看看下图你发现中文的 “一” 跟one也是一样,可能是因为1在所有的语言中,使用频率要比其他数字高得多,上下文跟各种词的接触也很广,所以造成其看起来比较远离数字群体的现象。正是因为语言的相似性让Mikolvo的工作可以继续进行。 下面给出两张中文和英文的,不过融合在一起,可以看出 “数字” 向量(图左)比较相似而 “动物” 向量(图右)有一些差异。
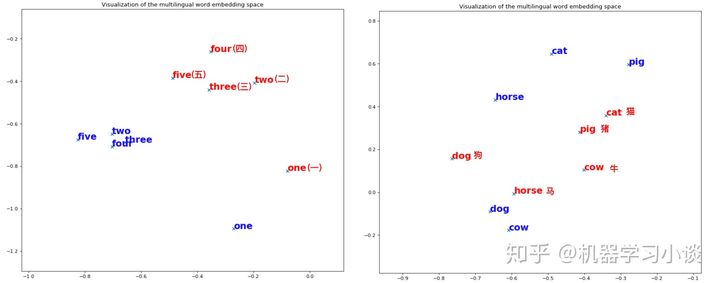
中文-英文PCA映射
2.2 Procrustes analysis(普氏分析)
Mikolov的方法通过找到一个矩阵W,实现一组语言向量到另外的一组语言向量的“对齐”。通过使用一个小词典(5000对英语-西班牙语{xi,yi}i∈[1,n],如下进行学习W:
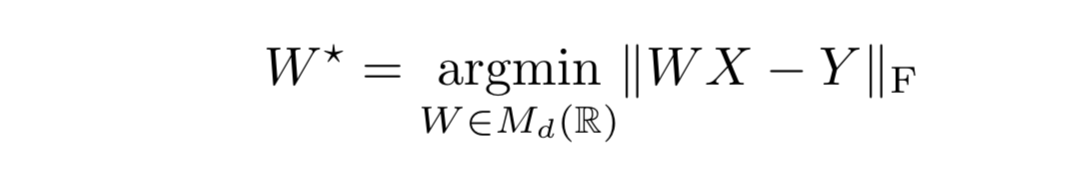
d是词向量的维度,Md(R)是一个d×d的实数矩阵。X和Y是两个d×n的对齐矩阵(每一列是一个词向量),分别代表两个词典。||•||F是弗罗贝尼乌斯范数。上面等式可以归结为普氏分析问题,只需要对Y•XT进行奇异值分解,如下:
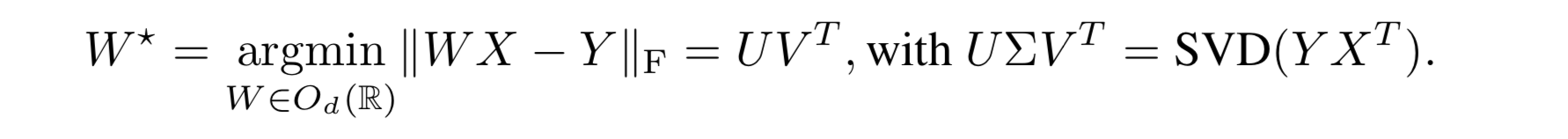
下面是基于欧几里德范数(L2范数)下的证明:

由于S是正交矩阵,当S为单位阵E时取得最大值,有:
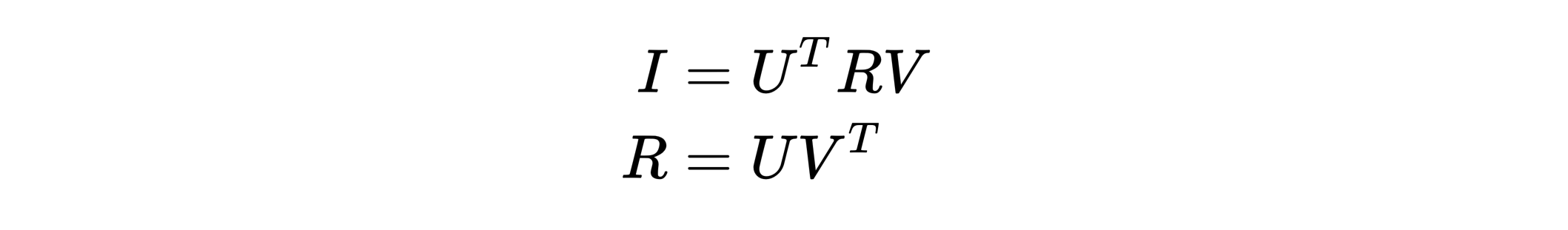
有了理论支持,实践中对齐过程总结步骤如下:
1.通过SVD求解W'。
2.更新X=W'X,计算||W'X-Y||F。
3.重复上述两个步骤,直到达到指定循环次数或者L2范数值收敛到一定阀值。
3. 通过无监督学习对齐
大部分通过无监督学习跨语言词嵌入的方法都是分两步走的,在引入种子词典以后需要用有监督的方式学习最终嵌入
同时,第一步是使用单语词嵌入训练方法获得源语言和目标语言的词嵌入
3.1 域对抗训练
通过上面的监督学习方式,我们可以通过求出W矩阵实现对齐,在无监督方法也是如此。域对抗参考自Ganin et al.(2016)的文章《Analysis of Representations for Domain Adaptation》,分析领域自适应的表示层。首先Domain Adaptation基本思想是既然源域和目标域数据分布不一样,那么就把数据都映射到一个特征空间中,在特征空间中找一个度量准则,使得源域和目标域数据的特征分布尽量接近,于是基于源域数据特征训练的判别器,就可以用到目标域数据上。在本文就是把X通过映射W投影到Y上。设X={x1,x2,...,xn}和Y={y1,y2,...,ym}分别是source和target的词向量集合,现在我们需要训练一个判别器来区别来自WX={Wx1,Wx2,...,Wxn}和Y的随机采样。W则通过训练,使得WX跟Y尽量地相似而至判别器无法区别它们。算法的目的都可以看做是学习一个线性变换来最小化目标分布和源分布之间的散度
判别器的损失函数:
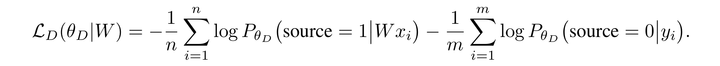
生成器的损失函数:
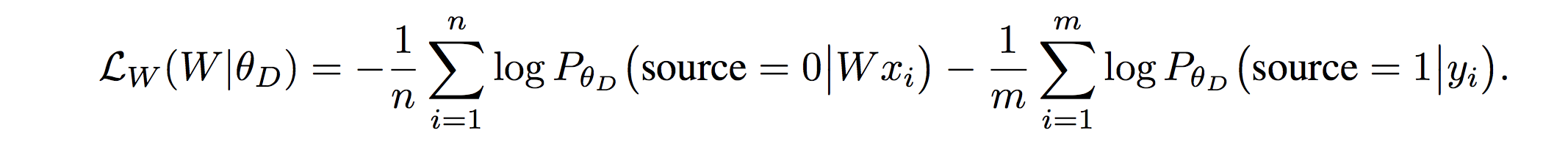
3.2 GAN结构
论文作者采用fastText提供的词向量作为训练样本,其维度跟维基百科语料一致,都是300维。因此,W矩阵的维度也是300*300。单词全部采取小写,同时为了加快实验脚步,只选用了20万个常用的单词加入训练。
在分辨器那边,作者采用了两层且每层有2048个神经单元的多层感知器,输入层0.1的dropout噪音,输出则采用leaky-Relu作为激活函数。选取SGD优化算法,batch大小为32,学习率0.1并且加上0.95的衰减率。不过作者后来在(Luong et al.,2013)的研究发现,采用高频词的效果要比低频词的效果要好,最终作者只选取了只有50000个高频词,并且他发现不比采用所有20万个单词的效果要差,可以忽略不计。
到这里,得到的是粗略的翻译矩阵
3.3 通过Procrustes再优化
尽管只用无监督方法得到不错的效果,但是依旧追及不上监督方式。细细分析一下,在最初的对抗训练中,生成器对所有的单词都一视同仁地进行对齐,这样可能存在一些高频词更新梯度比低频词还要低的情况。至于为什么选择高频词,这里插入我自己的一些理解。 第一个优点是高频词的有较高的支持度,尽量将高频词对齐,对后续使用词向量作为特征有着更好的效果。 第二个优点是我认为论文没有提及的,就是越高频的词组,它们之间夹角就可能越大,这里用可能是表示概率相对于低频词组更大。其实我用了一个自己的优化方法,就是尽量采用秩高的词向量矩阵。我不肯定跟作者论文中提及的Stiefel流形是不是同一概念,在维基百科中对Stiefel描述如下:
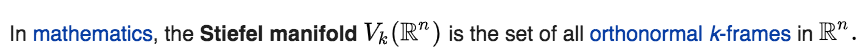
由于自己的能力有限,未能写出数学上的证明,不过我可以伪数学的形式描述一下: 当词向量矩阵的秩高的时候,也就是有多组正交的词向量,这些词向量经过归一化可以作为这些词向量所在的向量空间的基。而对正交向量的调整会比共面的向量更有作用,因为共面向量可能不会有大幅度提升,因为该面上可能存在已经对齐好的向量,强行对齐只会是此消彼长,而非共面向量则有着更大的对齐空间(正交的时候,向量的关系最小,不是相反那种,可以加速对齐不同的词向量簇而不是相近的词向量簇),可以加速Procrustes的收敛,当然这些时间上的收获不是100%的,毕竟需要付出一定的时间到收集相互垂直的词向量表。
总结来说:使用得到的粗略翻译举证可以构造一个小的高频词双语词典,然后对这个词典剪枝,仅保留那些满足双向翻译性质的词对。通过求解正交普氏问题,可学到在这些高频词对上可用的新的翻译矩阵Ω,新的Ω会得到新的种子词对,新的种子词对也会得到新的Ω,这个方法要求作为锚点的高频翻译对要尽可能可靠
3.4 CSLS(CROSS-DOMAIN SIMILARITY LOCAL SCALING)跨领域相似度局部放缩
为了产生可靠的配对词典,目标词向量与源词向量的“距离”越近越好。不过,作者发现了了一个最近邻不对称的问题。可以想象,y是x的K-NN(k个最近邻)并不意味着x也是y的K-NN,很容易举一个英文向中文对齐的例子,“one“应该向中文的“一”对齐。W * Vone可能是“一”的k个最近邻居之一,但是W * Vone并不一定跟“一”最相近,因为“个”,“条”,“年”等等即“一个”、“一条”、“一年”等词比“一”等词更可能离W*Vone近,更可能靠的更紧。因此,这一种叫hubness的问题,即W * Vone向靠得更近的那组词向量(“一个”、“一条”等)优化比向“一“靠近的loss更少。在我看来,这是一种陷入局部最小的现象。
当然,这种现象也出现在其他的领域,从CV问题((Jegou et al., 2010)到词翻译(Dinu et al., 2015),当然有些问题已被解决,有些则遗留在谱聚类算法中。 在作者的解决方案中,作者的主要思路是实现一种惩罚措施,用余弦相似度衡量高维度上的“距离”。NT(Wx)这个标记是指Wx在target词向量中k个最近邻,类似,NS(y)则是指y中source词向量中的k个最近邻居。这里k作者实验了1,5,10,结果都十分平稳,不过作者最后选择了10。
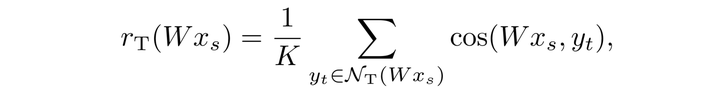
其中,cos是余弦函数,计算两高维度向量的夹角,r函数是一个惩罚项目,其值是所有最近邻的平均余弦相似度。下面是CSLS表达式:
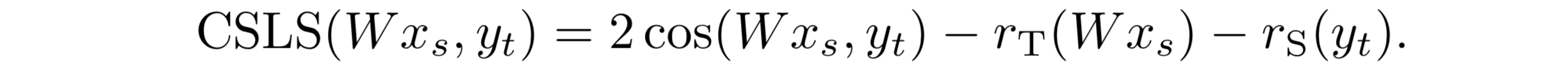
集中度(hubness),是在高维空间中观察到的一种现象,即某些点可能是很多其它点的最近邻居。这种现象会影响跨语言词向量模型的效果
总体来说:CSLS的作用是在高密度区域扩张,在低密度区域收缩,这样可以算出更准确的最邻近点,因此可以解决高维空间的中枢点问题。
3.5 正交性
正交矩阵每行或者每列都正交,并且都是单位向量。作者提及使用正交矩阵,可以保证了多语言词向量的质量,因为两正交矩阵的乘积得单位矩阵(WT*W=I),维持了欧几里德距离不变。参考归一化,用正交矩阵训练还可以保持训练的稳定。作者从(Cisse等人的论文Parseval Networks: Improving Robustness to Adversarial Examples)得出一个既可以保持正交性又简单的更新方法:
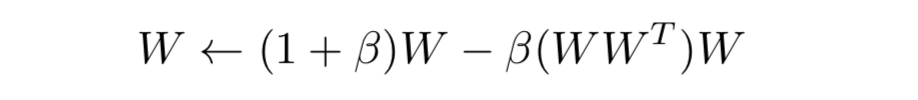
公式一
上面方法来自一种叫斯蒂弗尔流形的正交矩阵优化方法。放心,百度百科暂时没有该词条。这种简单的一阶集合方法可以在使用梯度更新的时候又保持这正交的性质。
这种方法的关键是,为了保持流形的正交性质,每次进行梯度更新之后,需要做一定的“回滚”操作,在Absil的论文中(准确来说是一本书),这些操作作用在一部分的子流形上,譬如基于凯利变换的斯蒂弗尔流形。不过,这种方法的缺点是在反向传播的过程中不可直接计算。作者用了一种近似的办法克服这种困难。
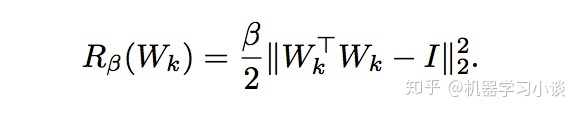
这种方法参考自(Kovaceviˇc&Chebira´,2008)
只需要在每次梯度下降后优化Rβ(Wk),直到其收敛,这能确保流形的性质不变,也就是正交性不变。当然这种计算也是很昂贵,而且很容易造成刚刚梯度更新过的参数远离原来的更新轨道方向。这里Rα(Wk)的梯度是∇WkRβ(Wk) = β(Wk*Wk^T − I)Wk.因此有了上面的公式一。
具体更新算法伪代码如下:

补充一下作者的一些细节: 由于一次性更新整个W矩阵非常吃力,效率是O(K^2),因此作者提出了抽样更新法。通过从W随机抽取行来更新,可以使效率降低到O(S^2),当然S<K。当然这里S的抽样是由Drineas等人在Fast monte carlo algorithms for matrices i: Approximating matrix multiplication提出的一种基于蒙特卡洛模拟方法,这篇论文的数学公式与推导太多,不再展开。
无监督方法的局限性
[Søgaard2018]给出了MUSE的三个局限性
1.MUSE不能保证对所有语言对都能给出好的对齐结果。例如如果一个语言词形态丰富,而且是dependency-marking(这个语言学术语实在找不到翻译了)时,效果就不好
2.MUSE不能很好对齐来自不同领域的词
3.MUSE不能很好对齐使用不同算法训练出的词向量
例如,MUSE可以近乎完美地对齐用fasttext在维基上训出的英语-西班牙语词向量,但是不能很好对齐如下几种词向量:1. 英语-爱沙尼亚语 2. 使用医学语料训练出的英语词向量和使用维基训出的西班牙语词向量
此外,对一些比较难的语言对,MUSE有时可以学出可用的映射,但是有时候不行
无监督方法的效果还受其核心成分GAN能力的制约。一方面,如前所述,GAN有模型崩塌现象,另一方面,有时候向量空间之间不存在线性映射关系。最后,[Søgaard2018]指出使用不同算法在不同语言上训出的嵌入基本很难对齐
4 应用与总结
词向量对齐我主要用于两个项目,一个是基于自注意力的简单情感分析项目,一个是基于TF提供的nmt自然语言翻译机项目做中对英的翻译(后者还在学习中因此暂时不展示了)。
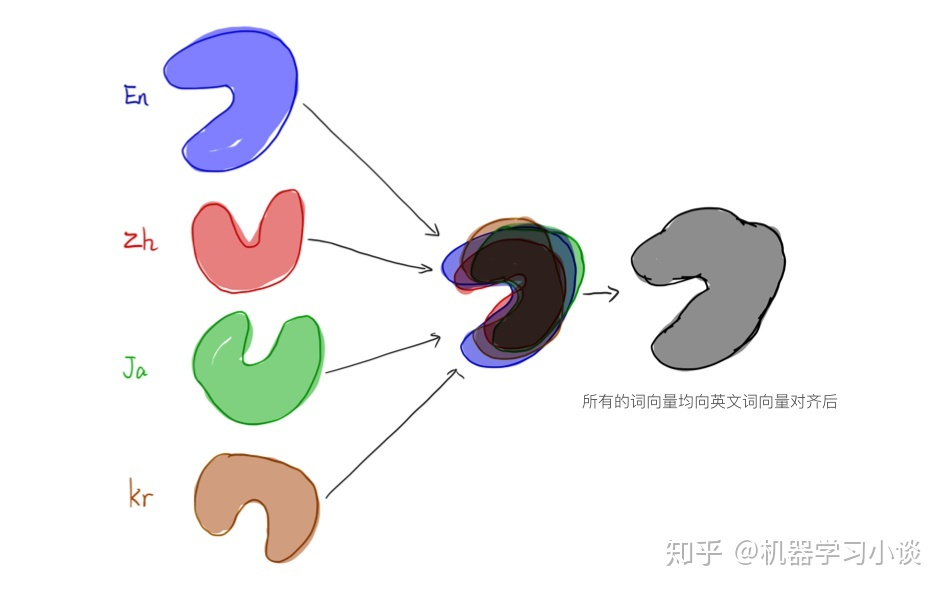
第一个项目是一个多语言的情感分析,网络上的主流做法是一种语言对应一个模型。在这里,会有两种问题是,一个是某些语言的语料十分缺少,另外一个是正负样本比例失衡的问题。譬如日语的评论,可能是日本人比较含蓄的原因,日语的评论好评占最多,其次到中文评论。也有可能是买家害怕卖家的报复不敢差评。这次我采用的做法是,把其余三种语种的词向量均向英语语种对齐,当然也可以向中文或者其他语言对齐。不过这次是因为英语数据量比较大,采用了以英语为基准。融合后,词向量数量是前面所有语种词向量之和,当然这里也可以优化,把余弦距离低于一定阀值的两个词向量相互合并取平均或者仅仅保留其中一个,不过由于项目时间原因,最终没有来得及进一步试验。
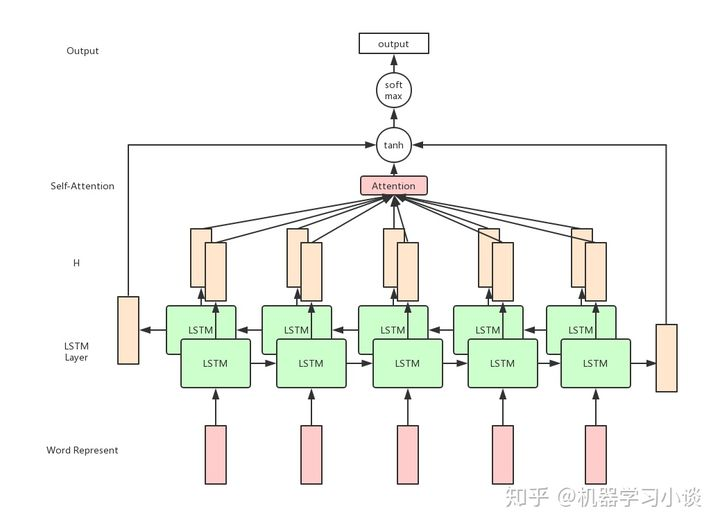
我的模型是bilstm+self_attention,attention参考Attention is What you need里面的单头或者多头注意力结构,采用了8个注意力头,attention层参考了Yequan Wang的Attention-based LSTM for Aspect-level Sentiment Classification的模型,两层bi-LSTM,一共约710万个参数,整个网络参数图例结构如下:
下面是关于数据的统计:
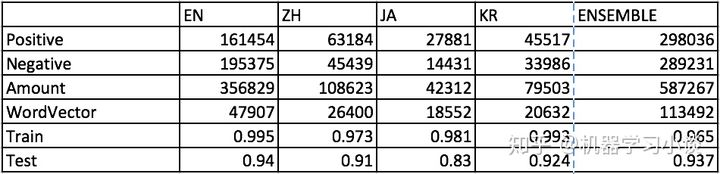
第二列到最后一列分别指英文、中文、日文、韩文和融合语言,均使用同一模型进行训练。 最后两行是训练成绩,其中日文那一块交叉验证出现明显的问题,我没能查出是不是特征工程造成的错误,也可能正负样本相差太大造成的。中日韩数据集相对于英语比较少,所以它们收敛得比较快,但是也许正是这个原因,模型没能更充分地学会情感的判别。英语的模型可能已经overfit了,不过最欣慰的是,融合后的数据,并没有因为语种的不同,使得准确率变差。
词语级别的对齐确实是一种很有效的优化方法,当一种语料的数据较少的时候,可以借助其他语料进行数据增强。当词语级别对齐后,神经网络所要学习的,就是语法上的不同了。相比词语数量级别,语法学习的难度则少得多。词向量对齐确实是一项非常有创意有突破性的想法,由于本人的水平有限,不足之处,敬请指出,如有错误的地方,请轻虐~
5 参考
Alexis Conneau, Guillaume Lample, Marc'Aurelio Ranzato, Ludovic Denoyer, Hervé Jégou. Word Translation Without Parallel Data
T. Mikolov, Q. V Le, I. Sutskever.Exploiting similarities among languages for machine translation
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention Is All You Need
Yequan Wang and Minlie Huang and Li Zhao* and Xiaoyan Zhu. Attention-based LSTM for Aspect-level Sentiment Classification
Moustapha Cisse, Piotr Bojanowski, Edouard Grave, Yann Dauphin, Nicolas Usunier. Parseval Networks: Improving Robustness to Adversarial Examples
Thang Luong, Eugene Brevdo, Rui Zhao (Google Research Blogpost, Github)Neural Machine Translation
[Søgaard2018]: Anders Søgaard, Sebastian Ruder, and Ivan Vulić. 2018. On the limitations of unsupervised bilingual dictionary induction. In Proc. of Association for Computational Linguistics (ACL 2018), pages 778–788.
补充一份有用的数据及工具:
单语资源
多语分布式词向量,以及40种语言的wiki dump(需科学上网,而且词向量最近一次更新是在2013年了)
23种语言的维基语料,XML格式
英、法、德、意语单语语料(10亿单词量级)
fastText单语词向量(294种语言)
跨语种数据
BabelNet,覆盖了284种语言的双语百科词典,同时具有一定的语义网功能
PanLex,一个庞大的词典数据库,同时也提供一些词语翻译功能。号称覆盖5700种语言,但是网站内容纯度略堪忧
OPUS,开放的平行语料库
23种语言,253个语言对的维基数据。注意文档之间并非严格对齐的翻译关系,只是原书提到的“可比较数据”
跨语言词向量模型
大部分都是给出训练用的代码。比较有名的包括
VecMap (ACL 2018)、Ruder的扩展版本,基于隐变量
对78种语言fastText词向量的对齐工作,其中英语是中枢语言 (ICLR 2017)
无监督方法的代表MUSE
BiSkip
BilBOWA
(本小节没有列出原书给出的全部工作)
评估工具
SemEval 2017,基于词向量相似度
ACL 2016的工作,对内涵评估和外延评估都有涉及
85种语言的treebank
基于跨语言词向量的无监督机器翻译:UNdreaMT (ICLR 2018)、Monoses (EMNLP 2018)、FAIR的无监督机器翻译工作 (EMNLP 2018)
此外,可以使用前面提供的跨语词典或机器翻译工具(如Google Translate)来评估学到的双语词典的质量
目前重建巴别塔最大的阻碍还是缺少跨语系语言的双语评估数据
最后
以上就是顺心路灯最近收集整理的关于系统学习NLP(三十)--词向量对齐的全部内容,更多相关系统学习NLP(三十)--词向量对齐内容请搜索靠谱客的其他文章。








发表评论 取消回复